6.1.7 重みの初期化
初期化は、ニューラルネットワークが学習開始時に使える信号を持てるかどうかを決めます。通常は PyTorch のデフォルトから始めれば十分ですが、学習がおかしいときに Xavier、He、全ゼロ、小さすぎる初期化、大きすぎる初期化を確認できるようにしておきましょう。
学習目標
- 全ゼロの重みがなぜ学習を壊すのか説明できる。
- Tanh/Sigmoid には Xavier、ReLU 系には He を選べる。
- 学習前に信号プローブを実行できる。
- 小さな分類タスクで初期化の違いを比較できる。
- 早期の学習不安定を、手当たり次第ではなく順番に切り分けられる。
まず図を見る
式を覚える前に、初期化の役割を見ておきます。
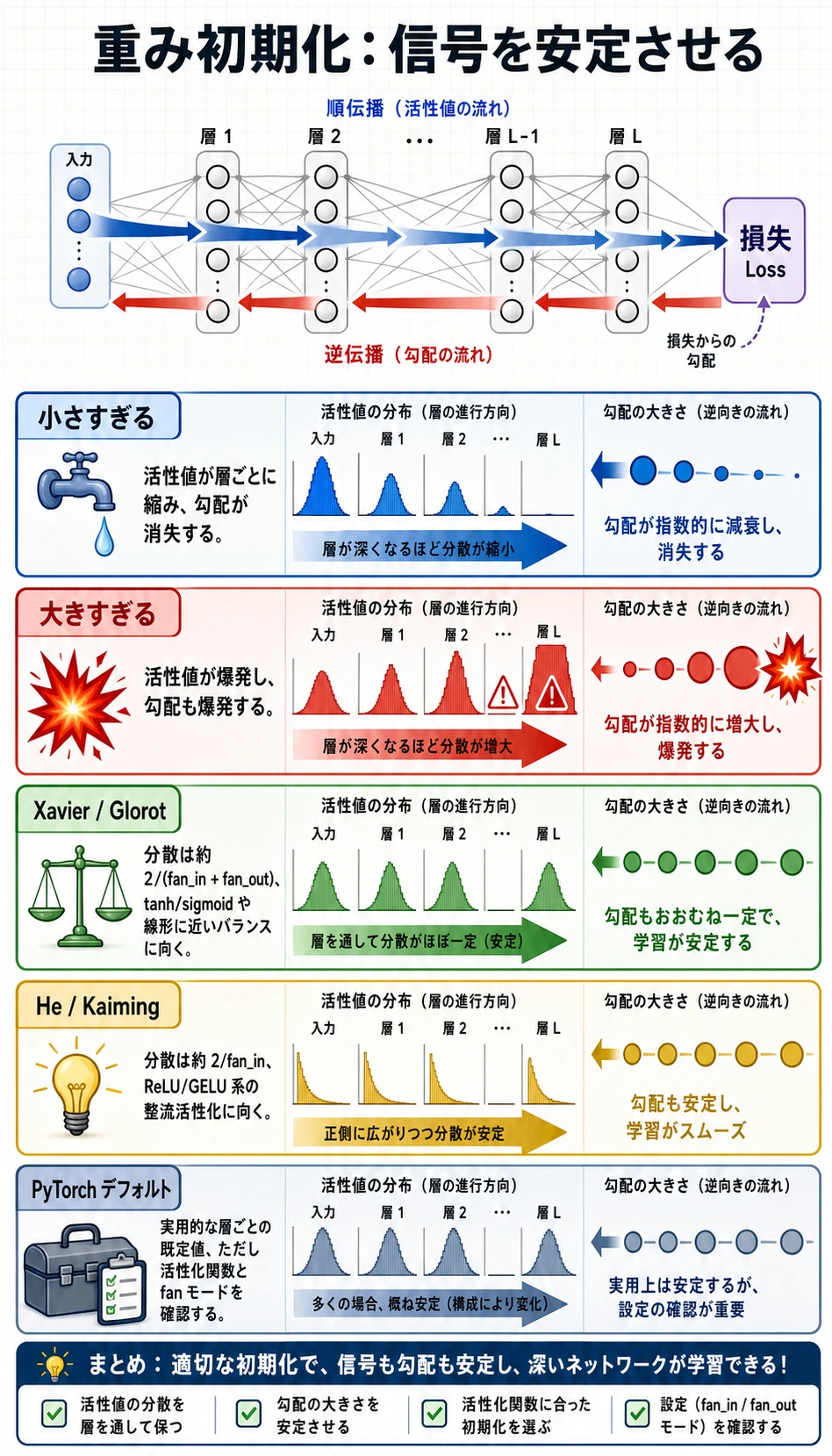
この図は上から順に読みます。
- 順伝播の信号が層ごとに消えてはいけない。
- 活性値が最初から広く飽和してはいけない。
- 逆伝播の勾配が戻る道を残す必要がある。
- 通常の
nn.Linearやnn.Conv2dモデルでは、まず PyTorch のデフォルトがよい出発点になる。
最小限の考え方
ニューラルネットワークの学習は、おおまかに次のループです。
- 重みを初期化する。
- 順伝播する。
- 損失を計算する。
- 逆伝播する。
- 最適化手法で重みを更新する。
もし 1 番目が壊れていると、後の処理は動いていても、悪い出発点から走っていることになります。
よくある失敗はシンプルです。
| 悪い出発点 | 何が起きるか | 何が見えるか |
|---|---|---|
| 全ゼロ | ニューロンが同じままになる | loss が下がらない |
| 小さすぎる | 信号が深さとともに弱くなる | 深い層の出力がほぼ 0 |
| 大きすぎる | 活性値が飽和または爆発する | 初期 loss が大きい、勾配が不安定 |
| 初期化と活性化のミスマッチ | 非線形後のスケールが合わない | 学習が遅い、壊れやすい |
先に知っておきたい用語は 2 つです。
fan_in: その層に入ってくる入力特徴量の数。fan_out: その層から出ていく出力特徴量の数。
初期化の式は、これらを使って各層のスケールを整えます。
Xavier と He は表で覚える
最初からすべての式を暗記する必要はありません。まず対応関係を覚えます。
| 活性化関数 | よく使う選択 | PyTorch ヘルパー | 理由 |
|---|---|---|---|
| Tanh / Sigmoid | Xavier、別名 Glorot | nn.init.xavier_normal_ | 入力と出力の分散をできるだけそろえる |
| ReLU / Leaky ReLU | He、別名 Kaiming | nn.init.kaiming_normal_ | ReLU が多くの値を 0 にする分を補う |
| 通常の PyTorch モデルで迷う | PyTorch デフォルト | 手動初期化を書かない | 最初の baseline に向いている |
普通の新規プロジェクトでは、最初からすべての層を手動初期化しなくてかまいません。まず PyTorch デフォルトを使い、学習率とデータ処理が正しいことを確認します。そのうえで信号や勾配が明らかにおかしいなら、初期化を調べます。
実験準備
Notebook のセルで実行しても、weight_init_lab.py として保存しても構いません。
パッケージが足りない場合はインストールします。
pip install torch scikit-learn
実験 1: 学習前に信号を確認する
この実験では、ランダムデータを 8 層ネットワークに通し、最初の層と最後の層の活性値統計を表示します。目的は精度ではなく、信号が深い層まで残るかを見ることです。
import torch
import torch.nn as nn
torch.manual_seed(7)
