6.1.5 オプティマイザ
この節の概要
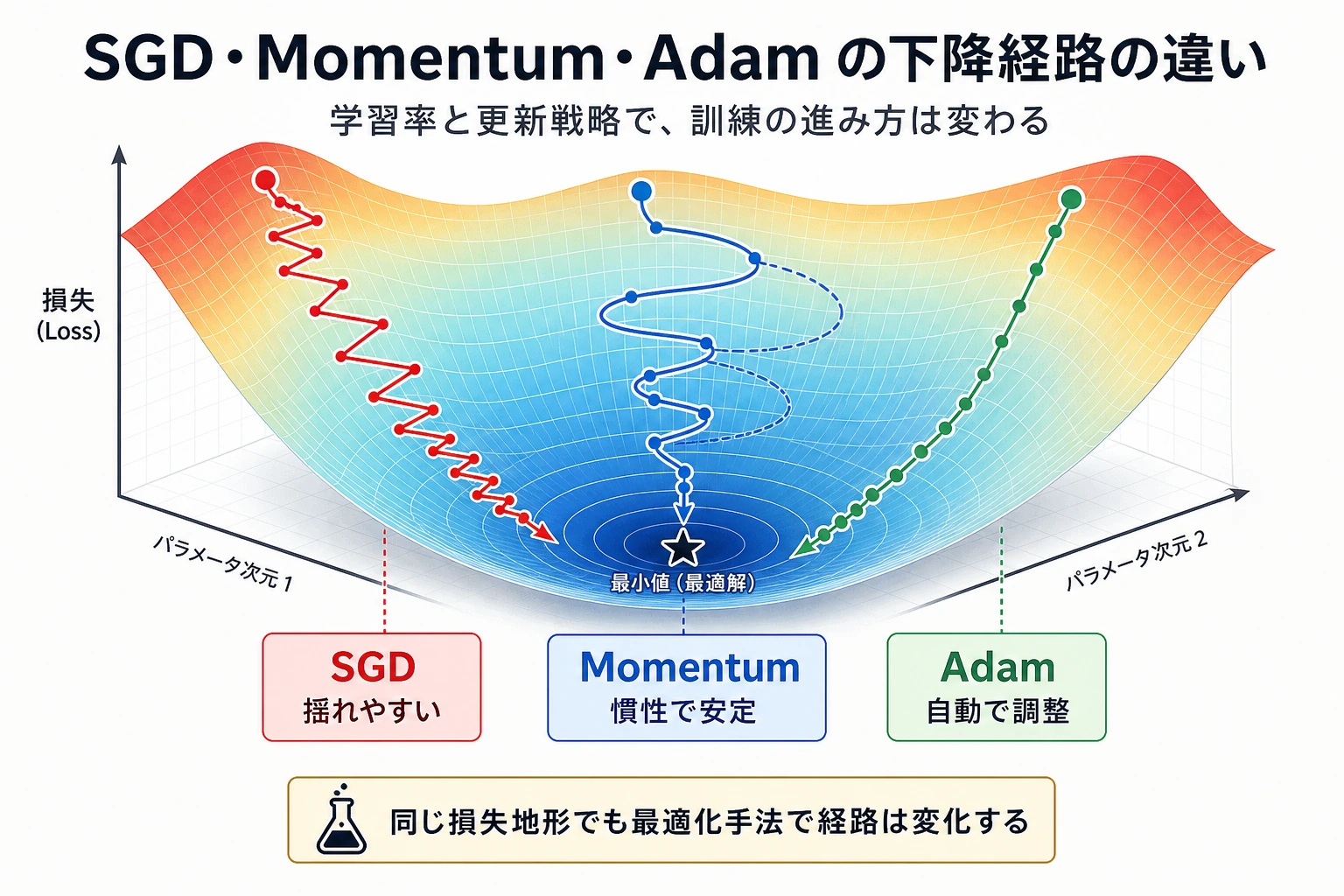
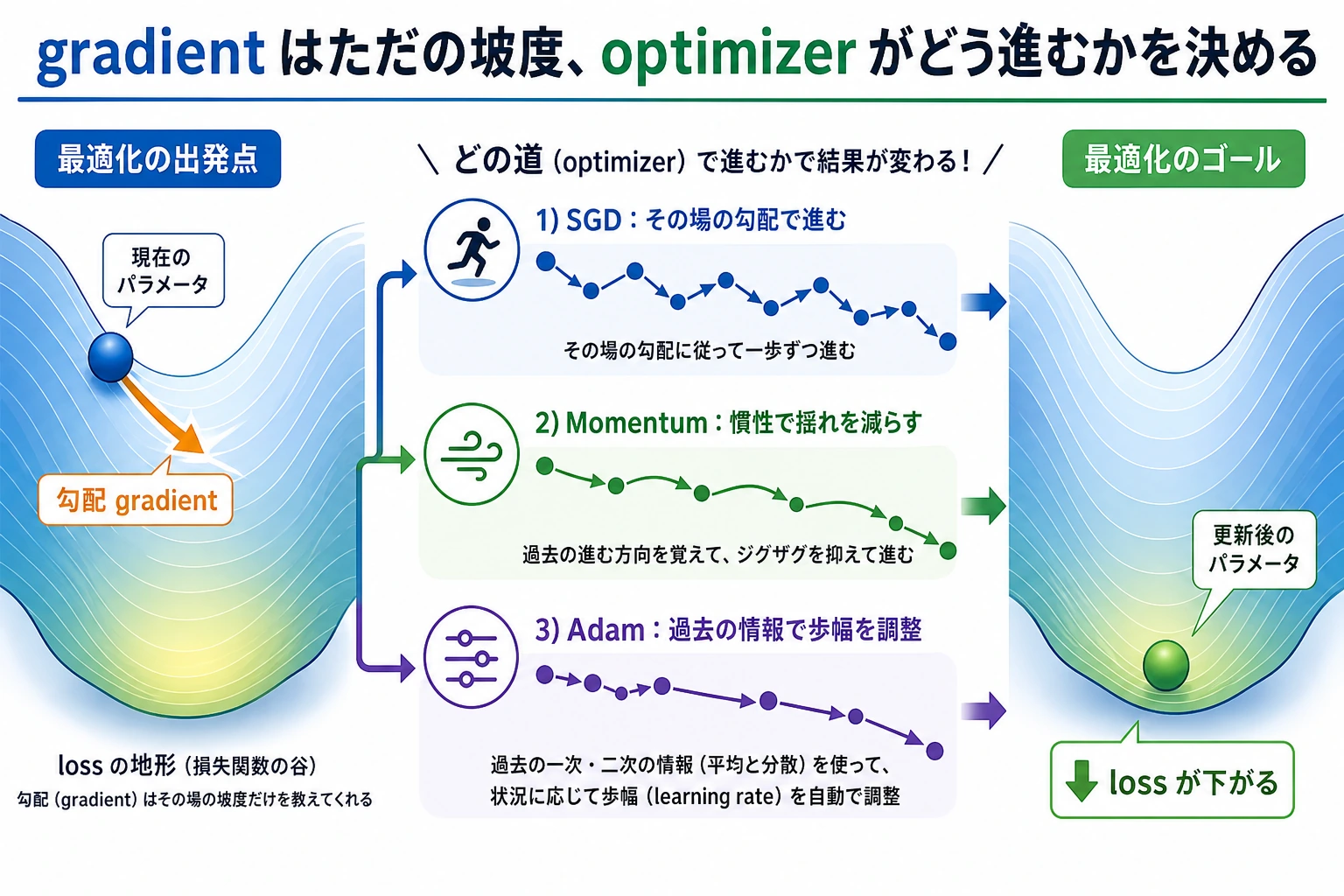
勾配が計算されたあと、パラメータをどう動かすかを決めるのがオプティマイザです。名前も重要ですが、学習率のほうが効くことも多いです。
作るもの
この節では、小さな PyTorch 最適化実験を実行します。
- 同じ単純な loss で SGD、Momentum、Adam を比較する;
- オーバーシュートを直接見る;
- 学習率の感度を確認する;
- 安全なオプティマイザ選択順を学ぶ。
セットアップ
python -m pip install -U torch
完全な実験を実行する
optimizer_lab.py を作成します。
import torch
def run_optimizer(name, optimizer_factory, steps=25):
torch.manual_seed(42)
w = torch.nn.Parameter(torch.tensor([5.0]))
optimizer = optimizer_factory([w])
for step in range(1, steps + 1):
loss = (w - 2).pow(2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step in [1, 5, 10, 25]:
print(f"{name:<8} step={step:<2} w={w.item():.3f} loss={loss.item():.4f}")
print("optimizer_comparison")
run_optimizer("sgd", lambda params: torch.optim.SGD(params, lr=0.1))
run_optimizer("momentum", lambda params: torch.optim.SGD(params, lr=0.1, momentum=0.9))
run_optimizer("adam", lambda params: torch.optim.Adam(params, lr=0.1))
print("learning_rate_check")
for lr in [0.01, 0.1, 1.1]:
torch.manual_seed(42)
w = torch.nn.Parameter(torch.tensor([5.0]))
optimizer = torch.optim.SGD([w], lr=lr)
for _ in range(10):
