6.1.7 Weight Initialization
Initialization decides whether a neural network starts training with usable signals. You usually start with PyTorch defaults, but you should know how to check Xavier, He, all-zero, too-small, and too-large initialization when training looks strange.
Learning Objectives
- Explain why all-zero weights break learning.
- Choose Xavier for Tanh/Sigmoid and He for ReLU-style activations.
- Run a signal probe before training.
- Compare initialization choices on a tiny classification task.
- Debug early training instability without changing random things blindly.
First Look at the Map
Before formulas, look at the job of initialization:
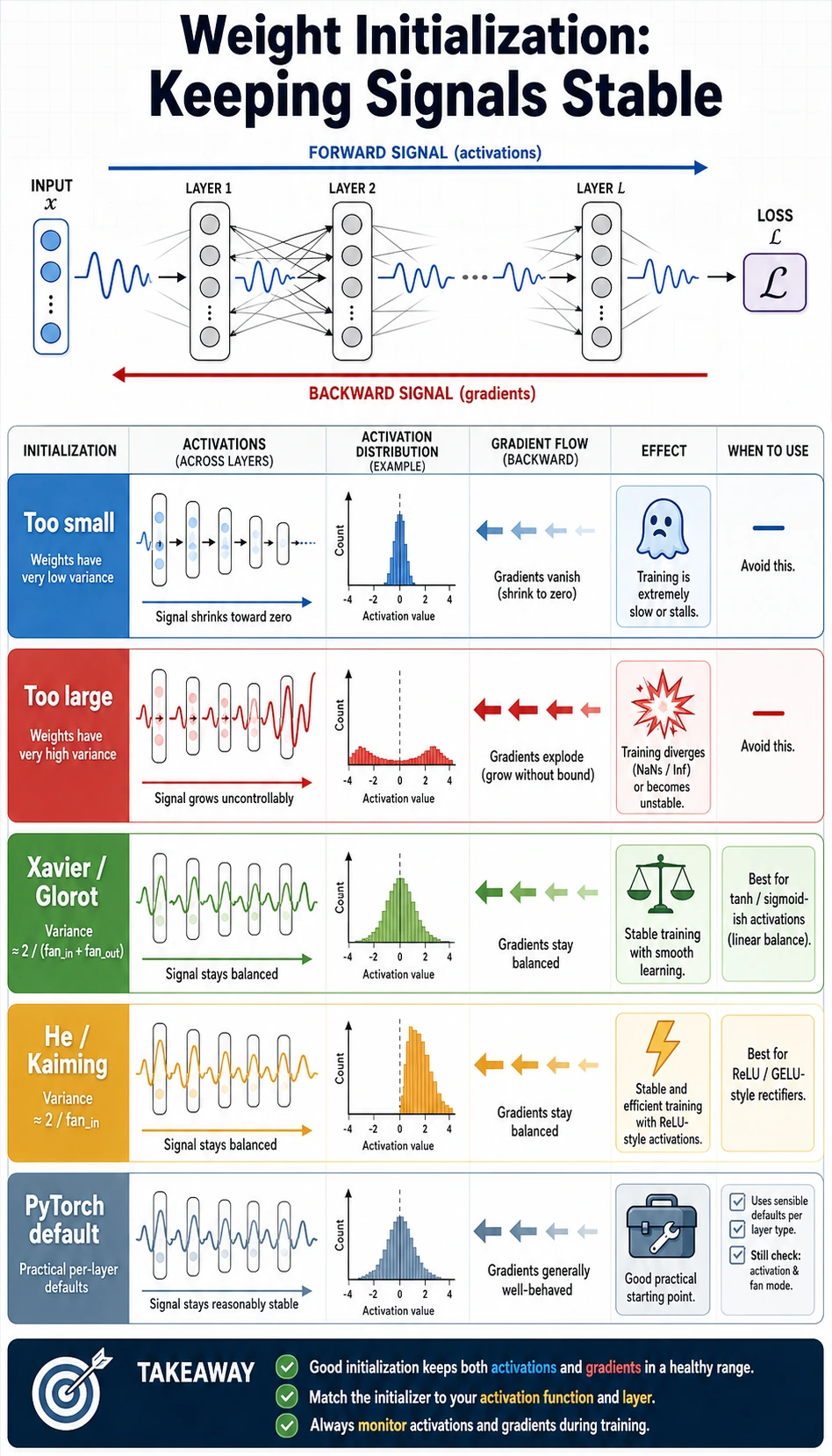
Read the picture from top to bottom:
- forward signal should not disappear layer by layer;
- activations should not saturate immediately;
- backward gradients should still have a path;
- PyTorch defaults are a good first choice for normal
nn.Linearandnn.Conv2dmodels.
