5 Introduction to Machine Learning: From Basics to Practice

Chapter 5 has one job: help you turn a data problem into a trainable, evaluable, improvable machine learning project.
Where You Are In The Main Route
Section titled “Where You Are In The Main Route”You have already learned how data becomes numbers and how loss and gradients explain model improvement. This chapter makes those ideas practical: define a prediction problem, build a baseline, choose a metric, inspect errors, and improve only when evidence says the change helped.
This is the bridge from math intuition to model engineering. Chapter 6 will keep the same evidence habit, but the model will become a neural network trained with tensors and backpropagation.
See The Modeling Loop
Section titled “See The Modeling Loop”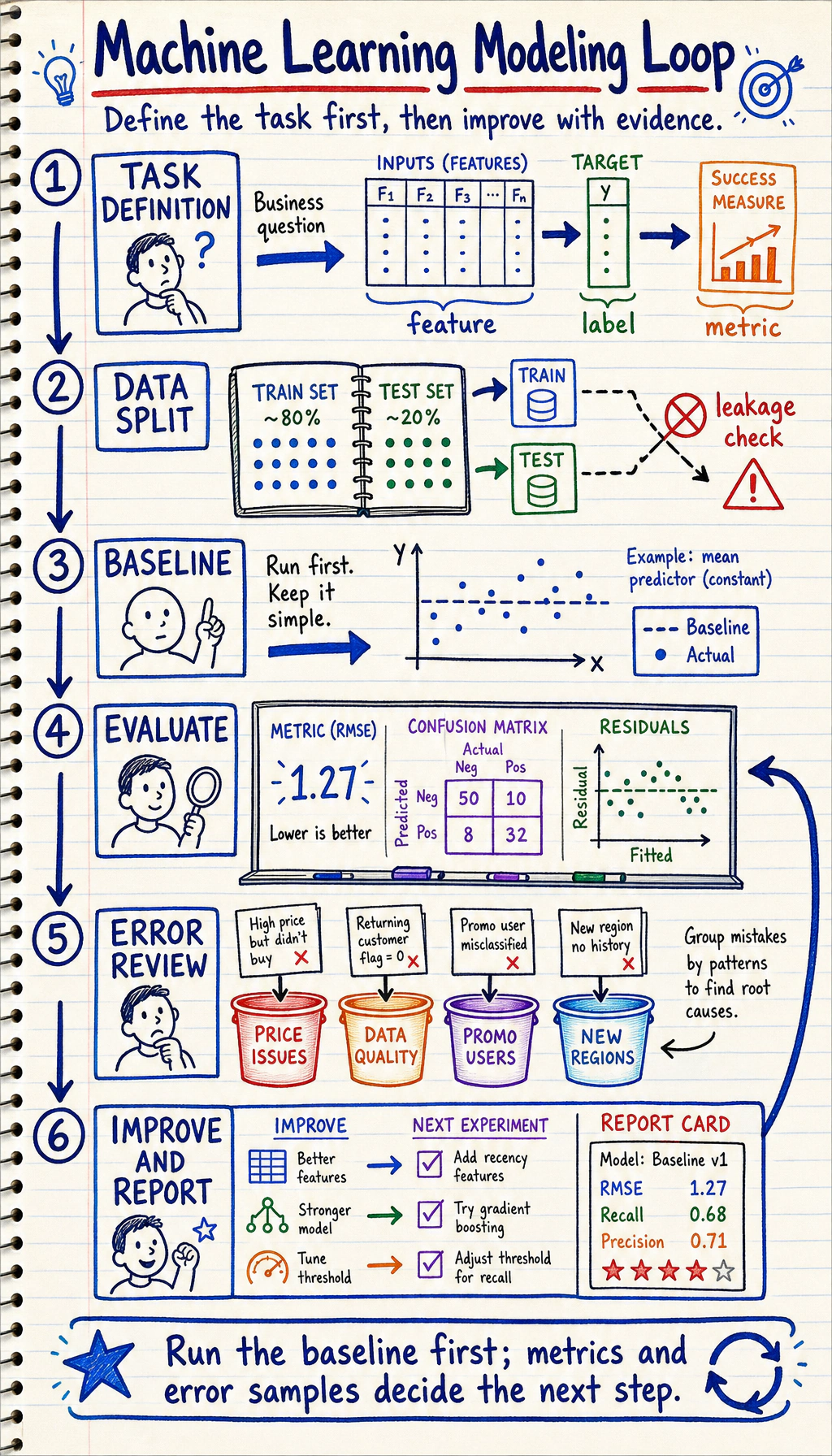
Read the picture first. Most reliable ML work follows this loop:
Start with a baseline before chasing model names. A baseline tells you whether later changes actually improve anything.
Learning Order And Task List
Section titled “Learning Order And Task List”Use this checklist as both the chapter guide and the task sheet. Establish the baseline and evaluation habit before expanding the model search.
-
5.1 ML Basics Follow along: identify classification, regression, clustering, anomaly detection, features, labels, train/test split, and sklearn flow. Evidence to keep: a problem-definition note.
-
5.1.5 ML History Follow along: optional background; skim how classic algorithms appeared. Evidence to keep: a short “why this algorithm exists” note.
-
5.2 Supervised Learning Follow along: run regression and classification examples before comparing many models. Evidence to keep: one baseline score and one improved score.
-
5.3 Unsupervised Learning Follow along: try clustering, dimensionality reduction, and anomaly detection when labels are missing. Evidence to keep: one chart or cluster interpretation.
