6.5.2 Attention 機構
RNN は情報を一歩ずつ渡します。Attention は、1 つの token が他の token を直接見て、どれが重要かを判断できるようにします。これが Transformer の中心的な転換です。
学習目標
- Attention が長距離依存に役立つ理由を説明できる。
- Query、Key、Value を検索の比喩で理解できる。
- scaled dot-product attention を手で計算できる。
- 未来を見ないための causal mask を適用できる。
- PyTorch の
nn.MultiheadAttentionの shape を読める。
まず Q/K/V を見る
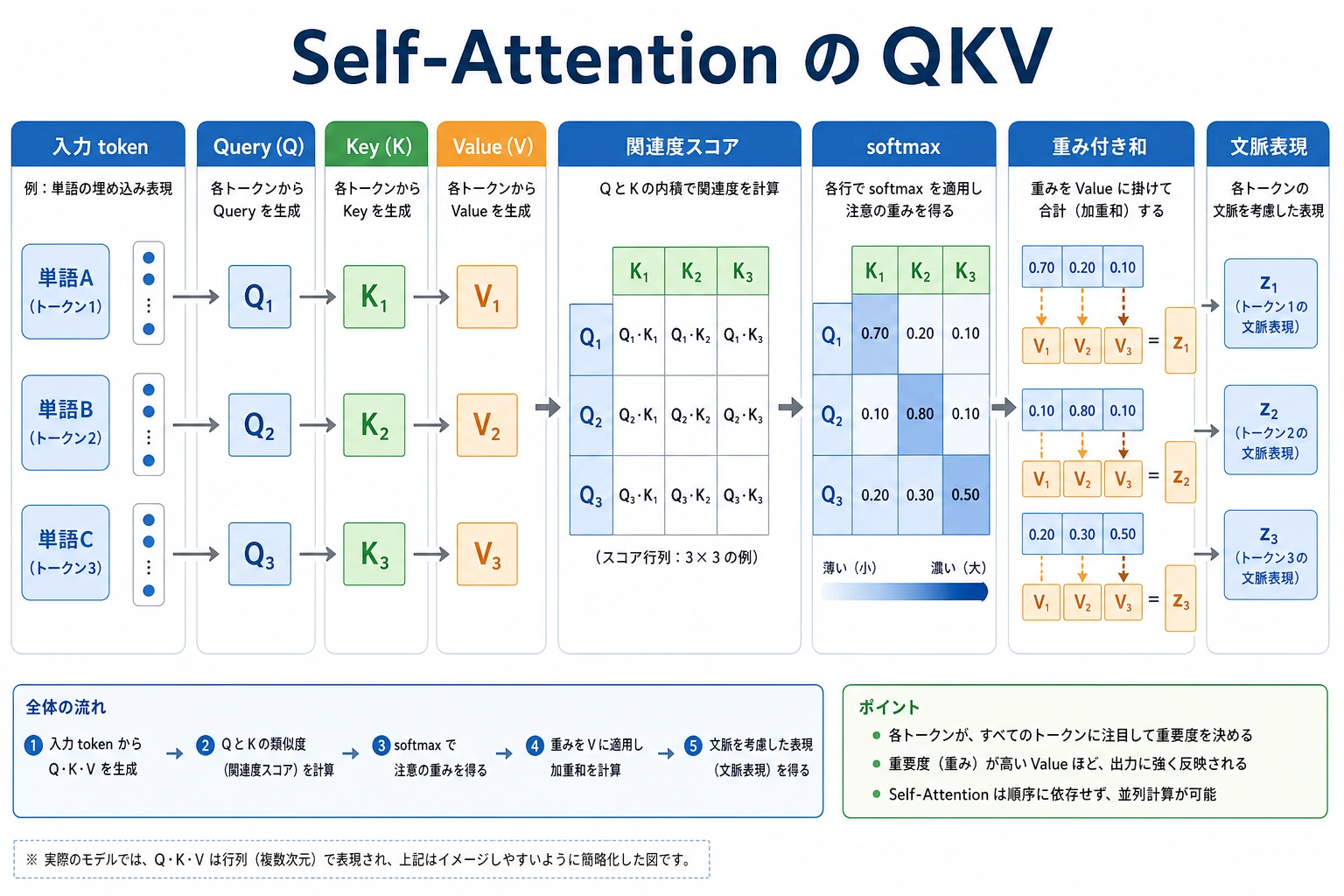
Attention は重み付き検索として読むと分かりやすいです。
Q が質問する -> K と照合する -> softmax が重みにする -> V が内容を返す -> 重み付きで足し合わせる
検索の比喩:
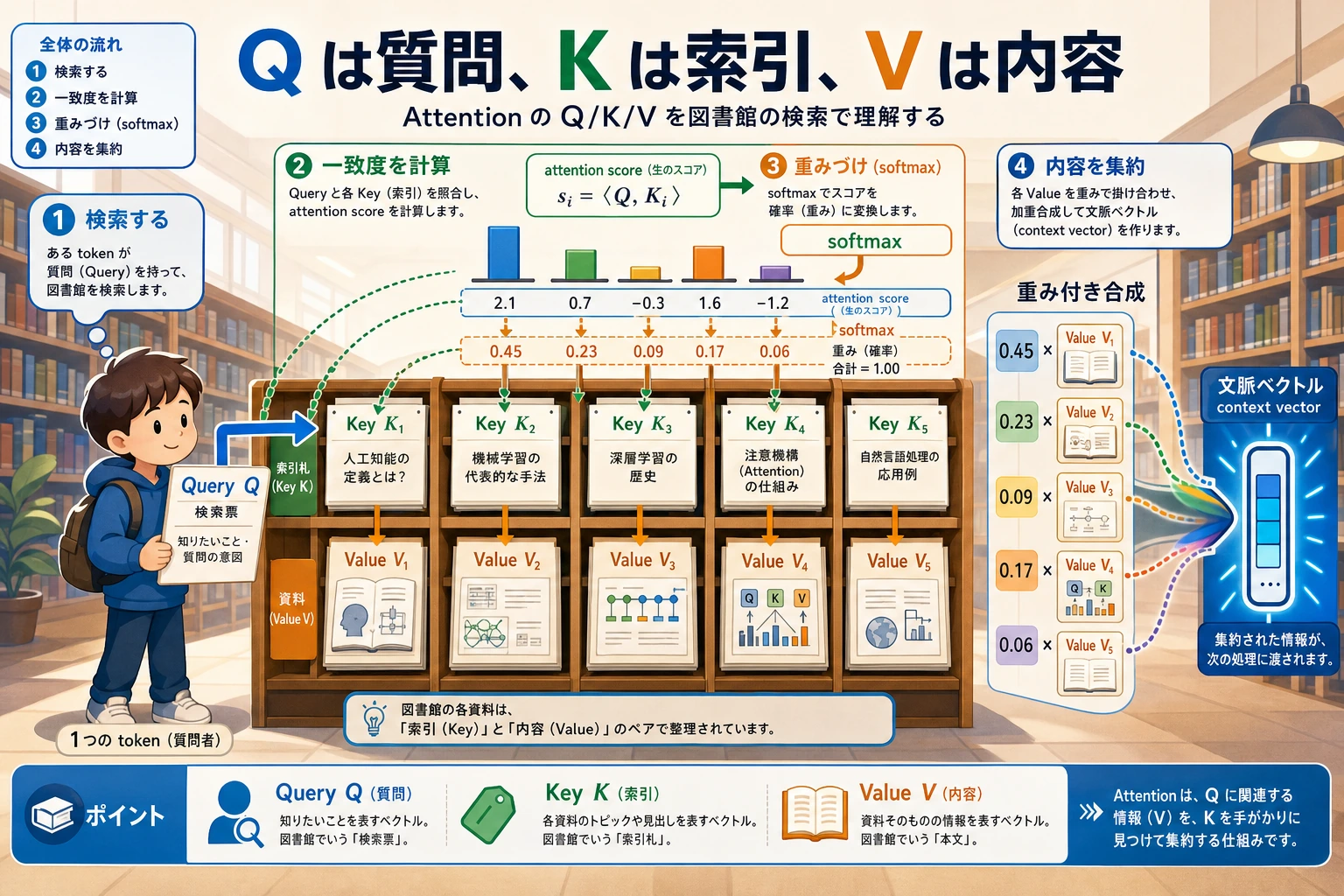
| 役割 | 直感 | Attention での意味 |
|---|---|---|
Query Q | 何を探しているか | 現在の token の質問 |
Key K | 各項目が何に合うか | スコア計算に使う索引 |
Value V | 返すべき内容 | 実際に混ぜられる情報 |
一文でいうと:
Q が K とスコアを作り、その重みで V を混ぜる。
なぜ Attention が必要だったのか
古い系列モデルでは、遠い情報は多くの recurrent step を通るか、1 つの固定ベクトルに圧縮される必要がありました。Attention はその経路を短くします。
現在の token -> すべての token に直接スコアを付ける -> 役立つ文脈を選ぶ
実務上の利点は 3 つあります。
- 長距離の token 同士を直接つなげられる。
- 一歩ずつ処理する RNN より並列学習しやすい。
- token-to-token の混合重み行列を観察できる。
実験 1:Attention を手で計算する
学習用に、ここでは Q = K = V = X とします。
import numpy as np
X = np.array(
[
[1.0, 0.0],
[0.0, 1.0],
[1.0, 1.0],
]
)
Q = K = V = X
scores = Q @ K.T
scaled_scores = scores / np.sqrt(K.shape[1])
def softmax(row):
e = np.exp(row - row.max())
return e / e.sum()
weights = np.apply_along_axis(softmax, 1, scaled_scores)
output = weights @ V
print("attention_lab")
print("scores")
print(np.round(scores, 3))
print("weights")
print(np.round(weights, 3))
print("output")
print(np.round(output, 3))
期待される出力:
attention_lab
scores
[[1. 0. 1.]