The Minimal Idea
A neural network does this loop:
- initialize weights;
- run forward propagation;
- compute loss;
- run backpropagation;
- update weights with the optimizer.
If step 1 is broken, the later steps may still run, but they are running from a bad starting point.
The common failures are simple:
| Bad start | What happens | What you see |
|---|---|---|
| All zeros | Neurons stay identical | loss does not improve |
| Too small | signal shrinks through depth | deep layers become almost zero |
| Too large | activations saturate or explode | huge loss, unstable gradients |
| Mismatched init/activation | scale is wrong for the nonlinearity | slow or fragile training |
Two terms are worth knowing:
fan_in: number of input features entering a layer.fan_out: number of output features leaving a layer.
Initialization formulas use these numbers to keep each layer's scale reasonable.
Xavier and He in One Table
You do not need to memorize every formula first. Remember the match:
| Activation | Good default choice | PyTorch helper | Why |
|---|---|---|---|
| Tanh / Sigmoid | Xavier, also called Glorot | nn.init.xavier_normal_ | keeps input/output variance balanced |
| ReLU / Leaky ReLU | He, also called Kaiming | nn.init.kaiming_normal_ | compensates for ReLU setting many values to zero |
| Not sure in a normal PyTorch model | PyTorch default | no manual code | good first baseline |
For a normal first project, do not manually initialize everything on day one. Use PyTorch defaults, make sure the learning rate and data pipeline are sane, then investigate initialization if signals or gradients look abnormal.
Lab Setup
Run the labs in a notebook cell or save them as weight_init_lab.py.
Install the required packages if needed:
pip install torch scikit-learn
Lab 1: Probe Signals Before Training
This experiment sends random data through an 8-layer network and prints the first-layer and last-layer activation statistics. The goal is not to get high accuracy; the goal is to see whether signals survive depth.
import torch
import torch.nn as nn
torch.manual_seed(7)
def build_probe(activation):
layers = []
in_features = 32
for _ in range(8):
layer = nn.Linear(in_features, 128)
layers.append(layer)
layers.append(activation())
in_features = 128
return nn.Sequential(*layers)
def apply_init(model, strategy):
for module in model:
if isinstance(module, nn.Linear):
if strategy == "tiny":
nn.init.normal_(module.weight, 0.0, 0.01)
elif strategy == "large":
nn.init.normal_(module.weight, 0.0, 1.0)
elif strategy == "xavier":
nn.init.xavier_normal_(module.weight)
elif strategy == "he":
nn.init.kaiming_normal_(module.weight, mode="fan_in", nonlinearity="relu")
nn.init.zeros_(module.bias)
def probe(strategy, activation_cls):
model = build_probe(activation_cls)
apply_init(model, strategy)
x = torch.randn(512, 32)
stats = []
for layer in model:
x = layer(x)
if isinstance(layer, activation_cls):
stats.append(
{
"mean": x.mean().item(),
"std": x.std().item(),
"zero_ratio": (x == 0).float().mean().item(),
"saturated_ratio": (x.abs() > 0.98).float().mean().item(),
}
)
return stats[0], stats[-1]
print("signal_probe")
for label, strategy, activation in [
("tiny + ReLU", "tiny", nn.ReLU),
("large + Tanh", "large", nn.Tanh),
("Xavier + Tanh", "xavier", nn.Tanh),
("He + ReLU", "he", nn.ReLU),
]:
first, last = probe(strategy, activation)
print(
f"{label:14s} "
f"first_std={first['std']:.4f} "
f"last_std={last['std']:.4f} "
f"last_zero={last['zero_ratio']:.2f} "
f"last_saturated={last['saturated_ratio']:.2f}"
)
Expected output:
signal_probe
tiny + ReLU first_std=0.0337 last_std=0.0000 last_zero=0.52 last_saturated=0.00
large + Tanh first_std=0.9273 last_std=0.9633 last_zero=0.00 last_saturated=0.84
Xavier + Tanh first_std=0.4872 last_std=0.2276 last_zero=0.00 last_saturated=0.00
He + ReLU first_std=0.8304 last_std=0.6937 last_zero=0.49 last_saturated=0.19
How to read it:
tiny + ReLU: last-layer standard deviation becomes almost zero, so the deep signal has faded.large + Tanh: many values are saturated near -1 or 1, so gradients through Tanh become weak.Xavier + Tanh: signal scale is more controlled.He + ReLU: ReLU naturally has many zeros, but the signal still reaches deeper layers.