def build_probe(activation):
layers = []
in_features = 32
for _ in range(8):
layer = nn.Linear(in_features, 128)
layers.append(layer)
layers.append(activation())
in_features = 128
return nn.Sequential(*layers)
def apply_init(model, strategy):
for module in model:
if isinstance(module, nn.Linear):
if strategy == "tiny":
nn.init.normal_(module.weight, 0.0, 0.01)
elif strategy == "large":
nn.init.normal_(module.weight, 0.0, 1.0)
elif strategy == "xavier":
nn.init.xavier_normal_(module.weight)
elif strategy == "he":
nn.init.kaiming_normal_(module.weight, mode="fan_in", nonlinearity="relu")
nn.init.zeros_(module.bias)
def probe(strategy, activation_cls):
model = build_probe(activation_cls)
apply_init(model, strategy)
x = torch.randn(512, 32)
stats = []
for layer in model:
x = layer(x)
if isinstance(layer, activation_cls):
stats.append(
{
"mean": x.mean().item(),
"std": x.std().item(),
"zero_ratio": (x == 0).float().mean().item(),
"saturated_ratio": (x.abs() > 0.98).float().mean().item(),
}
)
return stats[0], stats[-1]
print("signal_probe")
for label, strategy, activation in [
("tiny + ReLU", "tiny", nn.ReLU),
("large + Tanh", "large", nn.Tanh),
("Xavier + Tanh", "xavier", nn.Tanh),
("He + ReLU", "he", nn.ReLU),
]:
first, last = probe(strategy, activation)
print(
f"{label:14s} "
f"first_std={first['std']:.4f} "
f"last_std={last['std']:.4f} "
f"last_zero={last['zero_ratio']:.2f} "
f"last_saturated={last['saturated_ratio']:.2f}"
)
期待される出力:
signal_probe
tiny + ReLU first_std=0.0337 last_std=0.0000 last_zero=0.52 last_saturated=0.00
large + Tanh first_std=0.9273 last_std=0.9633 last_zero=0.00 last_saturated=0.84
Xavier + Tanh first_std=0.4872 last_std=0.2276 last_zero=0.00 last_saturated=0.00
