6.1.8 任意の背景:深層学習のブレークスルー
この節の位置づけ
このページは短い地図であり、歴史の試験ではありません。モデル名を見るたびに、次の問いに答えられれば十分です。
そのブレークスルーは、前の方法ではうまく解けなかった何を解決したのか?
まず時間線を見る
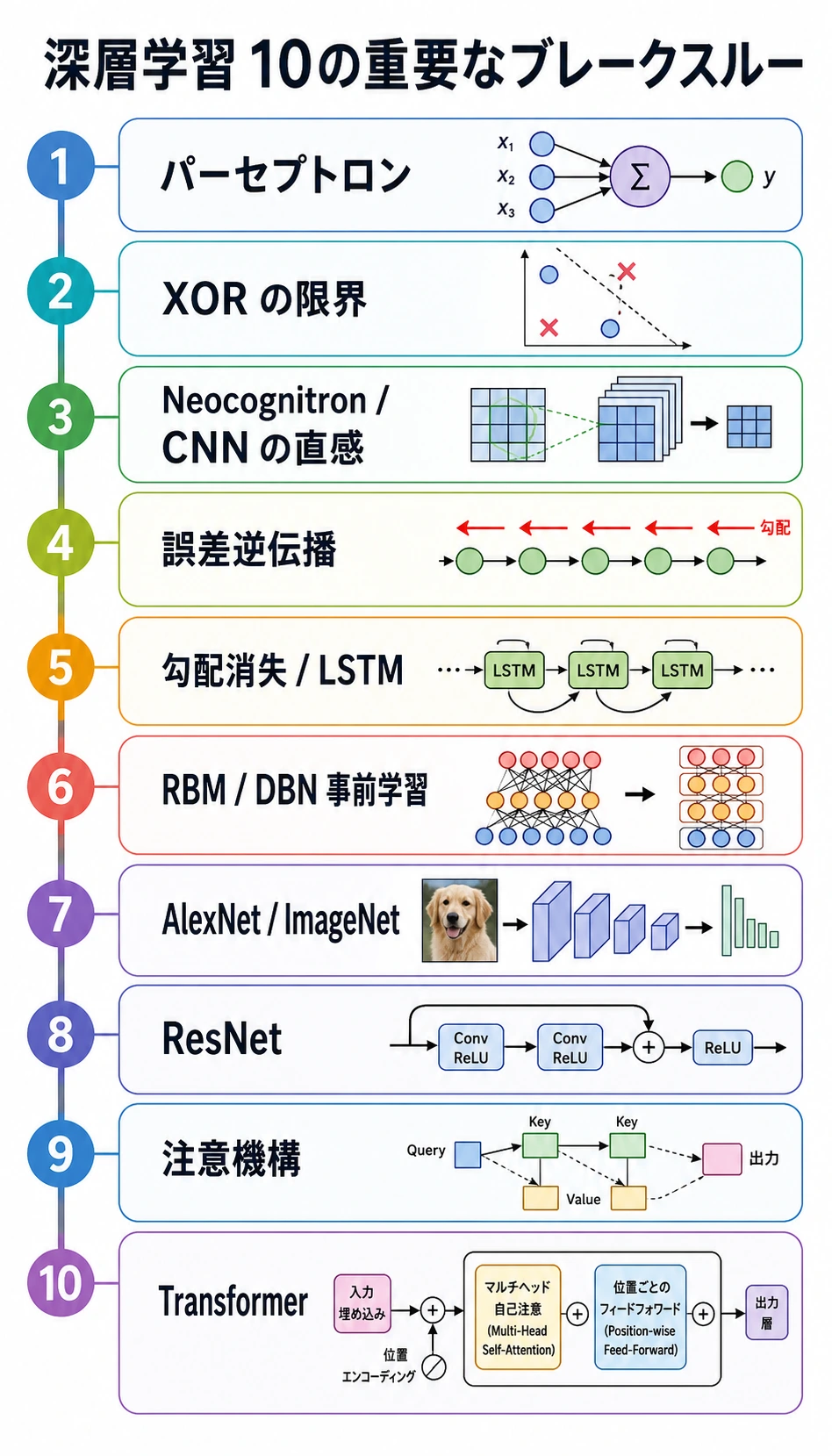
時間線は、次の一本の流れとして読みます。
単純なニューロン -> 線形モデルの限界 -> 学習できる多層ネットワーク -> 安定した深層学習 -> 拡張できる画像モデル -> Attention による系列モデリング
この流れを覚えておくと、第6章のアーキテクチャが孤立した名前に見えにくくなります。
三つの大きな変化
| 変化 | 当時の期待 | 主なボトルネック | 次の段階を開いたもの |
|---|---|---|---|
| 初期ニューラルネットワーク | 機械がデータから学べる | 単層モデルが弱い | 隠れ層と逆伝播 |
| 学習可能な深層ネットワーク | 多層モデルが表現を学べる | 勾配消失、データ不足、計算資源不足 | LSTM、初期化、事前学習の考え方 |
| 現代の深層学習 | データ、GPU、構造が一緒に拡張する | 非常に深いモデルと長期依存が難しい | AlexNet、ResNet、Attention、Transformer |
だから第6章では、アーキテクチャの前に基礎を学びます。
| この歴史上の問題を見たら | 講座で見直す場所 |
|---|---|
| 1つのニューロンでは弱い | 6.1.3 ニューロンと活性化 |
| 多層ネットワークには勾配が必要 | 6.1.4 順伝播と逆伝播 |
| 学習が不安定になりやすい | 6.1.5 最適化、6.1.6 正則化、6.1.7 初期化 |
| 画像には局所特徴が必要 | 第6章後半の CNN セクション |
| 系列には記憶や Attention が必要 | RNN、LSTM、Attention、Transformer セクション |
覚えておきたい十個の突破
| 時期 | ブレークスルー | 解決した問題 | 講座での意味 |
|---|---|---|---|
| 1943-1958 | 人工ニューロンとパーセプトロン | サンプルからパラメータを学ぶ発想を可能にした | ニューロンは重み付き和と判定 |
| 1969 | XOR の限界 | 単層線形モデルでは足りないと示した | 隠れ層と非線形活性化が重要 |
| 1980 | ネオコグニトロン | 局所的な視覚特徴と階層構造を先取りした | CNN はまず局所パターンを見る |
| 1986 | 逆伝播 | 多層ネットワークを学習可能にした | loss.backward() はこの考え方の現代形 |
