6.1.1 ニューラルネットワークロードマップ:線形層、活性化、損失、更新
ニューラルネットワークは魔法ではありません。層はまず重み付き和を計算し、活性化で信号の形を変え、学習では重みを調整して loss を下げます。
まず流れを見る
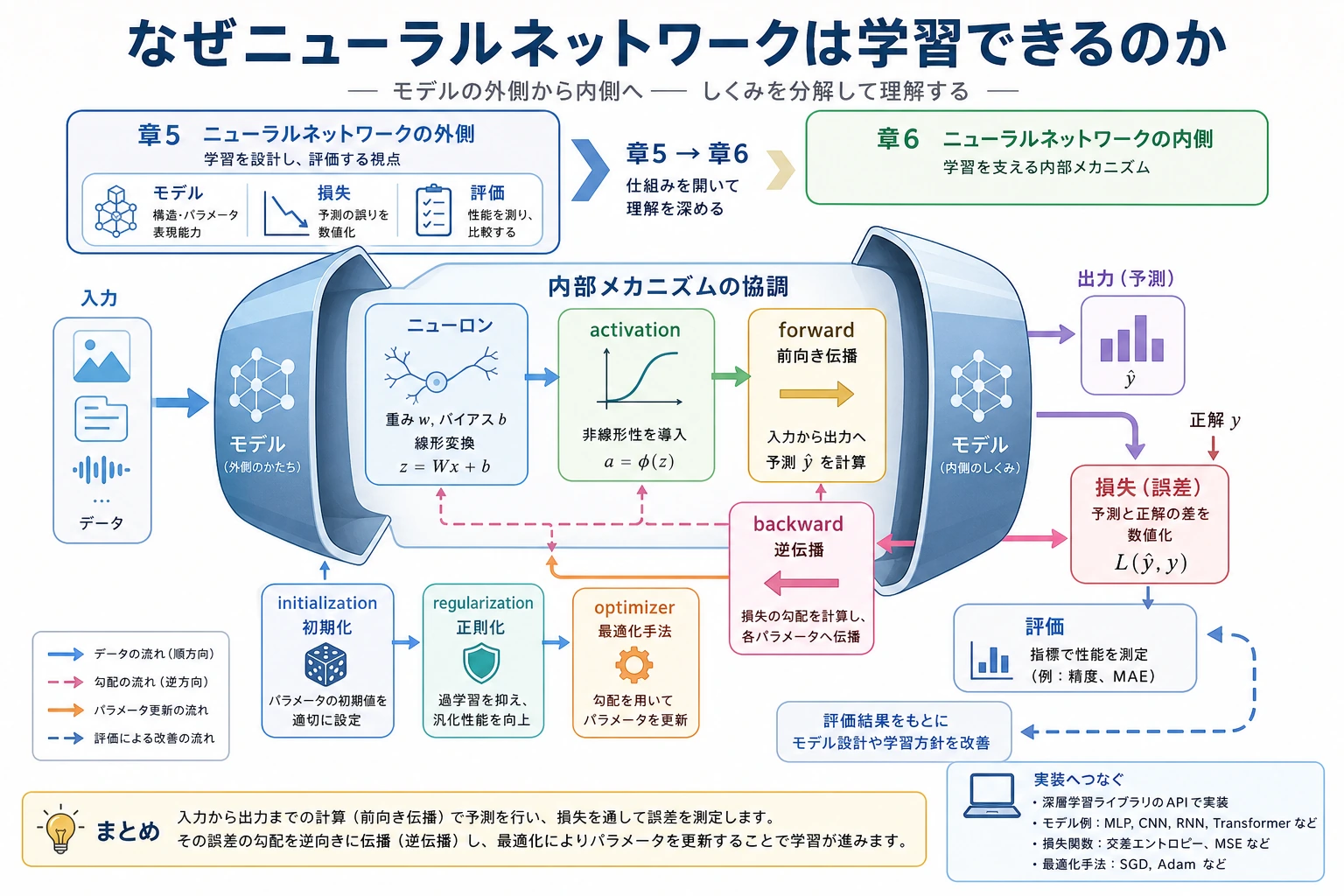
このループを覚えます。
入力 -> 重み付き和 -> 活性化 -> loss -> 勾配 -> 重み更新
| 用語 | 最初の意味 |
|---|---|
| ニューロン | 重み付き和とバイアス |
| 活性化 | ReLU などの非線形変化 |
| 順伝播 | 予測を計算する |
| 逆伝播 | 誤差への責任を計算する |
| オプティマイザ | 勾配で重みを更新する |
ニューロンを1つ動かす
nn_first_loop.py を作り、torch をインストールしてから実行します。
import torch
x = torch.tensor([[1.0, -2.0, 3.0]])
weights = torch.tensor([[0.5], [-1.0], [0.25]])
bias = torch.tensor([0.1])
linear_output = x @ weights + bias
activated = torch.relu(linear_output)
print("linear_output:", round(linear_output.item(), 3))
print("relu_output:", round(activated.item(), 3))
出力:
linear_output: 3.35
relu_output: 3.35
線形出力が負なら、ReLU はそれを 0 にします。この小さなゲートによって、多層ネットワークは非線形パターンを表せます。
この順番で学ぶ
| 順番 | 読む | まず見ること |
|---|---|---|
| 1 | 6.1.2 ML から DL へ | sklearn の後に何が変わるか |
| 2 | 6.1.3 ニューロンと活性化 | 重み付き和、バイアス、ReLU |
| 3 | 6.1.4 順伝播と逆伝播 | 予測、loss、勾配 |
| 4 | 6.1.5 オプティマイザ | SGD、Momentum、Adam の直感 |
| 5 | 6.1.6 正則化 | 過学習を抑える |
| 6 | 6.1.7 重み初期化 | 安定した開始点 |
| 7 | 6.1.8 任意の歴史背景 | backprop、CNN、RNN、Attention、Transformer がなぜ現れたか |
合格ライン
1つの層を input @ weights + bias として説明し、活性化が何をするかを言え、loss、勾配、オプティマイザを1つの学習ループとしてつなげられれば合格です。