loss = (w - 2).pow(2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
final_loss = (w - 2).pow(2).item()
print(f"lr={lr:<4} final_w={w.item():.3f} final_loss={final_loss:.4f}")
実行します。
python optimizer_lab.py
期待される出力:
optimizer_comparison
sgd step=1 w=4.400 loss=9.0000
sgd step=5 w=2.983 loss=1.5099
sgd step=10 w=2.322 loss=0.1621
sgd step=25 w=2.011 loss=0.0002
momentum step=1 w=4.400 loss=9.0000
momentum step=5 w=0.259 loss=0.8571
momentum step=10 w=2.013 loss=0.6767
momentum step=25 w=2.475 loss=0.0200
adam step=1 w=4.900 loss=9.0000
adam step=5 w=4.502 loss=6.7648
adam step=10 w=4.014 loss=4.4535
adam step=25 w=2.739 loss=0.6569
learning_rate_check
lr=0.01 final_w=4.451 final_loss=6.0085
lr=0.1 final_w=2.322 final_loss=0.1038
lr=1.1 final_w=20.575 final_loss=345.0386

実験を読む
この loss は次です。
loss = (w - 2)^2
最良値は w=2 です。すべてのオプティマイザは w=5 から始まります。
この単純な例では、適切な学習率の SGD が非常によく動きます。
sgd step=25 w=2.011 loss=0.0002
Momentum は速く動きますが、行き過ぎることがあります。
momentum step=5 w=0.259
Adam は深層学習でよく使われる既定選択ですが、魔法ではありません。この小さな問題では、lr=0.1 の Adam は調整された SGD より遅く動きました。大事なのは「Adam が悪い」ではなく、次です。
訓練の挙動を必ず見る。オプティマイザ選択と学習率はセットで働く。
学習率が最初のつまみ
学習率の確認はあえて単純にしています。
lr=0.01 final_w=4.451 final_loss=6.0085
lr=0.1 final_w=2.322 final_loss=0.1038
lr=1.1 final_w=20.575 final_loss=345.0386
