3.2.3 配列のインデックスとスライス
学習目標
- 1次元配列と多次元配列の基本インデックスとスライスを理解する
- ブールインデックスを使った条件抽出を学ぶ
- ファンシーインデックス(Fancy Indexing)を理解する
- ビュー(View)とコピー(Copy)の違いを理解する
1次元配列のインデックスとスライス
1次元配列のインデックスは、Python のリストと基本的に同じです:
import numpy as np
arr = np.array([10, 20, 30, 40, 50, 60, 70, 80])
# ===== 基本インデックス =====
print(arr[0]) # 10 最初の要素
print(arr[3]) # 40 4番目の要素
print(arr[-1]) # 80 最後の要素
print(arr[-2]) # 70 末尾から2番目の要素
# ===== スライス [start:stop:step] =====
print(arr[2:5]) # [30 40 50] インデックス 2 から 4
print(arr[:3]) # [10 20 30] 最初の3個
print(arr[5:]) # [60 70 80] インデックス 5 から末尾まで
print(arr[::2]) # [10 30 50 70] 1つおきに取り出す
print(arr[::-1]) # [80 70 60 50 40 30 20 10] 逆順にする
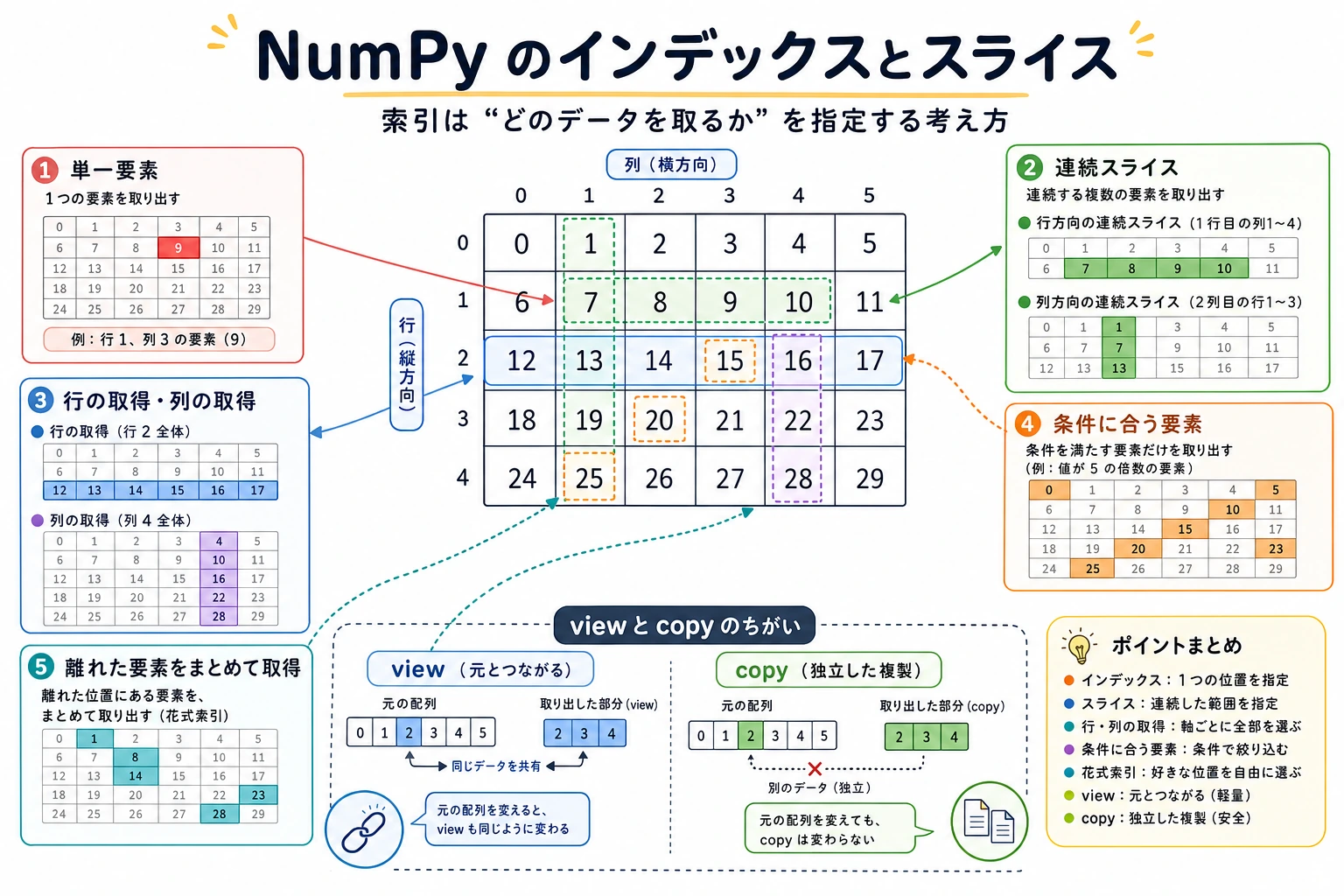
2次元配列のインデックスとスライス
2次元配列は [行, 列] の形でアクセスします:
matrix = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
])
単一要素へのアクセス
print(matrix[0, 0]) # 1 0行0列
print(matrix[1, 2]) # 7 1行2列
print(matrix[-1, -1]) # 16 最後の行・最後の列
行全体 / 列全体へのアクセス
print(matrix[0]) # [1 2 3 4] 0行目(行全体)
print(matrix[0, :]) # [1 2 3 4] 同じ意味。より明示的な書き方
print(matrix[:, 0]) # [ 1 5 9 13] 0列目(列全体)
print(matrix[:, -1]) # [ 4 8 12 16] 最後の列
行・列のスライス
# 最初の2行、最初の3列を取り出す
sub = matrix[:2, :3]
print(sub)
# [[1 2 3]
# [5 6 7]]
# 1〜2行目、2〜3列目を取り出す
sub2 = matrix[1:3, 2:4]
print(sub2)
# [[ 7 8]
# [11 12]]
# 1つおきに行を取り出す(0行目、2行目)
sub3 = matrix[::2]
print(sub3)
# [[ 1 2 3 4]
# [ 9 10 11 12]]
2次元インデックスの図解
matrix =
列0 列1 列2 列3
行0 [ 1 2 3 4 ]