[0. 1. 1.]
[1. 1. 2.]]
weights
[[0.401 0.198 0.401]
[0.198 0.401 0.401]
[0.248 0.248 0.503]]
output
[[0.802 0.599]
[0.599 0.802]
[0.752 0.752]]
3 つの手順で読みます。
| 手順 | コード | 意味 |
|---|---|---|
| スコア | Q @ K.T | 各 token が各 token とどれくらい合うか |
| 正規化 | softmax(...) | スコアを合計 1 の重みに変える |
| 混合 | weights @ V | 重みに従って token の内容を組み合わせる |
なぜ sqrt(d_k) で割るのか
Transformer の式は次の形です。
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
ベクトルの次元が大きくなると、dot product の値も大きくなりやすくなります。大きすぎるスコアは softmax を尖らせ、1 つの token がほとんど全重みを取ってしまいます。sqrt(d_k) で割るとスコアが穏やかになり、学習が安定しやすくなります。
Self-Attention
Self-attention では、Q、K、V がすべて同じ系列から来ます。つまり、各 token が同じ系列内のすべての token を見ることができます。
例:
"Alex gave Sam the notebook because he trusted him."
「he」や「him」を理解するには、現在の token だけでなく他の token が必要です。Self-attention はそこへ直接つながる経路を作ります。
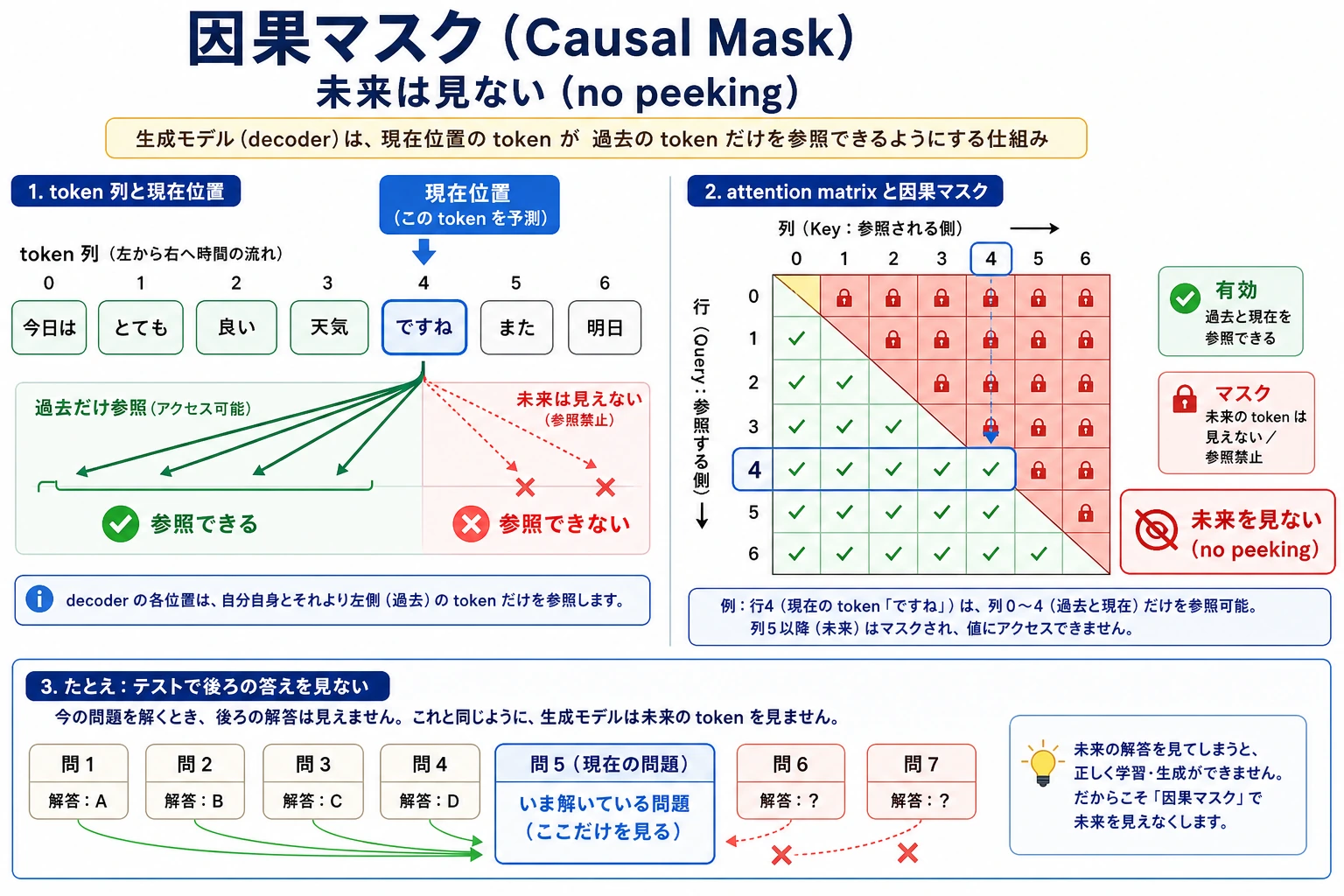
実験 2:Causal Mask
生成タスクでは未来の token を見てはいけません。causal mask は下三角だけを見えるようにします。
import numpy as np
scores = np.array(
[
[2.0, 1.0, 0.5],
[1.2, 2.1, 0.7],
[0.8, 1.3, 2.2],
]
)
mask = np.tril(np.ones_like(scores))
masked_scores = np.where(mask == 1, scores, -1e9)
def softmax(row):
e = np.exp(row - row.max())
return e / e.sum()
weights = np.apply_along_axis(softmax, 1, masked_scores)
print("mask_lab")
print(np.round(weights, 3))
期待される出力:
mask_lab
[[1. 0. 0. ]
[0.289 0.711 0. ]
[0.149 0.246 0.605]]
読み方:
- 位置 1 は自分だけを見る。
- 位置 2 は位置 1 と 2 を見る。
- 位置 3 は位置 1、2、3 を見る。
未来の答えは見えません。
Multi-Head Attention
1 つの attention head は、1 種類の関係を学ぶことがあります。multi-head attention は、複数の関係空間を並列に見る仕組みです。
head によって注目しやすいものは異なります。
- 近い位置のパターン。
- 主語と目的語の関係。
- 繰り返し出てくる語。
- 長距離の参照。
複数 head の結果は結合され、もう一度 1 つの表現へ射影されます。
実験 3:PyTorch MultiheadAttention
import torch
