6.1.5 Optimizers
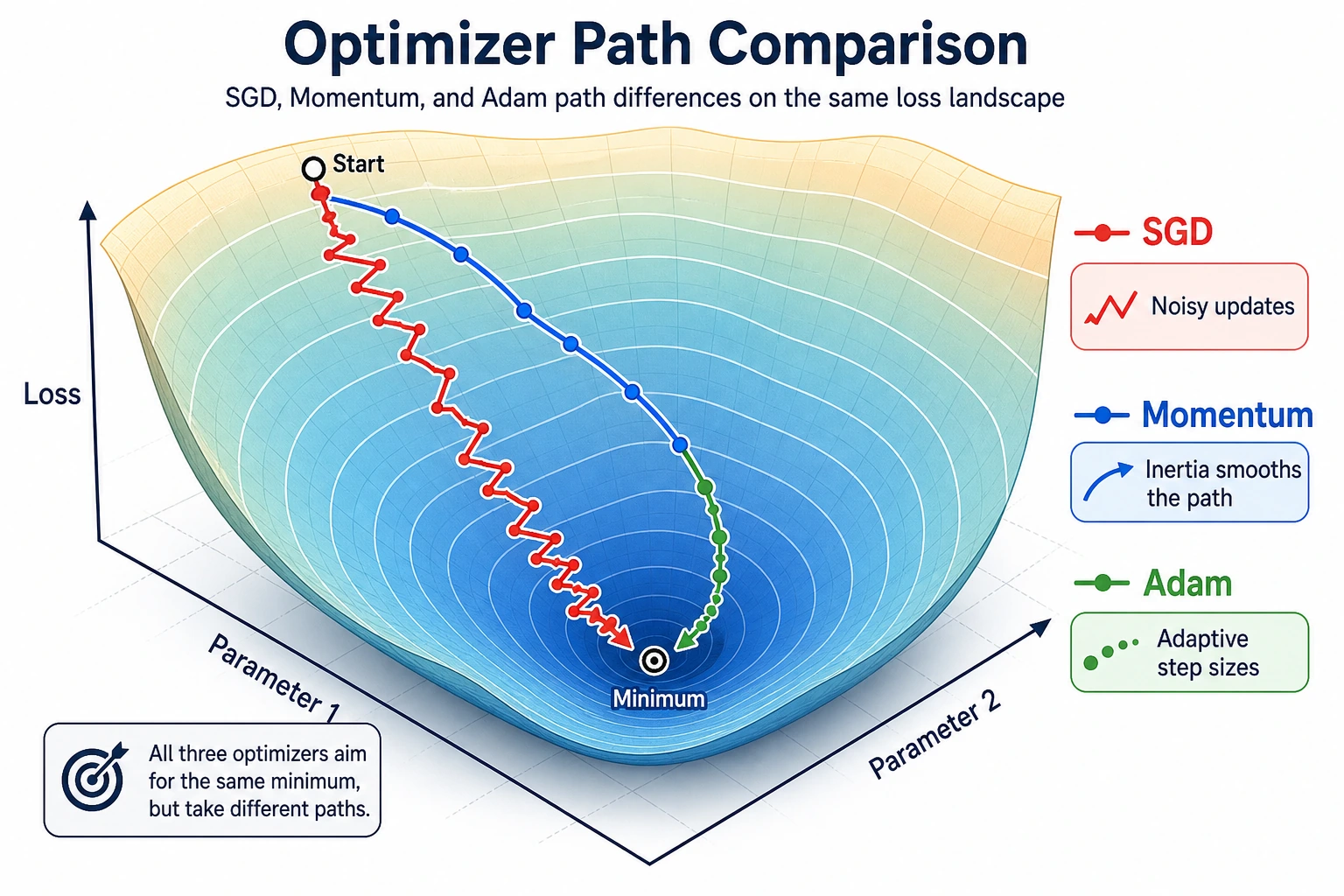
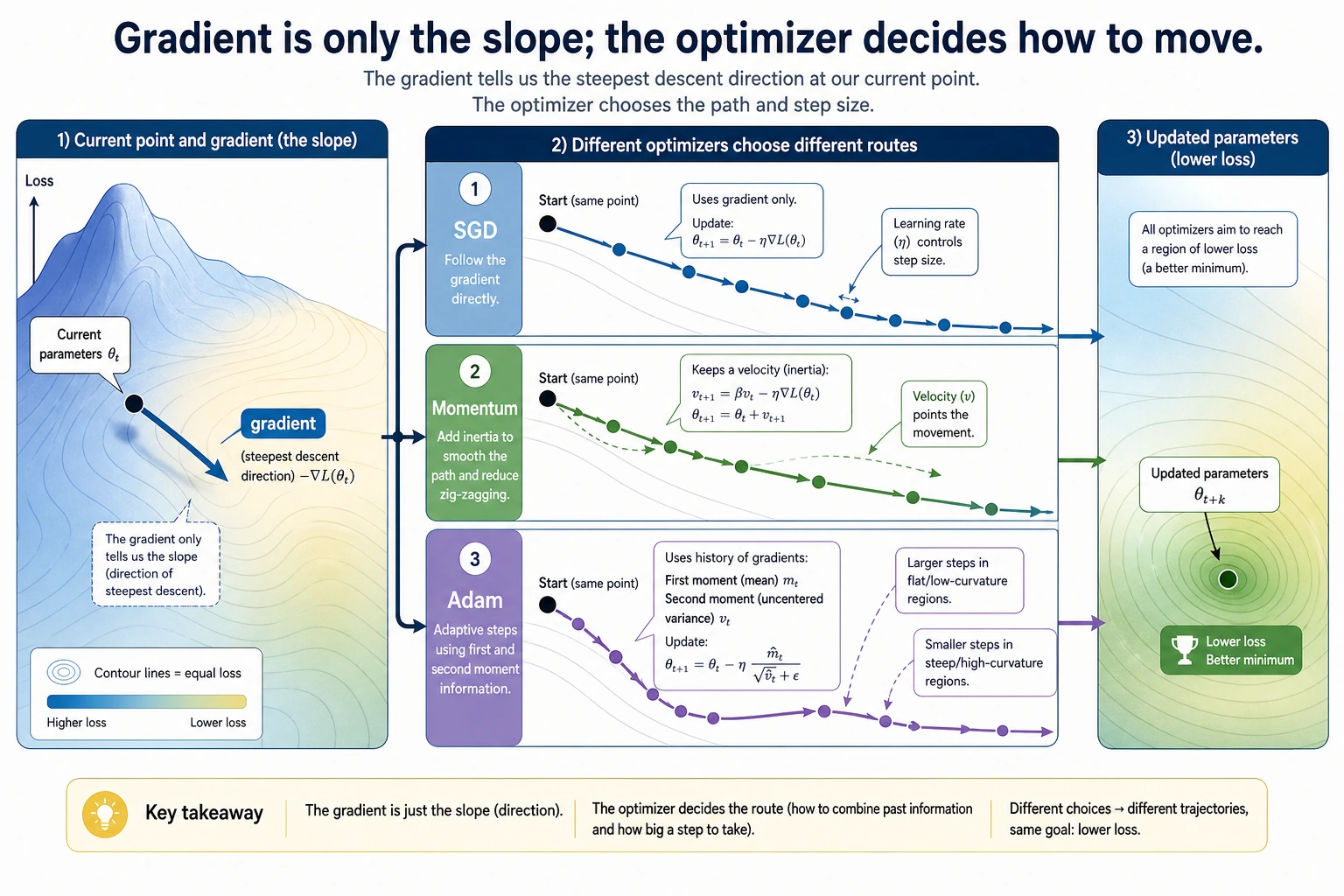
An optimizer decides how parameters move after gradients are computed. The optimizer name matters, but the learning rate often matters even more.
What You Will Build
This lesson runs a tiny PyTorch optimization lab:
- compare SGD, Momentum, and Adam on the same simple loss;
- see overshooting directly;
- test learning-rate sensitivity;
- learn a safe optimizer choice order.