Lab 2: Train a Tiny Classifier
Now compare the same idea during training. This is a small two-class toy dataset, so even some bad starts may recover. The important clue is the starting loss and whether all-zero initialization gets stuck.
import torch
import torch.nn as nn
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
torch.manual_seed(9)
X, y = make_moons(n_samples=600, noise=0.22, random_state=9)
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.long)
train_idx, val_idx = train_test_split(
torch.arange(len(X)),
test_size=0.25,
random_state=9,
stratify=y,
)
X_train, y_train = X[train_idx], y[train_idx]
X_val, y_val = X[val_idx], y[val_idx]
class MoonMLP(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 2),
)
def forward(self, x):
return self.net(x)
def apply_init(model, strategy):
if strategy == "default":
return
for module in model.modules():
if isinstance(module, nn.Linear):
if strategy == "zeros":
nn.init.zeros_(module.weight)
elif strategy == "tiny":
nn.init.normal_(module.weight, 0.0, 0.01)
elif strategy == "large":
nn.init.normal_(module.weight, 0.0, 1.0)
elif strategy == "xavier":
nn.init.xavier_normal_(module.weight)
elif strategy == "he":
nn.init.kaiming_normal_(module.weight, mode="fan_in", nonlinearity="relu")
nn.init.zeros_(module.bias)
def accuracy(model, X, y):
with torch.no_grad():
preds = model(X).argmax(dim=1)
return (preds == y).float().mean().item()
def train_once(strategy):
torch.manual_seed(9)
model = MoonMLP()
apply_init(model, strategy)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.CrossEntropyLoss()
start_loss = loss_fn(model(X_train), y_train).item()
for _ in range(120):
loss = loss_fn(model(X_train), y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
end_loss = loss_fn(model(X_train), y_train).item()
return start_loss, end_loss, accuracy(model, X_val, y_val)
print("training_probe")
for strategy in ["default", "zeros", "tiny", "large", "xavier", "he"]:
start, end, acc = train_once(strategy)