from torch import nn
torch.manual_seed(42)
attention = nn.MultiheadAttention(embed_dim=8, num_heads=2, batch_first=True)
tokens = torch.randn(1, 4, 8)
output, weights = attention(tokens, tokens, tokens)
print("mha_lab")
print("tokens:", tuple(tokens.shape))
print("output:", tuple(output.shape))
print("weights:", tuple(weights.shape))
print("row0_sum:", round(float(weights[0, 0].sum().detach()), 4))
期待される出力:
mha_lab
tokens: (1, 4, 8)
output: (1, 4, 8)
weights: (1, 4, 4)
row0_sum: 1.0
shape の読み方:
| Tensor | Shape | 意味 |
|---|---|---|
tokens | [1, 4, 8] | batch 1、4 token、embedding size 8 |
output | [1, 4, 8] | 各 token が文脈を含んだ新しい表現になる |
weights | [1, 4, 4] | 各 query token が 4 個の key token に重みを配る |
Attention 重みは完全な説明ではない
Attention 重みは便利ですが、言い過ぎには注意します。
分かること:
この layer/head では、この query がそれらの key 位置からより多くの value を混ぜた
自動的には証明できないこと:
モデルの最終判断は、その token が原因だった
Attention 重みは調査とデバッグの道具として使います。完全な因果説明として扱わないでください。
よくある間違い
| 間違い | 直し方 |
|---|---|
| Q/K/V を謎の変数として覚える | 質問 / 索引 / 内容として読む |
| shape の意味を追わない | [batch, seq_len, embed_dim] と attention [batch, query, key] を追う |
| 生成で mask を使わない | causal mask で未来 token を隠す |
softmax を間違った次元にかける | key 位置の方向で正規化する |
| Attention を推論の魔法だと思う | スコア -> softmax -> 重み付き和として読む |
練習
- 実験 1 の 3 番目の token を
[2.0, 0.0]に変えてください。weights はどう変わりますか。 - mask の実験を
4 x 4行列に拡張してください。 - 実験 3 で
num_headsを2から1に変えてください。どの shape が同じままですか。 - 普通の RNN より Attention が長距離 token の相互作用を扱いやすい理由を説明してください。
- Attention 重みが役立つが、完全な説明ではない場面を 1 つ説明してください。
まとめ
- Attention は token が関連する文脈を直接選べるようにする。
- Q/K/V はスコア付けと内容取得を分ける。
- scaled dot-product attention は、スコア、softmax、重み付き和でできている。
- causal mask は生成時の未来の覗き見を防ぐ。
- multi-head attention は複数の部分空間から関係を見る。