Setup
python -m pip install -U torch
Run the Complete Lab
Create optimizer_lab.py:
import torch
def run_optimizer(name, optimizer_factory, steps=25):
torch.manual_seed(42)
w = torch.nn.Parameter(torch.tensor([5.0]))
optimizer = optimizer_factory([w])
for step in range(1, steps + 1):
loss = (w - 2).pow(2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step in [1, 5, 10, 25]:
print(f"{name:<8} step={step:<2} w={w.item():.3f} loss={loss.item():.4f}")
print("optimizer_comparison")
run_optimizer("sgd", lambda params: torch.optim.SGD(params, lr=0.1))
run_optimizer("momentum", lambda params: torch.optim.SGD(params, lr=0.1, momentum=0.9))
run_optimizer("adam", lambda params: torch.optim.Adam(params, lr=0.1))
print("learning_rate_check")
for lr in [0.01, 0.1, 1.1]:
torch.manual_seed(42)
w = torch.nn.Parameter(torch.tensor([5.0]))
optimizer = torch.optim.SGD([w], lr=lr)
for _ in range(10):
loss = (w - 2).pow(2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
final_loss = (w - 2).pow(2).item()
print(f"lr={lr:<4} final_w={w.item():.3f} final_loss={final_loss:.4f}")
Run it:
python optimizer_lab.py
Expected output:
optimizer_comparison
sgd step=1 w=4.400 loss=9.0000
sgd step=5 w=2.983 loss=1.5099
sgd step=10 w=2.322 loss=0.1621
sgd step=25 w=2.011 loss=0.0002
momentum step=1 w=4.400 loss=9.0000
momentum step=5 w=0.259 loss=0.8571
momentum step=10 w=2.013 loss=0.6767
momentum step=25 w=2.475 loss=0.0200
adam step=1 w=4.900 loss=9.0000
adam step=5 w=4.502 loss=6.7648
adam step=10 w=4.014 loss=4.4535
adam step=25 w=2.739 loss=0.6569
learning_rate_check
lr=0.01 final_w=4.451 final_loss=6.0085
lr=0.1 final_w=2.322 final_loss=0.1038
lr=1.1 final_w=20.575 final_loss=345.0386
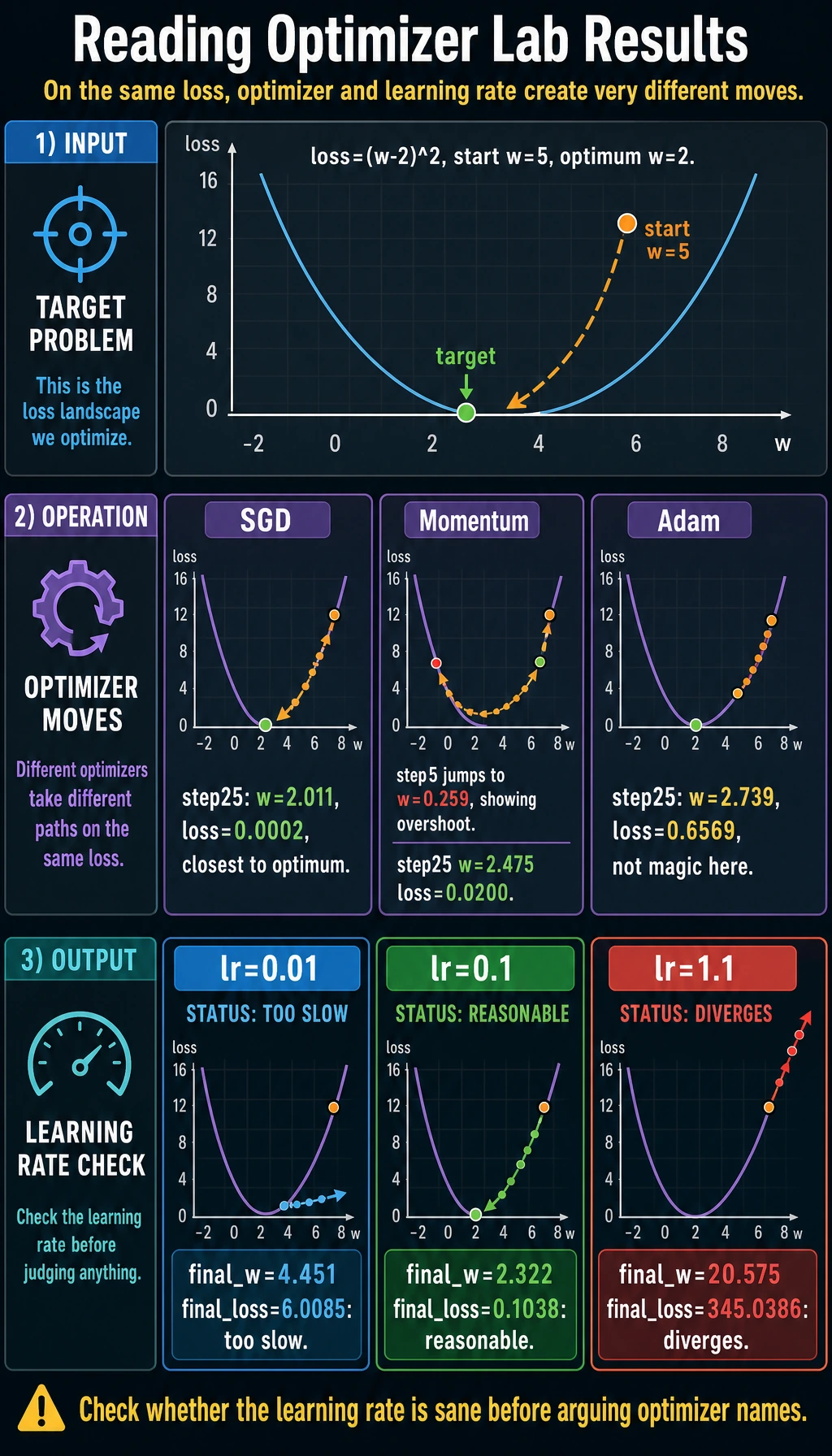
Read the Experiment
The loss is:
loss = (w - 2)^2
The best value is w=2. All optimizers start from w=5.
In this simple example, SGD with a good learning rate works extremely well:
sgd step=25 w=2.011 loss=0.0002
Momentum moves faster, but it can overshoot:
momentum step=5 w=0.259
Adam is a very common default in deep learning, but it is not magic. With lr=0.1 on this tiny problem, it moves more slowly than tuned SGD. The lesson is not "Adam is bad"; the lesson is:
Always inspect training behavior. Optimizer choice and learning rate work together.
Learning Rate Is the First Knob
The learning-rate check is intentionally blunt:
lr=0.01 final_w=4.451 final_loss=6.0085
lr=0.1 final_w=2.322 final_loss=0.1038
lr=1.1 final_w=20.575 final_loss=345.0386
Too small: training crawls.
Reasonable: training approaches the optimum.
Too large: training diverges.
Optimizer Intuition
| Optimizer | Intuition | Good first use |
|---|---|---|
| SGD | move directly against the gradient | simple baseline, controlled experiments |
| SGD + Momentum | keep velocity from previous steps | smoother progress in noisy directions |
| Adam | adapt step sizes using gradient history | strong default for many neural networks |
For real neural networks, Adam or AdamW is often a practical starting point. For final training, always compare with the task's validation metric.
Practical Selection Order
- Start with Adam or AdamW for a neural network baseline.
- Tune learning rate before arguing about optimizer names.
- Watch training and validation loss curves.
- If validation is unstable, lower LR or add scheduling.
- If training is slow but stable, try LR schedule or optimizer change.
Practical Debugging Checklist
| Symptom | Likely cause | Fix |
|---|---|---|
| loss explodes | learning rate too high | lower LR |
| loss decreases too slowly | LR too low or poor scaling | raise LR carefully, normalize inputs |
| training loss drops but validation worsens | overfitting | regularize, add data, stop earlier |
| loss oscillates | momentum/LR too aggressive | lower LR or momentum |
| Adam works but final quality is weak | optimizer hides other issues | check data, architecture, regularization |
Practice
- Change SGD learning rate to
0.05,0.2, and0.8. - Change momentum from
0.9to0.5. Does overshooting reduce? - Try
AdamWinstead ofAdam. - Print
w.gradeach step to connect gradients with updates. - Plot
wover steps for each optimizer.
Pass Check
You are done when you can explain:
- gradients say which direction changes loss;
- optimizers decide how far parameters move;
- learning rate can make training crawl, converge, or diverge;
- momentum can speed movement but can overshoot;
- Adam is useful, but not a substitute for checking curves.