3.2.6 線形代数の基本操作
学習目標
- 行列積の3つの書き方(dot、matmul、@)を身につける
- 逆行列、行列式、固有値の意味と計算方法を理解する
numpy.linalgモジュールを使って線形代数計算ができるようになる- 線形代数が AI で重要な理由を理解する
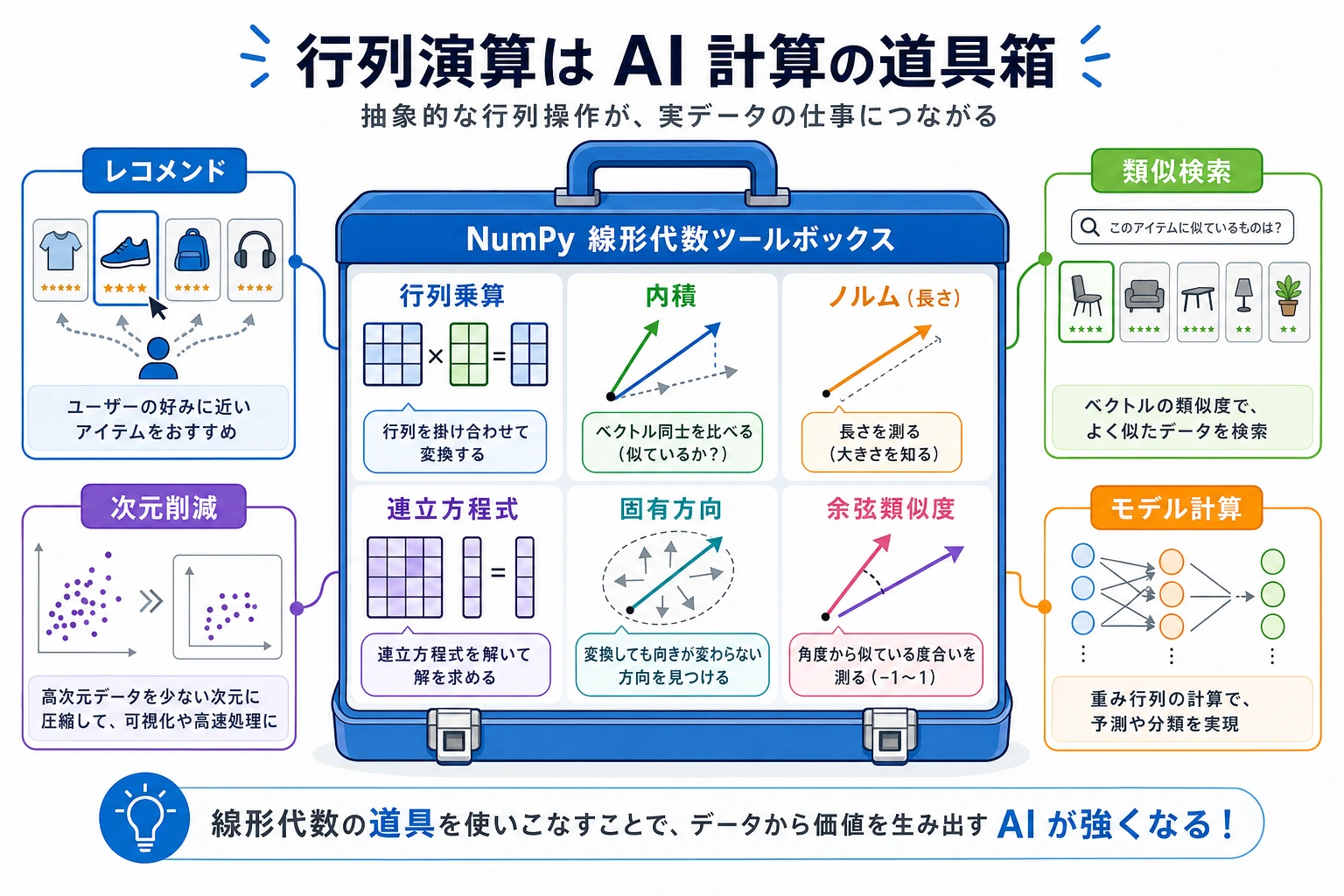
なぜ線形代数を学ぶの?