行1 [ 5 6 7 8 ]
行2 [ 9 10 11 12 ]
行3 [ 13 14 15 16 ]
matrix[1, 2] → 7 (1行2列)
matrix[:2, :3] → [[1,2,3], [5,6,7]] (最初の2行、最初の3列)
matrix[:, 1] → [2, 6, 10, 14] (すべての行、1列目)
ブールインデックス:条件抽出
これは NumPy のとても強力な機能の1つです。条件式を使って、データを直接抽出できます。
基本の考え方
arr = np.array([15, 23, 8, 42, 31, 5, 19, 27])
# 1段階目:条件式からブール配列を作る
mask = arr > 20
print(mask) # [False True False True True False False True]
# 2段階目:ブール配列をインデックスとして使い、True に対応する要素を取り出す
result = arr[mask]
print(result) # [23 42 31 27]
# 通常は1行でまとめて書ける
print(arr[arr > 20]) # [23 42 31 27]
よく使う条件抽出
scores = np.array([85, 92, 78, 65, 95, 43, 88, 72, 55, 90])
# 合格点(>= 60)
print(scores[scores >= 60]) # [85 92 78 65 95 88 72 90]
# 優秀点(>= 90)
print(scores[scores >= 90]) # [92 95 90]
# 不合格点(< 60)
print(scores[scores < 60]) # [43 55]
# 60〜80 の点数(複数条件は & でつなぐ。各条件はかっこで囲む)
print(scores[(scores >= 60) & (scores <= 80)]) # [78 65 72]
# 60未満または90より高い点数(複数条件は | でつなぐ)
print(scores[(scores < 60) | (scores > 90)]) # [92 95 43 55]
# 反転(~)
print(scores[~(scores >= 60)]) # [43 55] scores[scores < 60] と同じ
複数条件の書き方
NumPy では、複数条件を組み合わせるときに Python の and / or は使えません。代わりに次を使います。
&をandの代わりに使う(かつ)|をorの代わりに使う(または)~をnotの代わりに使う(否定)- 各条件は必ずかっこで囲む
# ❌ 間違った書き方
arr[arr > 5 and arr < 20]
# ✅ 正しい書き方
arr[(arr > 5) & (arr < 20)]
2次元配列でのブールインデックス
matrix = np.array([
[85, 92, 78],
[65, 95, 43],
[88, 72, 90]
])
# 80より大きい点数をすべて取り出す
print(matrix[matrix > 80]) # [85 92 95 88 90]
