E.C.2 K 近傍法
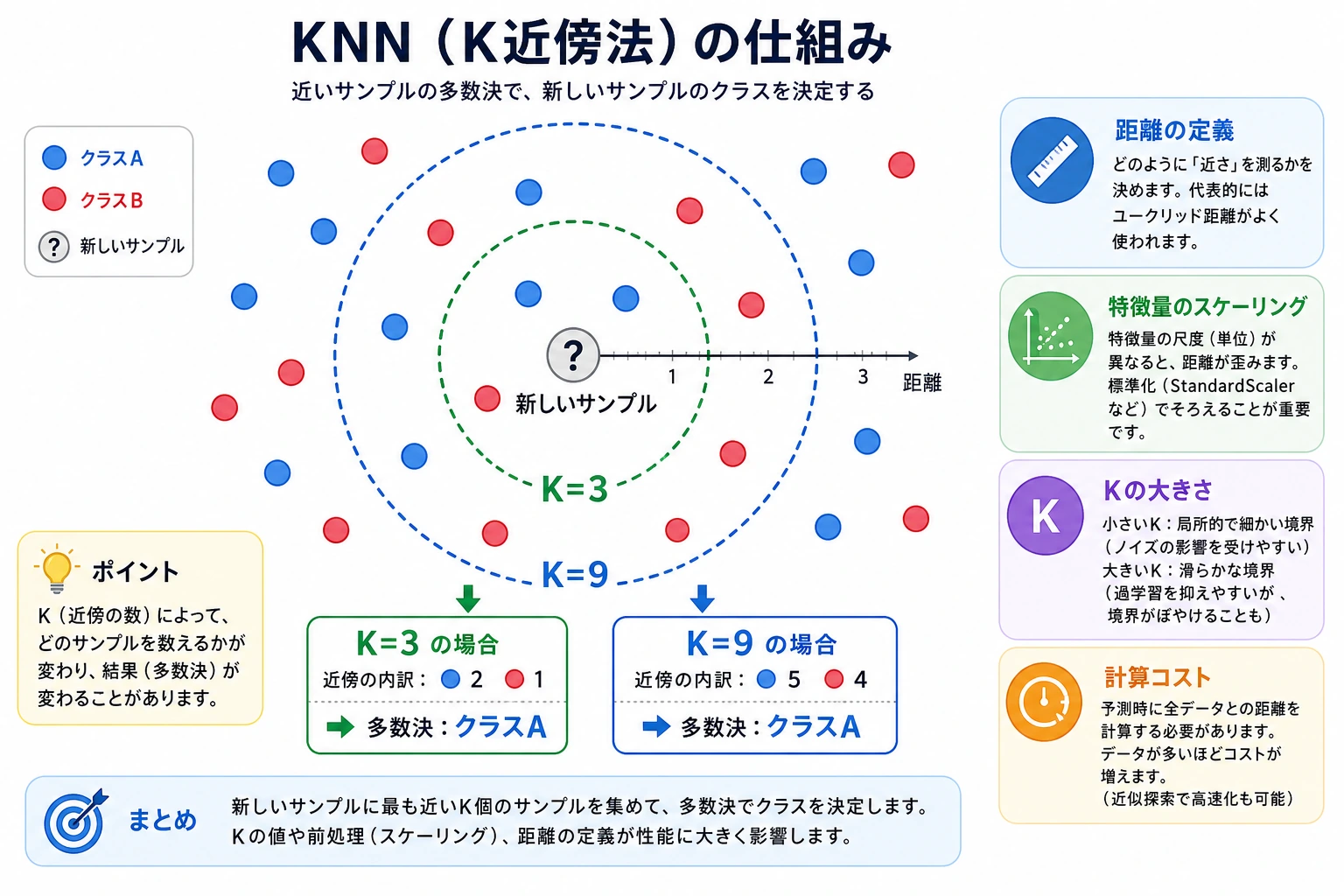
KNN は、新しいサンプルの近くにあるラベル付きサンプルを見て投票します。学習コストはほとんどありませんが、予測時に距離比較が必要なため、データが大きいと重くなります。
準備するもの
- Python 3.10+
- 現在の安定版
scikit-learnとnumpy
python -m pip install -U scikit-learn numpy
重要用語
- K:投票に参加する近傍点の数。
- 距離尺度:「近い」をどう計算するか。
- Lazy learning(遅延学習):学習時の作業が少なく、予測時の作業が多い方式。
- Scaling(スケーリング):特徴量の範囲が違うときに必要。
近傍投票を動かす
knn_vote.py を作成します。
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
X = np.array([
[1, 1],
[2, 2],
[2, 1],
[8, 8],
[9, 9],
[8, 9],
])
y = np.array([0, 0, 0, 1, 1, 1])
model = make_pipeline(
StandardScaler(),
KNeighborsClassifier(n_neighbors=3),
)
model.fit(X, y)
pred = model.predict([[3, 3], [8.5, 8.2]])
print("predictions:", pred.tolist())
実行します。
python knn_vote.py
期待される出力:
predictions: [0, 1]
このモデルは複雑な式を学習していません。サンプルを保持し、特徴量をスケーリングし、距離を測り、投票します。
K を変える
n_neighbors=3 を 1 と 5 に変更します。K が小さいほど局所的な点に敏感で、K が大きいほど判断はなめらかになります。
実用的な判断
KNN を試す場面:
- データセットが小さい。
- 特徴量の距離に意味がある。
- すぐに説明しやすいベースラインがほしい。
- 予測レイテンシが厳しくない。
巨大データや高 QPS のリアルタイムサービスでは、デフォルトにしないほうが安全です。
よくある間違い
- 特徴量のスケーリングを忘れる。
- KNN が「学習済み」だから軽いと思い、予測時のコストを見落とす。
- 特徴量が本当に類似性を表しているか確認せず、K だけを調整する。
練習
値が 10000 前後の3つ目の特徴量を追加します。StandardScaler() を外し、距離投票がどう歪むか観察してください。