「線形代数」と聞くと、数学っぽくて抽象的に感じるかもしれません。ですが、AI の分野ではもっとも重要な数学の基礎です。
| AI の場面 | 線形代数の役割 |
|---|---|
| ニューラルネットワーク | 各層の計算は行列積そのもの |
| レコメンドシステム | ユーザー-商品行列の分解 |
| 画像処理 | 1枚の画像は行列として表せる |
| 単語ベクトル | 各単語はベクトル、類似度 = 内積 |
| 次元削減 | PCA は固有値と固有ベクトルを求める処理 |
まずは NumPy でこれらの概念を触って、感覚をつかみましょう。4 AI 数学の最小必要基礎で、原理をさらに詳しく説明します。
行列積
要素ごとの掛け算 vs 行列積
ここは初心者がいちばん混同しやすいポイントです。
import numpy as np
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# 要素ごとの掛け算(同じ位置どうしを掛ける)
print(A * B)
# [[ 5 12]
# [21 32]]
# 計算過程:1×5=5, 2×6=12, 3×7=21, 4×8=32
# 行列積
print(A @ B)
# [[19 22]
# [43 50]]
# 計算過程:
# [1×5+2×7, 1×6+2×8] = [19, 22]
# [3×5+4×7, 3×6+4×8] = [43, 50]
行列積の3つの書き方
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# 方法 1:@ 演算子(おすすめ、いちばん簡潔)
C1 = A @ B
# 方法 2:np.matmul
C2 = np.matmul(A, B)
# 方法 3:np.dot
C3 = np.dot(A, B)
# 3つの方法は結果がまったく同じ
print(np.array_equal(C1, C2)) # True
print(np.array_equal(C2, C3)) # True
Python 3.5+ では、@ 演算子が行列積の書き方としてもっともおすすめです。簡潔で見やすいです。
行列積のルール
2つの行列が掛け算できる条件は、前の列数 = 後ろの行数 です。
# (2, 3) @ (3, 4) → (2, 4) ✅ 3 == 3
A = np.ones((2, 3))
B = np.ones((3, 4))
C = A @ B
print(C.shape) # (2, 4)
# (2, 3) @ (2, 4) → ❌ エラー!3 ≠ 2
# A = np.ones((2, 3))
# B = np.ones((2, 4))
# C = A @ B # ValueError!
覚え方:(m, n) @ (n, p) → (m, p)
ベクトルの内積
1次元配列の @ や np.dot は、内積(点積)を計算します。
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 内積 = 1×4 + 2×5 + 3×6 = 32
print(a @ b) # 32
print(np.dot(a, b)) # 32
内積は AI でとても重要です。あとで学ぶコサイン類似度やAttention 機構でも使います。
numpy.linalg モジュール
NumPy の linalg サブモジュールには、線形代数の機能がひと通りそろっています。
逆行列
行列の逆行列は A × A⁻¹ = 単位行列 を満たします。
A = np.array([[1, 2], [3, 4]])
# 逆行列を求める
A_inv = np.linalg.inv(A)
print(A_inv)
# [[-2. 1. ]
# [ 1.5 -0.5]]
# 確認:A × A_inv ≈ 単位行列
print(A @ A_inv)
# [[1.0000000e+00 0.0000000e+00]
# [8.8817842e-16 1.0000000e+00]]
# 対角線は 1、それ以外は 0 に近い(浮動小数点の誤差)
逆行列があるのは、正方行列(行数 = 列数)で、かつ行列式が 0 ではない行列だけです。
# 特異行列(行列式が 0)には逆行列がない
singular = np.array([[1, 2], [2, 4]]) # 2行目は1行目の2倍
# np.linalg.inv(singular) # LinAlgError: Singular matrix
行列式
行列式はスカラー値で、行列の「拡大・縮小の度合い」を表します。
A = np.array([[1, 2], [3, 4]])
det = np.linalg.det(A)
print(f"行列式: {det:.1f}") # -2.0
# 2×2 行列の行列式 = ad - bc
# [[a, b], [c, d]] → 1×4 - 2×3 = -2
固有値と固有ベクトル
固有値と固有ベクトルは、行列の「DNA」のようなものです。行列の内側にある性質を教えてくれます。
A = np.array([[4, 2], [1, 3]])
# 固有値と固有ベクトルを求める
eigenvalues, eigenvectors = np.linalg.eig(A)
print(f"固有値: {eigenvalues}") # [5. 2.]