# 注意:結果は1次元配列になります!
# 不合格点を60に変更する(条件付き代入)
matrix[matrix < 60] = 60
print(matrix)
# [[85 92 78]
# [65 95 60] ← 43 が 60 に変わった
# [88 72 90]]
ファンシーインデックス(Fancy Indexing)
ファンシーインデックスでは、整数配列をインデックスとして使い、指定した位置の要素をまとめて取り出せます。
1次元のファンシーインデックス
arr = np.array([10, 20, 30, 40, 50, 60, 70])
# インデックス 1, 3, 5 の要素を取り出す
print(arr[[1, 3, 5]]) # [20 40 60]
# 同じ要素を繰り返し取り出せる
print(arr[[0, 0, 2, 2]]) # [10 10 30 30]
# 好きな順番で取り出せる
print(arr[[6, 4, 2, 0]]) # [70 50 30 10]
2次元のファンシーインデックス
matrix = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
# 0行目と2行目を取り出す
print(matrix[[0, 2]])
# [[ 1 2 3 4]
# [ 9 10 11 12]]
# 特定の位置:(0,1), (1,2), (2,3) の3要素を取り出す
rows = [0, 1, 2]
cols = [1, 2, 3]
print(matrix[rows, cols]) # [ 2 7 12]
ビュー(View)vs コピー(Copy)
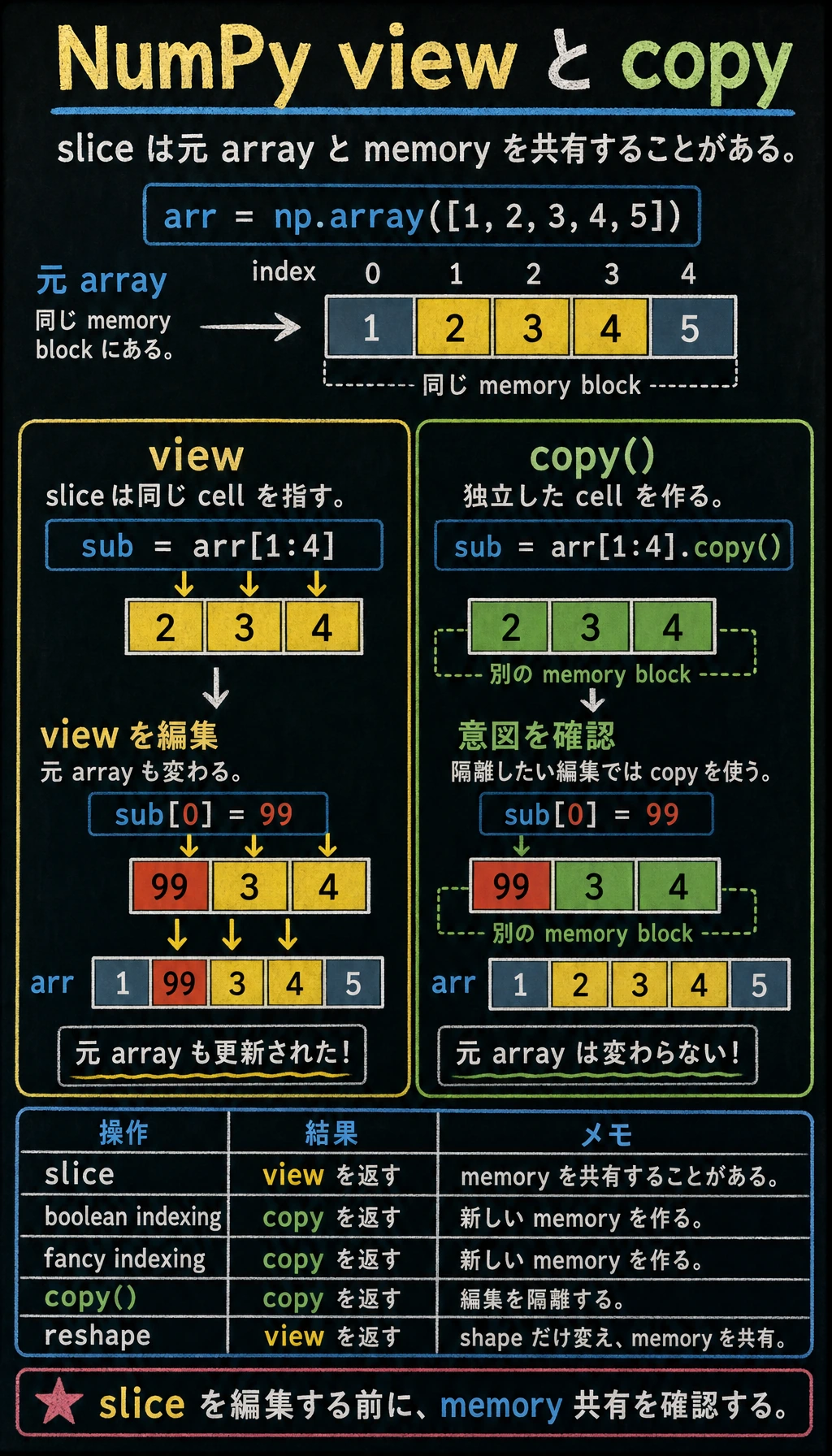
ここは初心者がつまずきやすいポイントです。NumPy のスライスはコピーではなくビューを返します。
ビュー:変更すると元の配列にも影響する
arr = np.array([1, 2, 3, 4, 5])
# スライスはビュー
sub = arr[1:4]
print(sub) # [2 3 4]
# sub を変更すると arr も変わる!
sub[0] = 99
print(sub) # [99 3 4]
print(arr) # [ 1 99 3 4 5] ← 元の配列も変わった!