He + ReLU first_std=0.8304 last_std=0.6937 last_zero=0.49 last_saturated=0.19
読み方:
tiny + ReLU: 最後の層の標準偏差がほぼ 0 で、深い層の信号が消えています。large + Tanh: 多くの値が -1 または 1 に近く、Tanh の勾配が弱くなります。Xavier + Tanh: 信号のスケールが比較的コントロールされています。He + ReLU: ReLU は自然に 0 を多く作りますが、信号は深い層まで届いています。
実験 2: 小さな分類器を学習する
次に、同じ考え方を実際の学習で比べます。これは小さな 2 クラスの toy データなので、悪い出発点でも回復することがあります。大事なのは、初期 loss と全ゼロ初期化が止まるかどうかです。
import torch
import torch.nn as nn
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
torch.manual_seed(9)
X, y = make_moons(n_samples=600, noise=0.22, random_state=9)
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
train_idx, val_idx = train_test_split(
torch.arange(len(X)),
test_size=0.25,
random_state=9,
stratify=y,
)
X_train, y_train = X[train_idx], y[train_idx]
X_val, y_val = X[val_idx], y[val_idx]
class MoonMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 2),
)
def forward(self, x):
return self.net(x)
def apply_init(model, strategy):
if strategy == "default":
return
for module in model.modules():
if isinstance(module, nn.Linear):
if strategy == "zeros":
nn.init.zeros_(module.weight)
elif strategy == "tiny":
nn.init.normal_(module.weight, 0.0, 0.01)
elif strategy == "large":
nn.init.normal_(module.weight, 0.0, 1.0)
elif strategy == "xavier":
nn.init.xavier_normal_(module.weight)
elif strategy == "he":
nn.init.kaiming_normal_(module.weight, mode="fan_in", nonlinearity="relu")
nn.init.zeros_(module.bias)
def accuracy(model, X, y):
with torch.no_grad():
preds = model(X).argmax(dim=1)
return (preds == y).float().mean().item()
def train_once(strategy):
torch.manual_seed(9)
model = MoonMLP()
apply_init(model, strategy)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
start_loss = loss_fn(model(X_train), y_train).item()
