E.C.4 線形判別分析
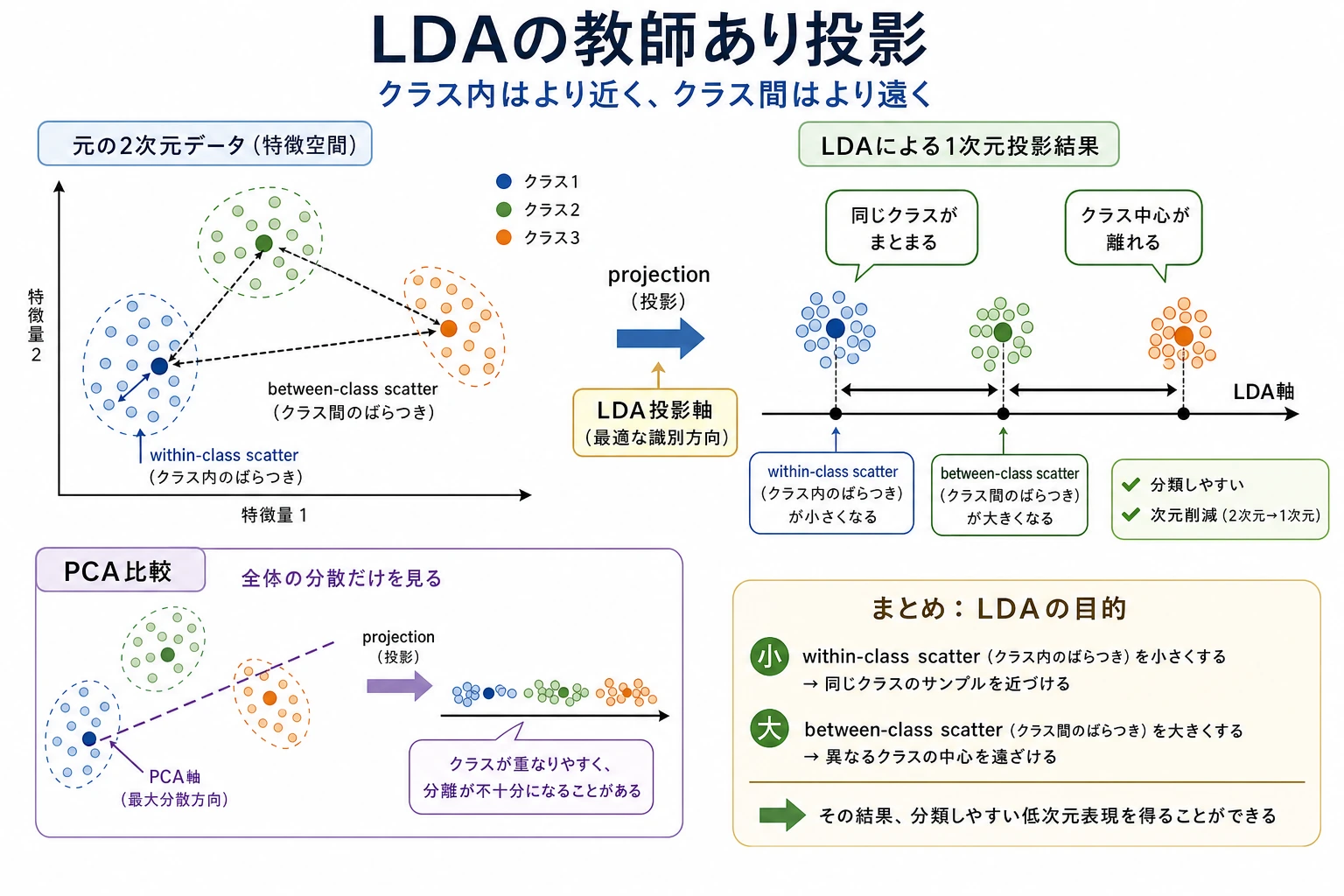
LDA は、同じクラスのサンプルを近づけ、異なるクラスを離す射影方向を探します。分類器としても、教師あり次元削減としても使えます。
準備するもの
- Python 3.10+
- 現在の安定版
scikit-learnとnumpy
python -m pip install -U scikit-learn numpy
重要用語
- クラス内分散:同じクラス内の散らばり。
- クラス間分離:クラス中心同士の距離。
- 射影:特徴量をより低次元へ写すこと。
- 教師あり次元削減:ラベル情報を使って次元を減らすこと。
- ここでの LDA:Linear Discriminant Analysis。Latent Dirichlet Allocation ではありません。
LDA の分類と射影を動かす
lda_projection.py を作成します。
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X = np.array([
[1.0, 2.0],
[1.5, 1.8],
[2.0, 1.5],
[4.0, 5.0],
[4.5, 4.8],
[5.0, 4.5],
])
y = np.array([0, 0, 0, 1, 1, 1])
model = LinearDiscriminantAnalysis(n_components=1)
model.fit(X, y)
pred = model.predict([[1.4, 1.9], [4.8, 4.6]])
projection = model.transform(X)
print("predictions:", pred.tolist())
print("projection_shape:", projection.shape)
実行します。
python lda_projection.py
期待される出力:
predictions: [0, 1]
projection_shape: (6, 1)
同じモデルが新しい点を分類し、訓練データを1つの判別的な方向へ射影しました。
PCA と比べる
PCA は全体の分散が大きい方向を探し、ラベルを見ません。LDA はラベルを使い、クラスを最も分けやすい方向を探します。一般的な圧縮よりクラス分離が重要なときに有用です。
実用的な判断
LDA を試す場面:
- ラベルがある。
- 各クラスが比較的まとまっている。
- 軽量な線形ベースラインがほしい。
- 可視化や下流モデルのために低次元表現がほしい。
クラス境界が明らかに強い非線形なら、最初の候補にはしにくいです。
よくある間違い
- この LDA とトピックモデルの LDA を混同する。
- ラベルを使うから PCA より常に良いと思い込む。
- 2クラスの場合、LDA は最大1成分にしか射影できないことを忘れる。
練習
3つ目のクラスを追加し、n_components=2 にします。新しい射影形状を出力し、最大成分数が変わった理由を説明してください。