| 1989 | 一般近似 | 非線形ネットワークが複雑な関数を表せると示した | 表現力には深さと活性化が必要 |
| 1994-1997 | 勾配消失と LSTM | 長い系列の記憶をより実用的にした | ゲートが時間をまたいで情報を残す |
| 2006 | RBM / DBN 事前学習 | 深い表現学習への関心を復活させた | 事前学習が重要な考え方になった |
| 2012 | AlexNet / ImageNet | データ + GPU + CNN が画像で強いことを示した | 大規模学習がコンピュータビジョンを変えた |
| 2015 | ResNet | 非常に深い CNN を学習しやすくした | 残差経路が勾配の流れを助ける |
| 2017 | Attention / Transformer | 長距離系列モデリングを並列かつ拡張可能にした | 現代 LLM の土台 |
名前から思い出すべき直感
この小さな表で素早く思い出します。
| 名前 | まず考えること |
|---|---|
| パーセプトロン | 学習できる線形スコア |
| XOR | 線形境界には限界がある |
| 逆伝播 | 計算グラフに沿って誤差を配る |
| LSTM / GRU | ゲートで長い系列を覚える |
| AlexNet | GPU 規模の CNN ブレークスルー |
| ResNet | 深いネットワークのショートカット |
| Attention | 各 token が関連 token を見られる |
| Transformer | Attention ブロックを大規模に積む |
学習中の使い方
年号を丸暗記する必要はありません。第6章の各アーキテクチャを学んだあと、次の三つだけを書いてください。
- 古いボトルネックを一文で書く。
- 新しい仕組みを一文で書く。
- 本章の実験を動かし、その仕組みを表すコード行を指す。
例:
古いボトルネック:深い CNN は最適化しにくい。
新しい仕組み:ResNet はショートカット経路を追加する。
コードの手がかり:output = block(x) + x
こうすると、歴史がただの用語ではなく、実装とつながります。
クイックチェック
次に答えられれば先へ進めます。
- XOR はなぜ単層モデルの限界を示したのか?
- 逆伝播はなぜ多層ネットワークに重要だったのか?
- LSTM はなぜ Transformer より前に現れたのか?
- ResNet はなぜ非常に深い CNN を助けたのか?
- Attention はなぜ現代の大規模言語モデルへの橋になったのか?
答えが「前のモデルでは……できなかったから」から始まるなら、歴史をよい読み方で読めています。