-
5.4 Evaluation Follow along: choose metrics, use cross-validation, diagnose bias/variance, and tune carefully. Evidence to keep: metric choice and error samples.
-
5.5 Feature Engineering Follow along: handle missing values, categories, scaling, feature construction, feature selection, and Pipeline. Evidence to keep: feature processing log and leakage check.
-
5.6 Projects and 5.6.6 Workshop Follow along: build a reproducible evidence pack before larger house-price, churn, segmentation, or Kaggle work. Evidence to keep: README, model comparison, errors, and next-step plan.
Core Path, Extensions, And Depth
Section titled “Core Path, Extensions, And Depth”| Layer | What to study now | How to use it |
|---|---|---|
| Required core | Task type, train/test split, baseline, metric, error samples, leakage check, Pipeline | These become the evaluation habits for LLM prompts, RAG retrieval, and Agent behavior later |
| Optional extension | Extra classic algorithms, ML history, Kaggle-style iteration | Return here when a project needs broader algorithm comparison or competition workflow |
| Depth challenge | Keep the data and metric fixed, change one feature or model choice, then explain the before/after errors | This prevents model hopping without evidence |
Key terms for this chapter:
| Term | Meaning |
|---|---|
feature | Input column the model can use |
label / target | Answer the model should learn to predict |
baseline | Simplest model or rule you must beat |
metric | Ruler for judging the model, such as F1, AUC, MAE, or RMSE |
leakage | Test or target information accidentally entering training |
Pipeline | Preprocessing and model packaged together to reduce leakage |
First Runnable Loop
Section titled “First Runnable Loop”Install sklearn if needed:
python -m pip install scikit-learnThen run this self-contained baseline. It uses a built-in dataset, splits data, trains a dummy baseline, trains a real model, and compares both.
from sklearn.datasets import load_breast_cancerfrom sklearn.dummy import DummyClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import classification_reportfrom sklearn.model_selection import train_test_splitfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import StandardScaler
X, y = load_breast_cancer(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)
baseline = DummyClassifier(strategy="most_frequent")baseline.fit(X_train, y_train)print("Baseline")print(classification_report(y_test, baseline.predict(X_test), zero_division=0))
model = make_pipeline(StandardScaler(), LogisticRegression(max_iter=1000))model.fit(X_train, y_train)print("Logistic regression")print(classification_report(y_test, model.predict(X_test), zero_division=0))Expected shape:
Baseline...Logistic regression...Do not only compare the final scores. Ask: which classes are easy, which are hard, and what error would matter most in the real use case?
How to read this output
Section titled “How to read this output”- The baseline tells you what a naive model can do before learning useful patterns.
- Logistic regression should beat the baseline, but the class-level precision and recall matter more than one headline score.
- If one class has poor recall, inspect those missed examples before changing the model.
- Keep the split, metric, and failure samples fixed when comparing the next experiment.
Depth Ladder
Section titled “Depth Ladder”| Level | What you can prove |
|---|---|
| Minimum pass | You can name the task type, split the data, train a baseline, and read the score. |
| Project-ready | You can explain why the chosen metric matches the goal, and show one error sample instead of trusting one score. |
| Deeper check | You can test for leakage, compare two feature choices, and say what would change in a real product or dataset update. |
Failure Sample Drill
Section titled “Failure Sample Drill”Before leaving the chapter, save one wrong prediction or weak cluster interpretation. Write it in this format:
case_id:input_summary:true_or_expected:model_output:why_it_matters:next_controlled_change:This small failure note is more useful than another model name. It teaches the habit you will reuse in deep learning curves, prompt evaluation, RAG retrieval errors, and Agent traces.
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Modeling Loop
- data, features, model, metric, error review, and next experiment
- Artifact
- code, score, chart, pipeline, or project README
- Failure Check
- leakage, metric mismatch, unstable split, overfitting, or unclear business target
- Next Action
- one controlled experiment rather than many parameter changes
- Expected Output
- reproducible ML evidence that prepares for deep learning
Common Failures
Section titled “Common Failures”| Symptom | First thing to check | Usual fix |
|---|---|---|
| Score is strangely high | Leakage or wrong train/test split | Inspect features and split before training |
| Train score high, test score low | Overfitting | Simplify the model, regularize, or add data |
| All models are weak | Poor labels, weak features, or wrong metric | Inspect error samples and label definition |
| Accuracy looks fine but product risk is high | Class imbalance or costly false negatives | Use recall, precision, F1, AUC, or threshold review |
| Results cannot be reproduced | Random seed, data version, or dependency changed | Fix seeds and record versions |
Pass Check
Section titled “Pass Check”Move to Chapter 6 when you can answer these five questions:
- Is this task classification, regression, clustering, or anomaly detection?
- What is the baseline, and what score must a real model beat?
- Which metric matches the goal, and when is accuracy misleading?
- How did you check for leakage?
- What does the model do well, what does it do poorly, and what would you improve next?
Check reasoning and explanation
- Decide the task from the target: categories mean classification, numbers mean regression, no labels usually means clustering or anomaly detection.
- The baseline is the simplest reproducible model or rule. A real model only matters if it beats that baseline under the same split and metric.
- Choose the metric from the cost of mistakes. Accuracy is misleading when classes are imbalanced or when one error type is much more expensive.
- Check leakage by asking whether any feature contains target, future, test-set, or human-review information that would not exist at prediction time.
- A good next step names one weakness, one evidence sample, and one controlled change rather than changing many knobs at once.
For a printable checklist, use 5.0 Study Guide and Task Sheet. The next chapter moves from sklearn models into neural networks and deep learning training.