コピー:互いに影響しない
arr = np.array([1, 2, 3, 4, 5])
# copy() で独立したコピーを作る
sub = arr[1:4].copy()
print(sub) # [2 3 4]
# sub を変更しても arr は変わらない
sub[0] = 99
print(sub) # [99 3 4]
print(arr) # [1 2 3 4 5] ← 元の配列は変わらない
いつビュー? いつコピー?
| 操作 | 戻り値の種類 | 例 |
|---|---|---|
| スライス | ビュー | arr[2:5] |
| ブールインデックス | コピー | arr[arr > 3] |
| ファンシーインデックス | コピー | arr[[1, 3, 5]] |
.copy() | コピー | arr[2:5].copy() |
.reshape() | ビュー(通常) | arr.reshape(2, 3) |
実用的なアドバイス
ある操作がビューを返すのかコピーを返すのか不安なとき、元の配列をうっかり変更したくないなら .copy() を付けましょう。安全第一です。
safe_sub = arr[1:4].copy() # いつでも安全
実践例:インデックスでデータを分析する
Titanic の場面に戻って、NumPy のインデックスを使ってデータを分析してみましょう。
import numpy as np
# 10人の乗客データを模したもの
ages = np.array([22, 38, 26, 35, 35, np.nan, 54, 2, 27, 14])
fares = np.array([7.25, 71.28, 7.92, 53.10, 8.05, 8.46, 51.86, 21.08, 11.13, 30.07])
survived = np.array([0, 1, 1, 1, 0, 0, 0, 0, 1, 1])
# 生存者の平均運賃を求める
survivor_fares = fares[survived == 1]
print(f"生存者の平均運賃: ${np.mean(survivor_fares):.2f}")
# 30歳より上の乗客の運賃を取り出す(NaN を除外する必要がある)
valid_mask = ~np.isnan(ages) # NaN を除外
age_mask = ages > 30
combined_mask = valid_mask & age_mask
print(f"30歳以上の乗客の運賃: {fares[combined_mask]}")
# 運賃が高い上位3人の乗客のインデックスを取り出す
top3_indices = np.argsort(fares)[-3:][::-1] # 並べ替えた後、最後の3つを取り、逆順にする
print(f"運賃 Top 3 のインデックス: {top3_indices}")
print(f"対応する運賃: {fares[top3_indices]}")
まとめ
| インデックス方法 | 構文 | 戻り値の種類 | 適した場面 |
|---|---|---|---|
| 基本インデックス | arr[i], arr[i, j] | 要素値 | 単一要素を取得する |
| スライス | arr[start:stop:step] | ビュー | 連続した範囲を取得する |
| ブールインデックス | arr[arr > 5] | コピー | 条件で抽出する |
| ファンシーインデックス | arr[[1, 3, 5]] | コピー | 離れた位置の要素を取る |
手を動かしてみよう
練習1:基本スライス
arr = np.arange(1, 21) # [1, 2, 3, ..., 20]
# 1. 最初の5個の要素を取り出す
# 2. すべての奇数位置の要素を取り出す(インデックス 1, 3, 5, ...)
# 3. 最後の3個の要素を取り出す
# 4. 配列を逆順にする
練習2:2次元スライス
matrix = np.arange(1, 26).reshape(5, 5)
print(matrix)
# [[ 1 2 3 4 5]
# [ 6 7 8 9 10]
# [11 12 13 14 15]
# [16 17 18 19 20]
# [21 22 23 24 25]]
# 1. 真ん中の 3×3 の部分行列を取り出す
# 2. 2列目のすべての要素を取り出す
# 3. 対角線の要素 [1, 7, 13, 19, 25] を取り出す(ヒント:ファンシーインデックスを使う)
練習3:ブールインデックスの実践
# あるクラス20人の数学の点数
math_scores = np.array([
78, 92, 65, 88, 45, 95, 72, 81, 56, 90,
83, 67, 94, 73, 85, 60, 98, 77, 69, 87
])
# 1. すべての不合格点(< 60)を取り出す
# 2. 80〜90 の点数(両端含む)を取り出す
# 3. 合格した学生の平均点を計算する
# 4. すべての不合格点を60に変更する
# 5. 変更後の平均点を計算する