8.5.2 Project: Enterprise Knowledge Base Q&A
The reason enterprise knowledge base Q&A is a great portfolio project is not because it sounds fancy, but because it is very real:
- There are documents
- There are permissions
- There are versions
- There are citations
- And there is pressure that “getting the answer wrong affects the business”
So the most important thing for this kind of project is not “whether it looks like it is answering,” but:
Does the answer come from the correct document, within the correct permission scope, and can it be traced back to the source?
Learning Objectives
- Learn how to organize enterprise documents into searchable knowledge units
- Learn how to design the two enterprise-grade constraints of permissions and citations
- Learn how to build a showcaseable project loop with a minimal retriever
- Learn how to present the project around error analysis and traceability
Beginner terminology bridge
Enterprise knowledge-base projects use several words that sound simple but have strict engineering meaning:
| Term | Beginner meaning | Why it matters in this project |
|---|---|---|
permission filtering | Remove documents the current user is not allowed to see before retrieval or answering | Prevents the system from leaking internal content |
citation | A source reference attached to the answer | Lets users verify where the answer came from |
metadata | Extra fields attached to a chunk, such as source file, department, visibility, page, or version | Makes filtering, debugging, and citation possible |
SOP | Standard Operating Procedure, a fixed internal workflow document | Many enterprise answers are not just facts, but process rules |
traceability | The ability to follow an answer back to the original document and processing path | This is what makes the project trustworthy instead of just fluent |
The key idea is: an enterprise knowledge base is not only a search problem. It is also a permission, evidence, and audit problem.
Why is enterprise knowledge base Q&A harder than ordinary FAQ?
Documents are longer
Enterprise knowledge is often not just a few Q&As, but rather:
- Policy documents
- Internal SOPs
- Training manuals
- Product documentation
Permissions are more complex
For the same question, there may be:
- An external version
- An internal version
Trust requirements are higher
Users will often ask:
- Where did this rule come from?
- Which file are you citing?
So enterprise knowledge base Q&A is more like a combination of:
- A retrieval system
- A citation system
- A permission system

An enterprise knowledge base cannot rely only on “semantic relevance.” First filter candidates by user permissions, then retrieve and rerank, and finally make sure the answer includes source citations; otherwise, the system may sound correct while leaking internal documents or becoming impossible to trace.
Define the project scope first
A very suitable minimum scope for a portfolio project is:
Build a “refund / invoice / certificate / internal customer support SOP” knowledge base Q&A system for an internal help center on a course platform.
It should at least answer four types of questions:
- External policy questions
- Internal process questions
- Questions whose answers differ by permission
- Questions that require source citations
Why is this scope good?
- The document topics are focused
- The permission boundary is realistic
- It is easy to explain whether the result is good or bad
Design the knowledge units first, not the model first
The following example does three things:
- Splits documents into the smallest knowledge units
- Adds metadata to each chunk
- Distinguishes between public and internal visibility
kb = [
{
"id": "doc_001",
"section": "Refund Policy",
"department": "support",
"visibility": "public",
"text": "A refund can be requested within 7 days of purchase if learning progress is below 20%.",
"keywords": {"refund", "7 days", "progress", "20%"},
},
{
"id": "doc_002",
"section": "Certificate Guide",
"department": "teaching",
"visibility": "public",
"text": "A completion certificate can be issued after finishing all required projects and passing the course final test.",
"keywords": {"certificate", "final test", "project"},
},
{
"id": "doc_003",
"section": "Internal Customer Support SOP",
"department": "internal",
"visibility": "internal",
"text": "When handling a refund request, customer support must first verify the order number, learning progress, and payment channel.",
"keywords": {"refund", "customer support", "SOP", "verify", "verification", "process"},
},
]
for item in kb:
print(f"{item['id']} | {item['visibility']} | {item['section']}")
Expected output:
doc_001 | public | Refund Policy
doc_002 | public | Certificate Guide
doc_003 | internal | Internal Customer Support SOP
Why add so much metadata here?
Because enterprise knowledge base retrieval is not only about “does the content seem similar,” but also about deciding:
- Whether the current user is allowed to see it
- Which business domain it belongs to
- How the source should be shown in the answer
This is also the fundamental difference between an enterprise project and a normal Q&A demo.
Build an explainable retriever first
To make the example runnable in the current environment, we will not use an external embedding library yet, but instead use a pure Python keyword-overlap retriever to get the project skeleton in place first.
def retrieve(query, allowed_visibility, top_k=2):
candidates = []
query_text = query.lower()
for item in kb:
if item["visibility"] not in allowed_visibility:
continue
score = sum(keyword.lower() in query_text for keyword in item["keywords"])
candidates.append((score, item))
candidates.sort(key=lambda x: x[0], reverse=True)
return [item for score, item in candidates[:top_k] if score > 0]
print("public user:")
for hit in retrieve("What is the refund policy?", allowed_visibility={"public"}):
print(hit["id"], hit["visibility"], hit["section"])
print("\ninternal support:")
for hit in retrieve("What is the customer verification process?", allowed_visibility={"public", "internal"}):
print(hit["id"], hit["visibility"], hit["section"])
Expected output:
public user:
doc_001 public Refund Policy
internal support:
doc_003 internal Internal Customer Support SOP
Although this retriever is simple, why is it very suitable for teaching?