print(f"{strategy:8s} start_loss={start:.3f} end_loss={end:.3f} val_acc={acc:.3f}")
Expected output:
training_probe
default start_loss=0.671 end_loss=0.047 val_acc=0.973
zeros start_loss=0.693 end_loss=0.693 val_acc=0.500
tiny start_loss=0.693 end_loss=0.067 val_acc=0.973
large start_loss=20.040 end_loss=0.068 val_acc=0.980
xavier start_loss=0.696 end_loss=0.046 val_acc=0.980
he start_loss=0.924 end_loss=0.053 val_acc=0.980
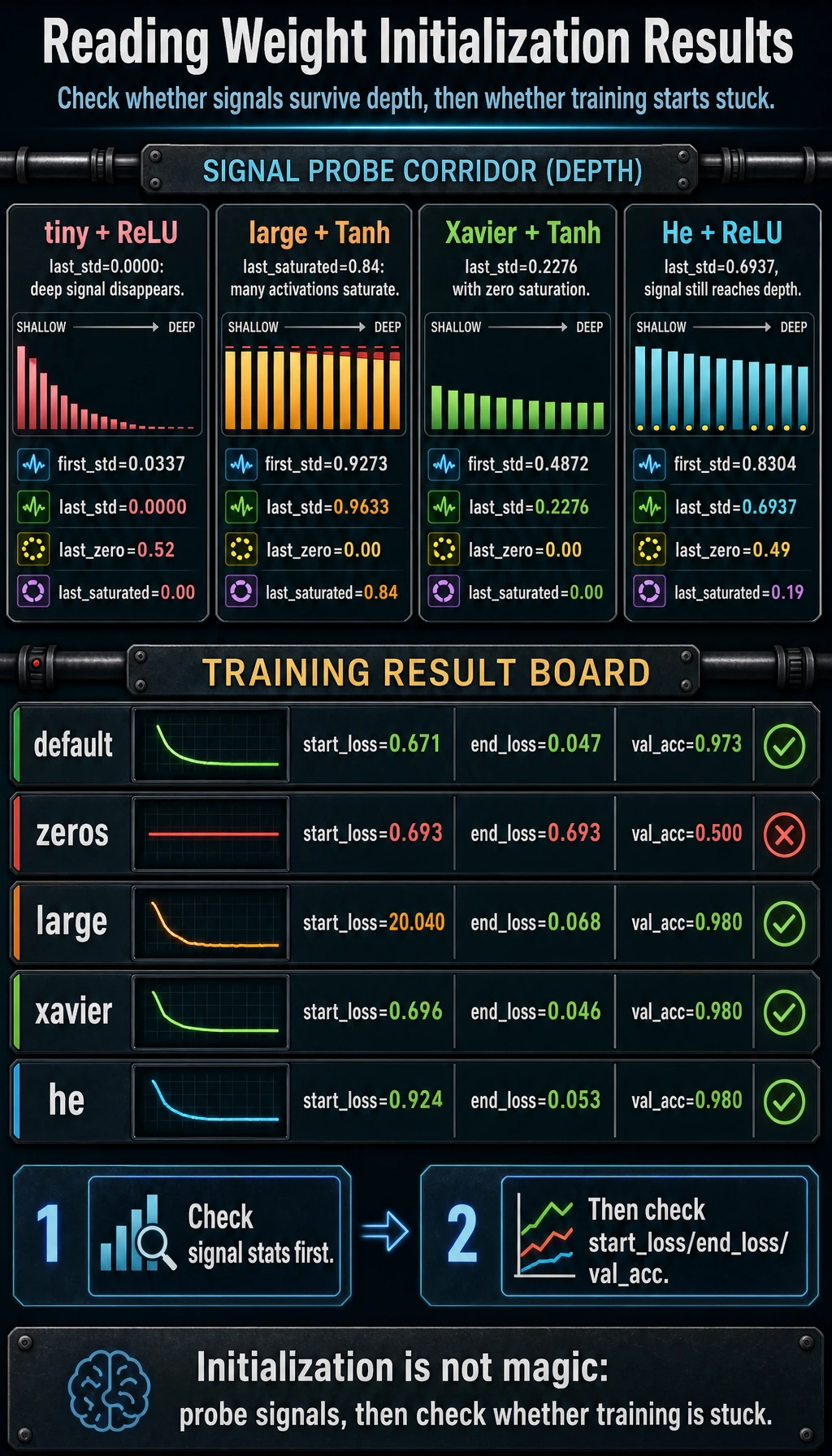
What matters:
zerosstays stuck because hidden neurons begin as identical copies.largestarts with a huge loss, which is a warning sign even if this small model later recovers.default,xavier, andheall work here; that is exactly why defaults are a good first baseline.
Debugging Checklist
When training is broken in the first few epochs, check in this order:
- Is the data shape correct?
- Is the target dtype correct?
CrossEntropyLossexpects class labels astorch.long. - Is the learning rate too high?
- Are activations mostly zero, saturated,
nan, orinf? - Does the initialization match the activation function?
Use quick probes instead of guessing:
with torch.no_grad():
sample = X_train[:32]
out = model(sample)
print(out.mean().item(), out.std().item(), torch.isfinite(out).all().item())
If the output is not finite, or if every value is almost the same, inspect initialization, input scaling, and learning rate together.
Exercises
- Change the probe network depth from 8 to 20. Which initialization fails first?
- Replace ReLU with Tanh in
MoonMLP. Does Xavier become more competitive? - Change Adam to SGD with
lr=0.1. Which initialization becomes more fragile?
Key Takeaways
- Initialization is the starting condition for forward signals and backward gradients.
- All-zero weights break symmetry and should not be used for hidden layers.
- Xavier is a strong match for Tanh/Sigmoid; He is a strong match for ReLU-style activations.
- PyTorch defaults are usually the right first move, but signal probes help when training behaves strangely.