print(f"固有ベクトル:\n{eigenvectors}")
# [[ 0.894 -0.707]
# [ 0.447 0.707]]
行列を「変換」(たとえば回転や伸縮)だと考えると、
- 固有ベクトル = 変換しても向きが変わらないベクトル
- 固有値 = その方向にどれだけ伸び縮みするかを表す値
この考え方は、あとで PCA による次元削減を学ぶときにとても役立ちます。PCA は本質的に、データがいちばん大きく変化する方向(最大の固有値に対応する固有ベクトル)を見つける方法です。
連立一次方程式を解く
方程式を解く:
2x + y = 5
x + 3y = 7
行列形式では Ax = b と書けます。
A = np.array([[2, 1], [1, 3]])
b = np.array([5, 7])
# 方程式を解く
x = np.linalg.solve(A, b)
print(f"x = {x[0]:.2f}, y = {x[1]:.2f}") # x = 1.60, y = 1.80
# 確認
print(A @ x) # [5. 7.] ← b と一致するので、解は正しい
そのほかの便利な操作
ノルム(ベクトルの長さ)
v = np.array([3, 4])
# L2 ノルム(ユークリッド距離)
l2 = np.linalg.norm(v)
print(f"L2 ノルム: {l2}") # 5.0 (3² + 4² = 25, √25 = 5)
# L1 ノルム(絶対値の和)
l1 = np.linalg.norm(v, ord=1)
print(f"L1 ノルム: {l1}") # 7.0 (|3| + |4| = 7)
# 行列のノルム
M = np.array([[1, 2], [3, 4]])
print(f"行列の Frobenius ノルム: {np.linalg.norm(M):.2f}") # 5.48
行列のランク
A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
rank = np.linalg.matrix_rank(A)
print(f"行列のランク: {rank}") # 2(フルランクではない。3行目 = 1行目×(-1) + 2行目×2)
よく使う関数一覧
| 関数 | 役割 | 例 |
|---|---|---|
A @ B | 行列積 | np.array([[1,2],[3,4]]) @ np.eye(2) |
np.linalg.inv(A) | 逆行列 | |
np.linalg.det(A) | 行列式 | |
np.linalg.eig(A) | 固有値と固有ベクトル | |
np.linalg.solve(A, b) | 方程式 Ax=b を解く | |
np.linalg.norm(v) | ノルム | |
np.linalg.matrix_rank(A) | 行列のランク | |
A.T | 転置 | |
np.trace(A) | トレース(対角線の和) |
実践:コサイン類似度を計算する
コサイン類似度は、AI で 2 つのベクトルの「似ている度合い」を測る定番の方法です。あとで学ぶ単語ベクトル、レコメンドシステム、RAG でも何度も使います。
公式:cos(θ) = (a · b) / (||a|| × ||b||)
import numpy as np
def cosine_similarity(a, b):
"""2つのベクトルのコサイン類似度を計算する"""
dot_product = a @ b # 内積
norm_a = np.linalg.norm(a) # a の長さ
norm_b = np.linalg.norm(b) # b の長さ
return dot_product / (norm_a * norm_b)
# 例:ユーザーの興味を比較する
# 各次元は [技術, スポーツ, 音楽, 映画, グルメ]
user_a = np.array([5, 1, 3, 4, 2]) # 技術と映画が好き
user_b = np.array([4, 2, 3, 5, 1]) # 技術と映画が好き
user_c = np.array([1, 5, 2, 1, 4]) # スポーツとグルメが好き
print(f"A と B の類似度: {cosine_similarity(user_a, user_b):.4f}") # 0.9631 とても似ている
print(f"A と C の類似度: {cosine_similarity(user_a, user_c):.4f}") # 0.5528 あまり似ていない
print(f"B と C の類似度: {cosine_similarity(user_b, user_c):.4f}") # 0.5025 あまり似ていない
まとめ
| 概念 | 説明 | NumPy 関数 |
|---|---|---|
| 行列積 | (m,n) @ (n,p) → (m,p) | A @ B または np.matmul |
| 逆行列 | A × A⁻¹ = I | np.linalg.inv() |
| 行列式 | 行列の拡大・縮小の度合い | np.linalg.det() |
| 固有値/ベクトル | 行列の「DNA」 | np.linalg.eig() |
| 方程式を解く | Ax = b を解く | np.linalg.solve() |
| ノルム | ベクトルの長さ | np.linalg.norm() |
この段階では、次の3つができれば十分です。
- NumPy の線形代数関数を使える
- 行列積、逆行列、固有値がざっくり何か分かる
- コサイン類似度を計算できる
深い数学の理解は、4 AI 数学の最小必要基礎で体系的に学びます。今はまず、コードに慣れることを大切にしましょう。
手を動かしてみよう
練習 1:行列積
# ある店の 3 種類の商品価格
prices = np.array([10, 25, 8]) # [りんご, ステーキ, パン]
# 3 人の客の購入数
quantities = np.array([
[3, 1, 2], # 顧客 1: りんご3個 + ステーキ1つ + パン2個
[0, 2, 5], # 顧客 2
[5, 0, 3] # 顧客 3
])
# 行列積を使って、それぞれの合計金額を計算する
# totals = ?
練習 2:方程式を解く
# 次の連立方程式を解く:
# 3x + 2y - z = 1
# x - y + 2z = 5
# 2x + 3y - z = 0
#
# ヒント:Ax = b の形に書き直す
練習 3:コサイン類似度の応用
# 5本の映画の特徴ベクトルがあるとします
# 各次元は [アクション, コメディ, 恋愛, SF, ホラー]
movies = {
"アベンジャーズ": np.array([5, 2, 1, 4, 0]),
"タイム・イズ・マネー": np.array([1, 5, 2, 0, 0]),
"タイタニック": np.array([1, 0, 5, 0, 1]),
"インターステラー": np.array([3, 0, 2, 5, 0]),
"新感染 ファイナル・エクスプレス": np.array([4, 0, 1, 1, 5]),
}
# コサイン類似度を使って、「アベンジャーズ」といちばん似ている映画を見つける
# ヒント:「アベンジャーズ」と他の各映画のコサイン類似度を計算する