Because it makes three things very clear:
- How query terms affect recall
- How permissions affect the candidate set
- Why the results are different
Why deliberately not use embeddings directly here?
Because this lesson first needs to explain clearly:
- Permissions
- Source citations
- Structured knowledge units
These enterprise-grade key points. Once the skeleton is clear, switching to a stronger retrieval method will be much more stable.
Make “answer + sources” together
def answer_with_sources(query, allowed_visibility):
hits = retrieve(query, allowed_visibility=allowed_visibility, top_k=2)
if not hits:
return {
"answer": "No sufficiently relevant information was found within the current permission scope.",
"sources": [],
}
top = hits[0]
return {
"answer": top["text"],
"sources": [
{
"id": top["id"],
"section": top["section"],
"department": top["department"],
"visibility": top["visibility"],
}
],
}
print(answer_with_sources("What is the refund policy?", {"public"}))
print(answer_with_sources("What is the customer verification process?", {"public", "internal"}))
Expected output:
{'answer': 'A refund can be requested within 7 days of purchase if learning progress is below 20%.', 'sources': [{'id': 'doc_001', 'section': 'Refund Policy', 'department': 'support', 'visibility': 'public'}]}
{'answer': 'When handling a refund request, customer support must first verify the order number, learning progress, and payment channel.', 'sources': [{'id': 'doc_003', 'section': 'Internal Customer Support SOP', 'department': 'internal', 'visibility': 'internal'}]}
Why is “returning sources” a highlight of a portfolio project?
Because it makes the system do more than just “give you an answer,” and also answer:
- Where did this answer come from?
- Why should I trust it?
This significantly increases the credibility of the project.
Why do enterprise scenarios need sources more than ordinary Q&A?
Because enterprise users often really use the answer to carry out a process. Without sources, trust is hard to build.
How should this project be evaluated?
It is not enough to only check “whether it answered”
An enterprise knowledge base project should be evaluated in at least three layers:
- Whether the retrieval is relevant
- Whether the permissions are correct
- Whether the citations are traceable
A minimal evaluation set
eval_cases = [
{
"query": "What is the refund policy?",
"visibility": {"public"},
"expected_doc": "doc_001",
},
{
"query": "What is the customer verification process?",
"visibility": {"public"},
"expected_doc": None,
},
{
"query": "What is the customer verification process?",
"visibility": {"public", "internal"},
"expected_doc": "doc_003",
},
]
for case in eval_cases:
result = answer_with_sources(case["query"], case["visibility"])
got = result["sources"][0]["id"] if result["sources"] else None
print({
"query": case["query"],
"expected_doc": case["expected_doc"],
"got": got,
"match": got == case["expected_doc"],
})
Expected output:
{'query': 'What is the refund policy?', 'expected_doc': 'doc_001', 'got': 'doc_001', 'match': True}
{'query': 'What is the customer verification process?', 'expected_doc': None, 'got': None, 'match': True}
{'query': 'What is the customer verification process?', 'expected_doc': 'doc_003', 'got': 'doc_003', 'match': True}
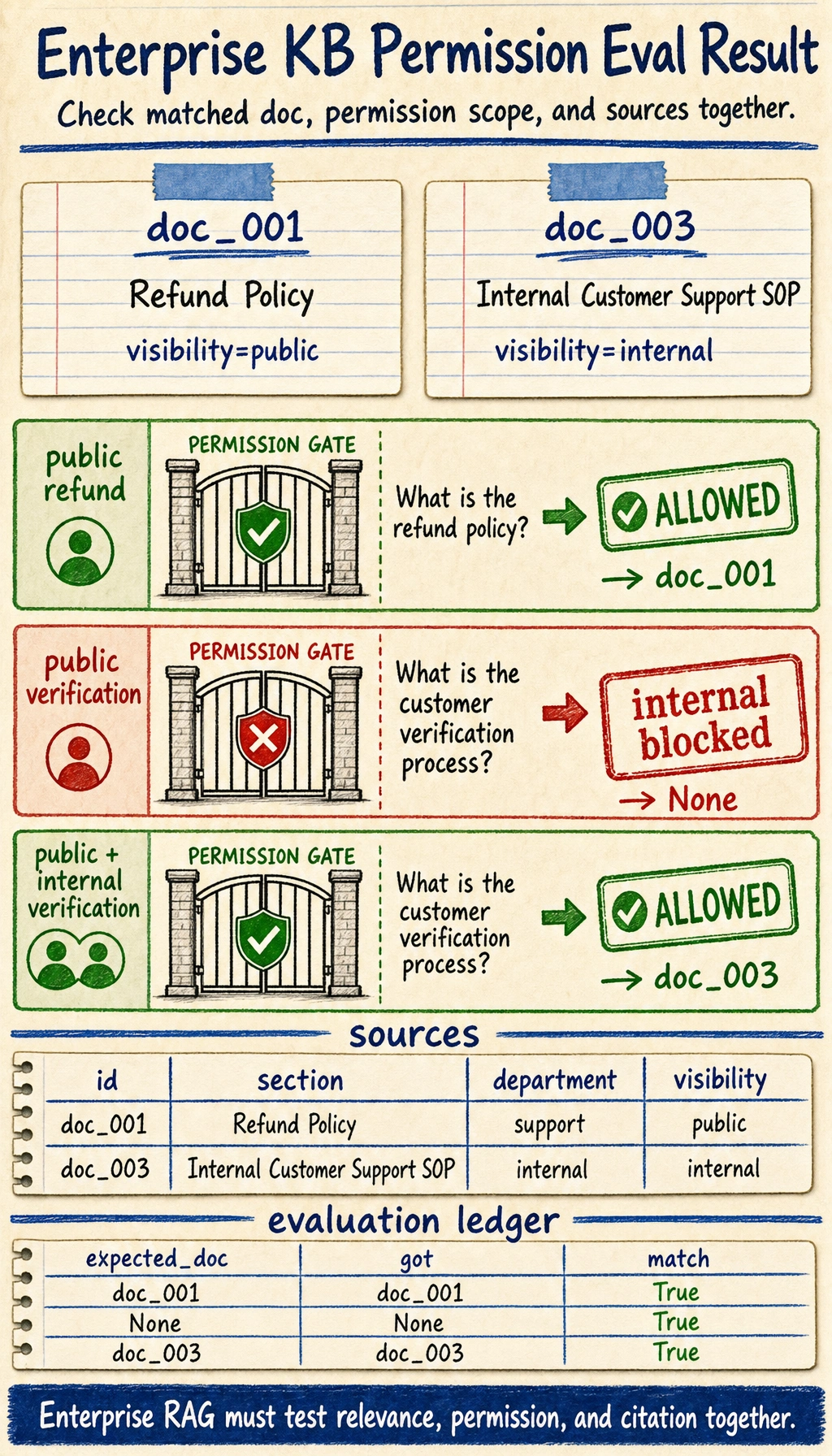
Read row 2 as the permission test: the same customer-verification question could match the internal SOP, but a public-only user must get None. The source cards explain why row 3 passes only when internal is allowed.
Why is this kind of evaluation valuable?
Because it directly covers the two most important risks in an enterprise knowledge base:
- It should answer, but fails to answer correctly
- It should not be visible, but internal documents are exposed
How can you take this project one step closer to portfolio quality?
Upgrade rule-based retrieval to vector retrieval
Add document chunking and reranking
Build a user interface for source display
The most recommended items to show are:
- User question
- Matched document
- Final answer
- Source citation
Show a few “permission-related failure examples”
This will be very convincing.
The most common pitfalls
Only building “can answer,” not “can be traced”
Only looking at semantic relevance, not permission boundaries
Making document chunks too coarse
When chunks are too coarse, both answers and sources often become vague.
Summary
The most important thing in this lesson is to build a portfolio-grade judgment:
What makes enterprise knowledge base Q&A feel like a real project is not that it connects to a retriever, but that it organizes knowledge units, permission boundaries, answer generation, and source traceability into a trustworthy closed loop.
Once this closed loop is clear, this project will look very much like a real enterprise system.
Suggested version roadmap
| Version | Goal | Delivery focus |
|---|---|---|
| Basic version | Get the minimal loop running | Can accept input, process it, and output results, while keeping a set of examples |
| Standard version | Form a showcaseable project | Add configuration, logs, error handling, README, and screenshots |
| Advanced version | Close to portfolio quality | Add evaluation, comparison experiments, failure-case analysis, and a next-step roadmap |
It is recommended to finish the basic version first, and do not pursue an all-in-one solution from the beginning. Each time you upgrade a version, write into the README what new capability was added, how it was verified, and what problems still remain.
Exercises
- Add two more “public documents” and one “internal document” to
kbto make query competition more realistic. - Why is “correct permissions” sometimes more important than “a beautiful answer” in an enterprise knowledge base project?
- Think about it: if document chunks are cut too coarsely, how will that affect the answer and the citation?
- If you turn this project into a portfolio piece, which 4 blocks of information would be most worth showing on the homepage?