小さすぎる:学習が遅い。
ちょうどよい:最適値に近づく。
大きすぎる:発散する。
オプティマイザの直感
| オプティマイザ | 直感 | 最初に使いやすい場面 |
|---|---|---|
| SGD | 勾配の反対方向へ直接動く | 単純な基線、制御された実験 |
| SGD + Momentum | 前のステップの速度を残す | ノイズのある方向で進みやすい |
| Adam | 勾配履歴からステップ幅を調整する | 多くのニューラルネットワークの強い既定値 |
実際のニューラルネットワークでは、Adam または AdamW が実用的な出発点になることが多いです。最終的には、タスクの検証指標で比較します。
実用的な選択順
- ニューラルネットワークの基線は Adam または AdamW から始める。
- オプティマイザ名を議論する前に、学習率を調整する。
- training loss と validation loss の曲線を見る。
- validation が不安定なら、LR を下げるか schedule を入れる。
- training が遅いが安定しているなら、LR schedule や optimizer 変更を試す。
よくあるトラブル
| 症状 | よくある原因 | 修正 |
|---|---|---|
| loss が爆発する | 学習率が高すぎる | LR を下げる |
| loss が遅くしか下がらない | LR が低すぎる、または入力尺度が悪い | LR を慎重に上げ、入力を正規化する |
| training loss は下がるが validation が悪化 | オーバーフィット | 正則化、データ追加、早期停止 |
| loss が振動する | momentum/LR が強すぎる | LR または momentum を下げる |
| Adam は動くが最終品質が弱い | optimizer が他の問題を隠している | データ、構造、正則化を確認する |
練習
- SGD の学習率を
0.05、0.2、0.8に変えてください。 - momentum を
0.9から0.5に変えてください。オーバーシュートは減りますか? AdamをAdamWに置き換えてください。- 各 step で
w.gradを表示し、勾配と更新を結びつけてください。 - 各オプティマイザの
wの変化をグラフにしてください。
合格チェック
次を説明できれば、この節はクリアです。
- 勾配は loss を変える方向を示す;
- オプティマイザはパラメータをどれだけ動かすかを決める;
- 学習率は訓練を遅くしたり、収束させたり、発散させたりする;
- momentum は速くできるが、行き過ぎることもある;
- Adam は便利だが、訓練曲線の確認の代わりにはならない。