6.3.1 CNN ロードマップ:画像を特徴マップへ変える
CNN は局所的な視覚パターンを学びます。画像を1行に平坦化するのではなく、小さな領域をスキャンして特徴マップを作ります。
まず画像フローを見る
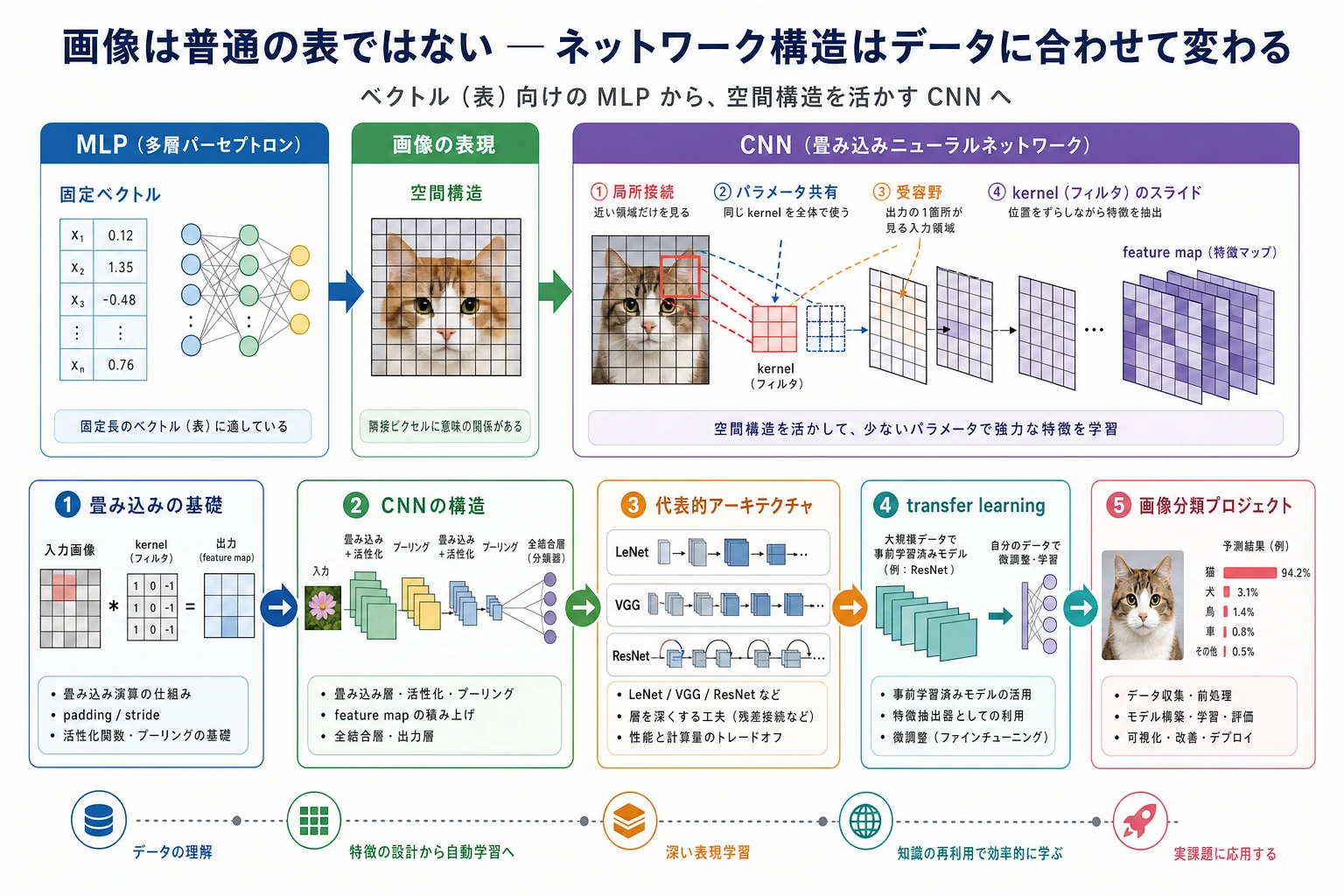
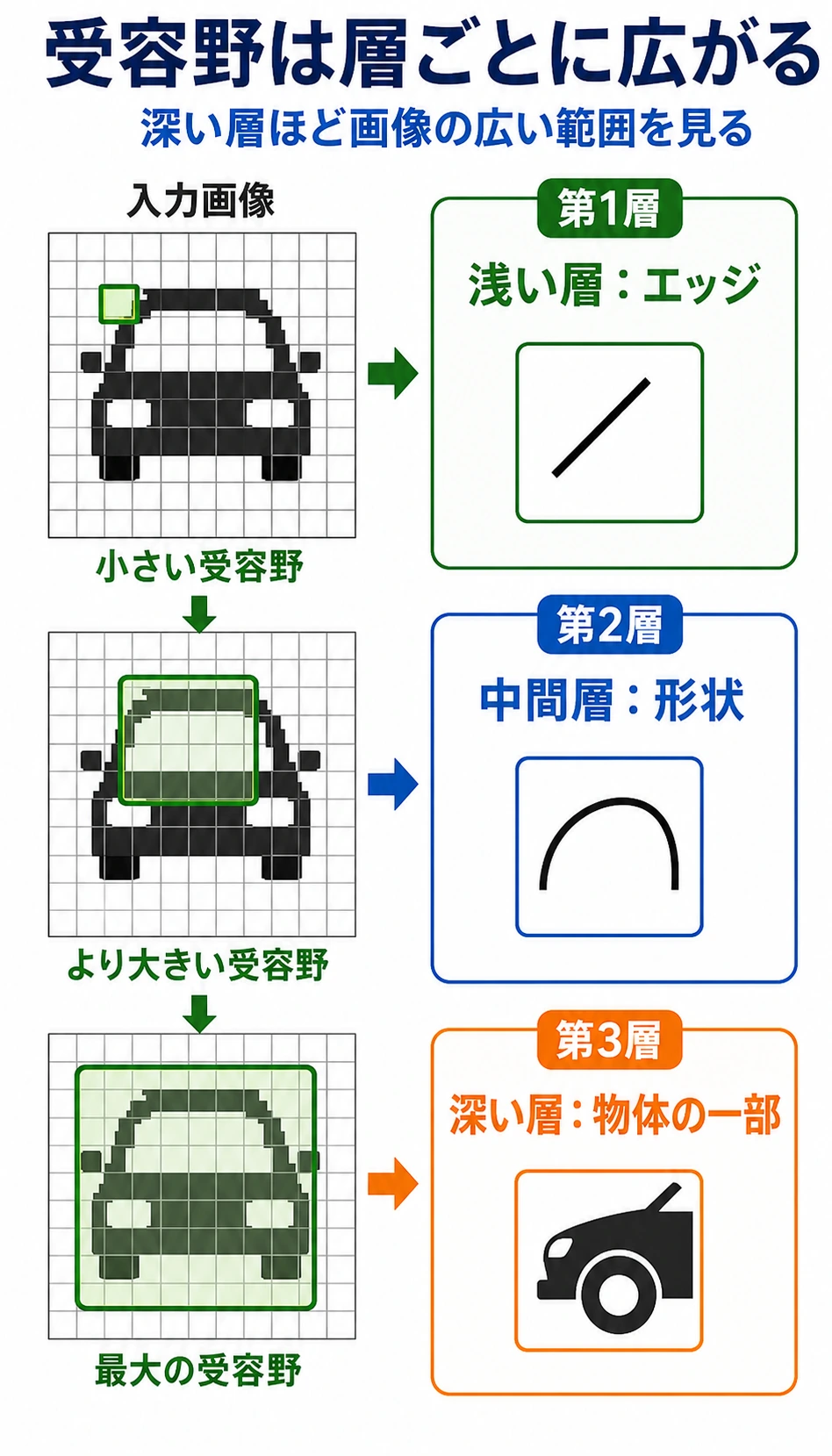
| 概念 | 最初の意味 |
|---|---|
| channel | 色または学習された特徴次元 |
| kernel | 小さなスライドフィルタ |
| feature map | フィルタが画像を走査した後の出力 |
| pooling / stride | 空間サイズを小さくする |
| transfer learning | 学習済みの視覚 backbone を再利用する |
畳み込みを一度動かす
cnn_first_loop.py を作り、torch をインストールしてから実行します。
import torch
image = torch.randn(1, 3, 32, 32)
conv = torch.nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, padding=1)
features = conv(image)
print("input_shape:", tuple(image.shape))
print("feature_shape:", tuple(features.shape))
出力:
input_shape: (1, 3, 32, 32)
feature_shape: (1, 8, 32, 32)
形は [batch, channels, height, width] と読みます。畳み込みは 3 入力チャネルを 8 個の学習特徴チャネルに変えました。
この順番で学ぶ
| 順番 | 読む | 練習すること |
|---|---|---|
| 1 | 6.3.2 畳み込み基礎 | kernel、stride、padding、channel |
| 2 | 6.3.3 CNN 構造 | 畳み込みブロック、pooling、分類ヘッド |
| 3 | 6.3.4 古典的アーキテクチャ | LeNet、AlexNet、VGG、ResNet の直感 |
| 4 | 6.3.5 転移学習 | backbone 凍結、fine-tuning |
| 5 | 6.3.6 画像分類実践 | データセット、学習、予測例 |
合格ライン
入力画像形状と特徴マップ形状の間で何が変わったか、そして小規模データセットで学習済み CNN backbone が役立つ理由を説明できれば合格です。