6.3.1 CNN Roadmap: Turn Images Into Feature Maps
CNNs learn local visual patterns. Instead of reading an image as one flat row of numbers, they scan small regions and build feature maps.
Look at the Image Flow First
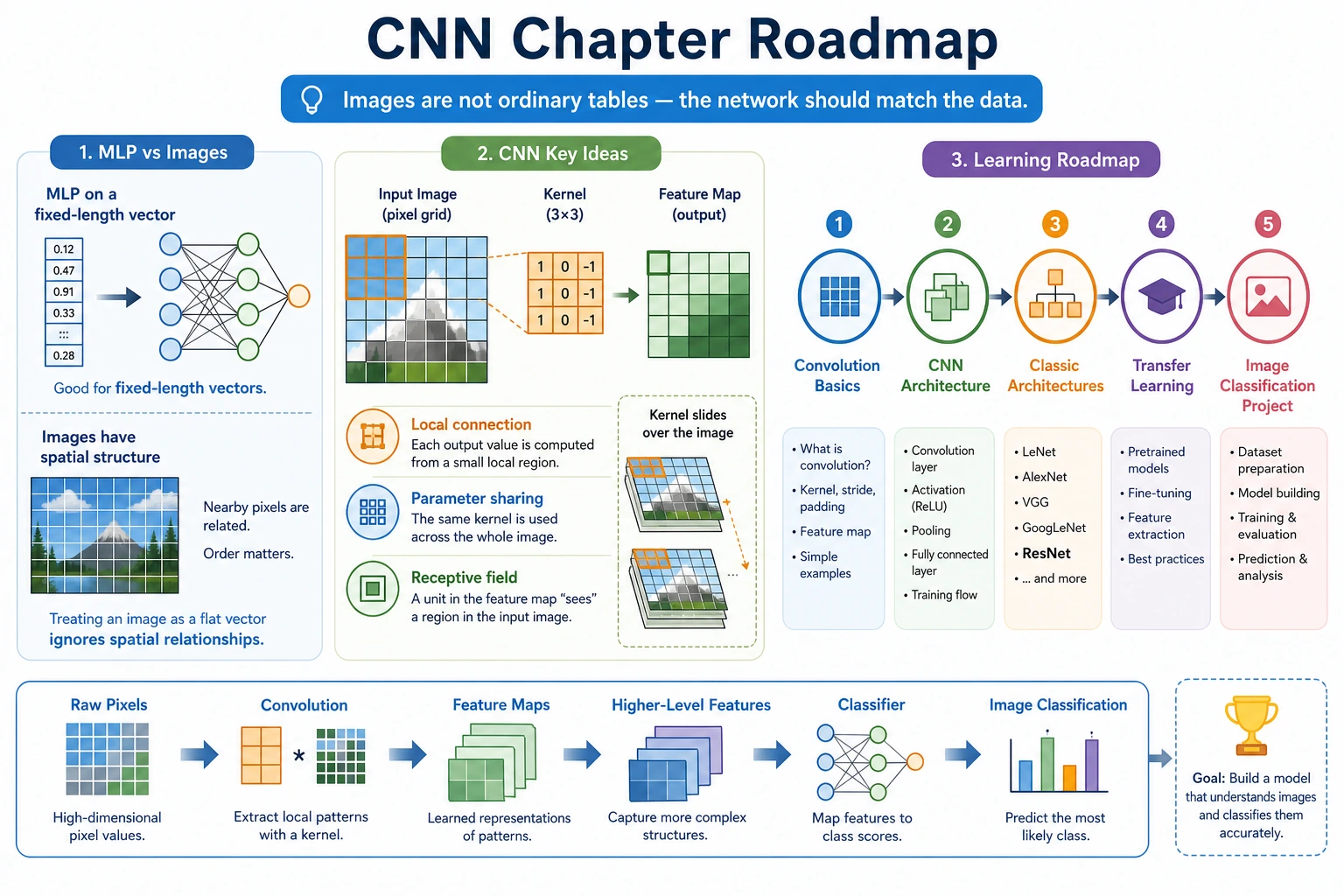
| Concept | First meaning |
|---|---|
| channel | color or learned feature dimension |
| kernel | small sliding filter |
| feature map | output after filters scan the image |
| pooling / stride | shrink spatial size |
| transfer learning | reuse a pretrained vision backbone |
Run One Convolution
Create cnn_first_loop.py and run it after installing torch.
import torch
image = torch.randn(1, 3, 32, 32)
conv = torch.nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, padding=1)
features = conv(image)
print("input_shape:", tuple(image.shape))
print("feature_shape:", tuple(features.shape))
Expected output:
input_shape: (1, 3, 32, 32)
feature_shape: (1, 8, 32, 32)
Read the shape as [batch, channels, height, width]. The convolution changed 3 input channels into 8 learned feature channels.
Learn in This Order
| Order | Read | What to practice |
|---|---|---|
| 1 | 6.3.2 Convolution Basics | kernel, stride, padding, channel |
| 2 | 6.3.3 CNN Structure | conv block, pooling, classifier head |
| 3 | 6.3.4 Classic Architectures | LeNet, AlexNet, VGG, ResNet intuition |
| 4 | 6.3.5 Transfer Learning | frozen backbone, fine-tuning |
| 5 | 6.3.6 Image Classification Practice | dataset, training, prediction examples |
Pass Check
You pass this roadmap when you can explain what changed between input image shape and feature map shape, and why pretrained CNN backbones are useful for small datasets.