E.C 古典的 ML ロードマップ
データセットが小さい、特徴量がはっきりしている、重いモデルを試す前に強いベースラインがほしい。そんなときに使う選択モジュールです。
まずベースラインの地図を見る
Section titled “まずベースラインの地図を見る”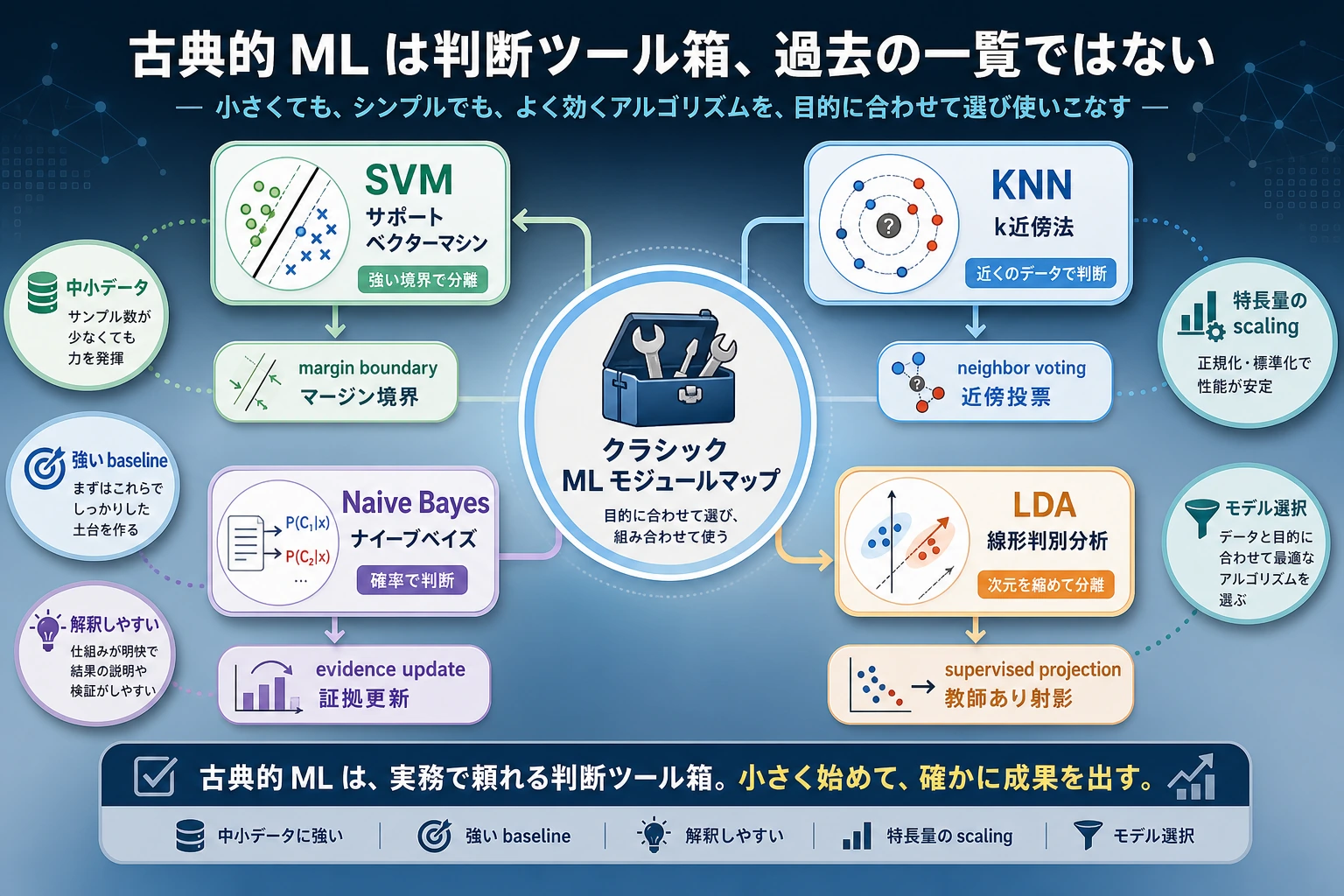
古典的 ML は、「この問題はシンプルな特徴量だけで解けるのか」を先に確かめる助けになります。
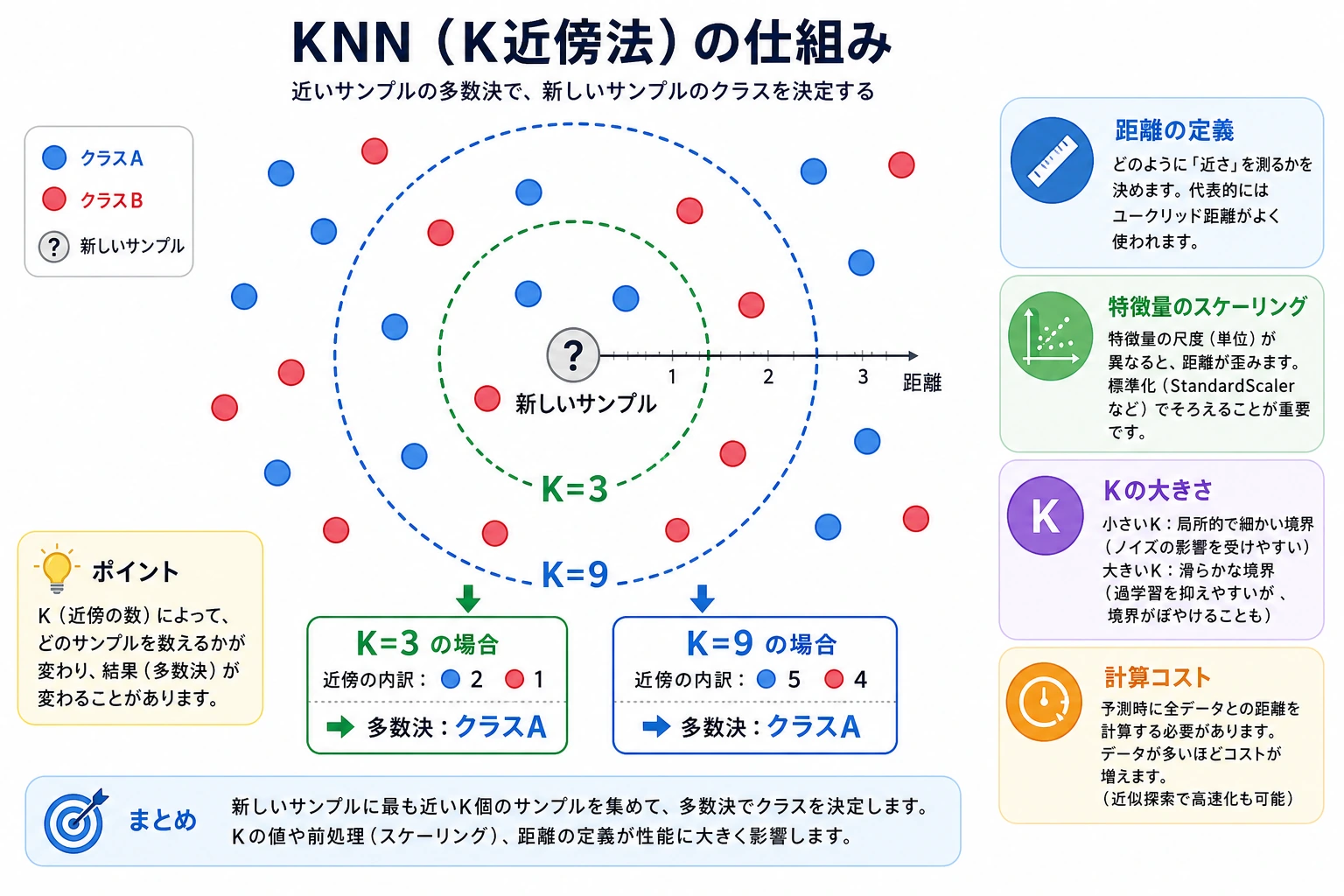
最小の KNN ベースラインを動かす
Section titled “最小の KNN ベースラインを動かす”def distance(a, b): return sum((x - y) ** 2 for x, y in zip(a, b)) ** 0.5
train = [ ([0.1, 0.2], "low"), ([0.2, 0.1], "low"), ([0.8, 0.9], "high"), ([0.9, 0.8], "high"),]
point = [0.75, 0.85]nearest = min(train, key=lambda row: distance(row[0], point))print("prediction:", nearest[1])print("neighbor:", nearest[0])期待される出力:
prediction: highneighbor: [0.8, 0.9]これはベースライン作成の最小習慣です。特徴量を決め、距離を比べ、予測し、その結果を後で比較できるように残します。
実プロジェクトでの使い方
Section titled “実プロジェクトでの使い方”古典的 ML を baseline contract として使います。大きなモデルを試す前に、clean features と SVM、KNN、Naive Bayes、LDA だけで多くの問題が解けないか確認します。baseline が強い場合、大きなモデルは追加コストを正当化する必要があります。