for _ in range(120):
loss = loss_fn(model(X_train), y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
end_loss = loss_fn(model(X_train), y_train).item()
return start_loss, end_loss, accuracy(model, X_val, y_val)
print("training_probe")
for strategy in ["default", "zeros", "tiny", "large", "xavier", "he"]:
start, end, acc = train_once(strategy)
print(f"{strategy:8s} start_loss={start:.3f} end_loss={end:.3f} val_acc={acc:.3f}")
期待される出力:
training_probe
default start_loss=0.671 end_loss=0.047 val_acc=0.973
zeros start_loss=0.693 end_loss=0.693 val_acc=0.500
tiny start_loss=0.693 end_loss=0.067 val_acc=0.973
large start_loss=20.040 end_loss=0.068 val_acc=0.980
xavier start_loss=0.696 end_loss=0.046 val_acc=0.980
he start_loss=0.924 end_loss=0.053 val_acc=0.980
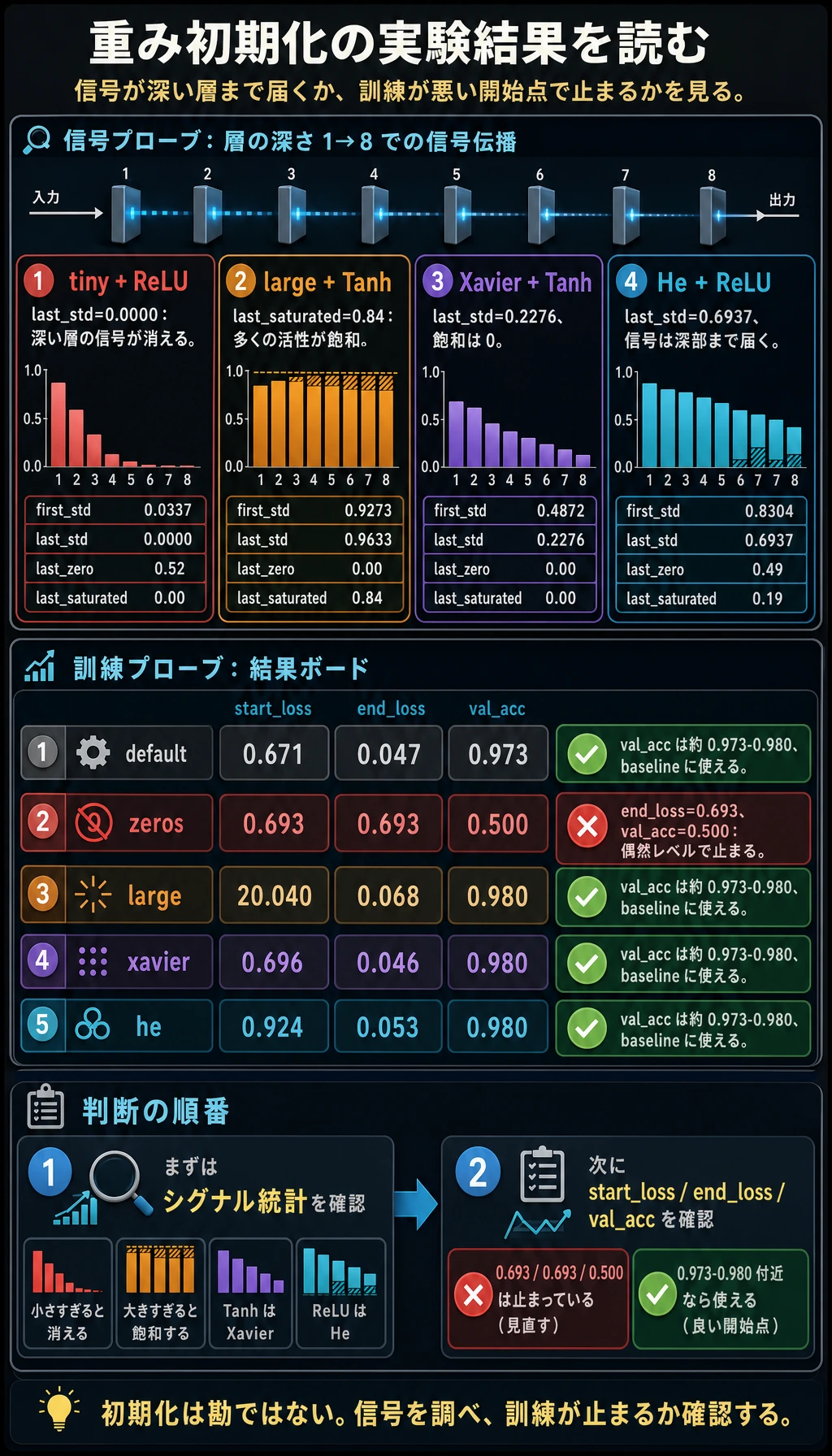
見るべきポイント:
zerosは止まります。隠れ層のニューロンが最初から互いのコピーだからです。largeは初期 loss が非常に大きく、この小さなモデルが後で回復しても警告サインです。default、xavier、heはここではどれも動きます。だからこそデフォルトは最初の baseline に向いています。
デバッグチェックリスト
最初の数 epoch で明らかにおかしいときは、次の順番で確認します。
- データ shape は正しいか?
- 目的変数の dtype は正しいか?
CrossEntropyLossはtorch.longのクラスラベルを期待します。 - 学習率が高すぎないか?
- 活性値の大部分が 0、飽和、
nan、infになっていないか? - 初期化と活性化関数の組み合わせは合っているか?
推測で変えず、小さなプローブを使います。
with torch.no_grad():
sample = X_train[:32]
out = model(sample)
print(out.mean().item(), out.std().item(), torch.isfinite(out).all().item())
出力が有限でない、またはほぼすべて同じ値なら、初期化、入力スケーリング、学習率をまとめて確認します。
練習
- 信号プローブのネットワーク深さを 8 から 20 に変えてください。どの初期化が最初に失敗しますか?
MoonMLPの ReLU を Tanh に変えてください。Xavier はより有利になりますか?- Adam を
lr=0.1の SGD に変えてください。どの初期化が壊れやすくなりますか?
まとめ
- 初期化は、順伝播の信号と逆伝播の勾配の出発条件です。
- 全ゼロ重みは対称性を壊せないため、隠れ層には使いません。
- Xavier は Tanh/Sigmoid に、He は ReLU 系の活性化に向いています。
- PyTorch デフォルトは多くの場合よい最初の一手ですが、学習がおかしいときは信号プローブで確認します。