6.1.8 Optional Background: Deep Learning Breakthroughs
Section Overview
This page is a short map, not a history exam. Use it to answer one question for each model name:
What problem did this breakthrough solve that the previous idea could not solve well?
Look at the Timeline First
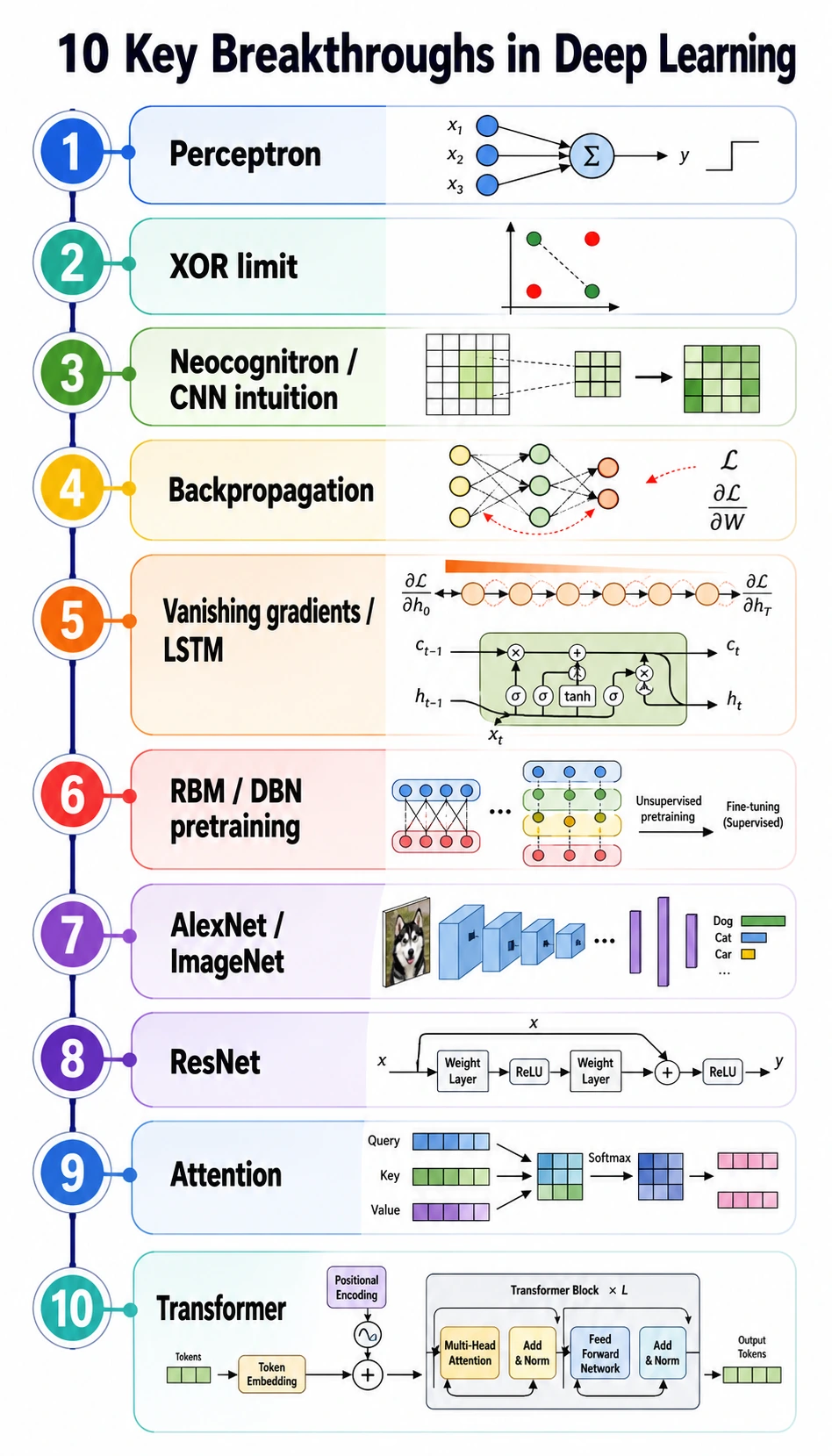
Read the timeline as a chain:
simple neuron -> linear limits -> trainable multi-layer network -> stable deep training -> scalable vision -> attention-based sequence modeling
If you remember that chain, the architectures in Chapter 6 will feel less like isolated names.