比較は具体的にします。同じ train/test split、同じ metric、少なくとも 1 つの失敗例を残します。こうすると古典的 ML は理論の寄り道ではなく、作りすぎを防ぐ実用的な guardrail になります。
このページを終えたら、この証拠カードを残します。
- モデルファミリー
- SVM、KNN、Naive Bayes、LDA、または別の古典的ベースライン
- データセット表示
- 特徴量スケール、クラスの偏り、決定境界、train/test 分割
- 指標
- accuracy/F1、confusion matrix、margin、近傍の挙動、または投影の品質
- 失敗確認
- スケーリング、高次元性、弱い仮定、リーク、またはベースライン適合性の低さ
- 期待される成果
- 1つの制約メモ付きの古典的 ML ベースライン結果
この順番で学ぶ
Section titled “この順番で学ぶ”| ステップ | レッスン | 実践で残す成果 |
|---|---|---|
| 1 | E.C.1 SVM | マージン、サポートベクトル、C、カーネル選択を説明する |
| 2 | E.C.2 KNN | 距離と投票によるベースラインを作る |
| 3 | E.C.3 ナイーブベイズ | 証拠の件数をクラス確率に変換する |
| 4 | E.C.4 LDA | 特徴量を投影してクラスを分ける |
合格チェック
Section titled “合格チェック”古典的なベースラインを 1 つ作り、それがなぜ適切か説明し、より重いモデルまたは後続プロジェクトの結果と比較できれば合格です。
確認の考え方と解説
合格する答えは、なぜこのベースラインが適切なのかを先に説明します。たとえば、データが小さい、特徴量が明確、距離や境界に意味がある、といった理由です。そのうえで、より重いモデルや後続プロジェクトの結果と比較し、どこに限界があるかを述べます。
単に accuracy を 1 つ報告するだけでは足りません。古典的 ML の価値は、速く、説明しやすく、比較しやすい基準を作ることです。