The Three Big Shifts
| Shift | Main hope | Main bottleneck | What unlocked the next stage |
|---|---|---|---|
| Early neural networks | machines can learn from data | single-layer models are too weak | hidden layers and backpropagation |
| Trainable deep networks | multi-layer models can learn representations | gradients vanish, data and compute are limited | LSTM, initialization, pretraining ideas |
| Modern deep learning | data, GPUs, and architectures scale together | very deep models and long dependencies are hard | AlexNet, ResNet, Attention, Transformer |
This is why Chapter 6 teaches foundations before architectures:
| If you see this historical problem | Review this course section |
|---|---|
| one neuron is too limited | 6.1.3 Neurons and Activation |
| multi-layer networks need gradients | 6.1.4 Forward and Backward |
| training becomes unstable | 6.1.5 Optimizers, 6.1.6 Regularization, 6.1.7 Initialization |
| images need local features | CNN sections later in Chapter 6 |
| sequences need memory or attention | RNN, LSTM, Attention, and Transformer sections |
Ten Breakthroughs to Remember
| Time | Breakthrough | Problem it solved | Course meaning |
|---|---|---|---|
| 1943-1958 | artificial neuron and perceptron | made learning parameters from samples imaginable | a neuron is weighted sum plus decision |
| 1969 | XOR limitation | showed a single linear layer is not enough | hidden layers and nonlinear activations matter |
| 1980 | Neocognitron | introduced local visual features and hierarchy | CNNs look at local patterns first |
| 1986 | backpropagation | made multi-layer networks trainable | loss.backward() is the modern form of this idea |
| 1989 | universal approximation | showed nonlinear networks can represent complex functions | expressiveness needs depth and activation |
| 1994-1997 | vanishing gradients and LSTM | made long sequence memory more practical | gates help information survive time |
| 2006 | RBM / DBN pretraining | revived interest in deep representation learning | pretraining became an important idea |
| 2012 | AlexNet / ImageNet | proved data + GPU + CNNs can dominate vision | large-scale training changed computer vision |
| 2015 | ResNet | made very deep CNNs easier to train | residual paths help gradients flow |
| 2017 | Attention / Transformer | made long-range sequence modeling parallel and scalable | the foundation of modern LLMs |
What Each Name Should Trigger in Your Mind
Use this quick memory map:
| Name | Think |
|---|---|
| Perceptron | learnable linear scoring |
| XOR | linear boundaries are limited |
| Backpropagation | assign error through the computation graph |
| LSTM / GRU | remember long sequences with gates |
| AlexNet | GPU-scale CNN breakthrough |
| ResNet | skip connections for very deep networks |
| Attention | every token can look at relevant tokens |
| Transformer | attention blocks at scale |
How to Use This Page While Studying
Do not memorize every year. Instead, do this after each Chapter 6 architecture lesson:
- Write the old bottleneck in one sentence.
- Write the new mechanism in one sentence.
- Run the chapter lab and point to the line of code that represents the mechanism.
Example:
Old bottleneck: deep CNNs are hard to optimize.
New mechanism: ResNet adds a shortcut path.
Code clue: output = block(x) + x
That small habit keeps history connected to implementation.
Quick Check
You are ready to move on when you can answer:
- Why did XOR expose the limitation of single-layer models?
- Why did backpropagation matter for multi-layer networks?
- Why did LSTM appear before Transformer?
- Why did ResNet help very deep CNNs?
- Why did Attention become the bridge to modern large language models?
If your answer begins with “because the previous model could not...”, you are reading the history in the right way.