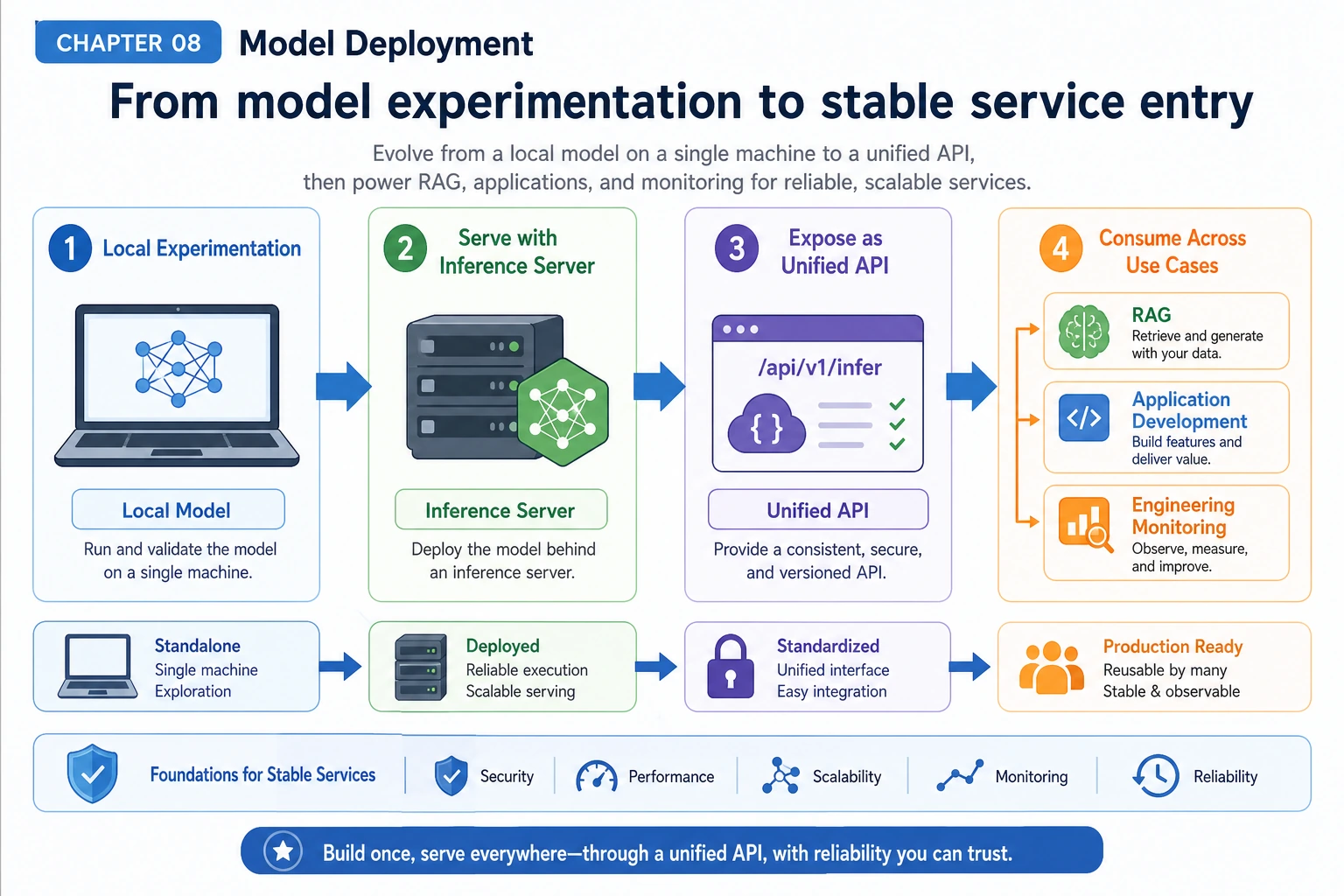
8.2.1 Deployment Roadmap: Local Model, Service, Unified API
Deployment turns a model from a notebook experiment into a reusable capability. The application should call a stable interface, even when the model, provider, hardware, or cost policy changes.
See the Serving Decision First
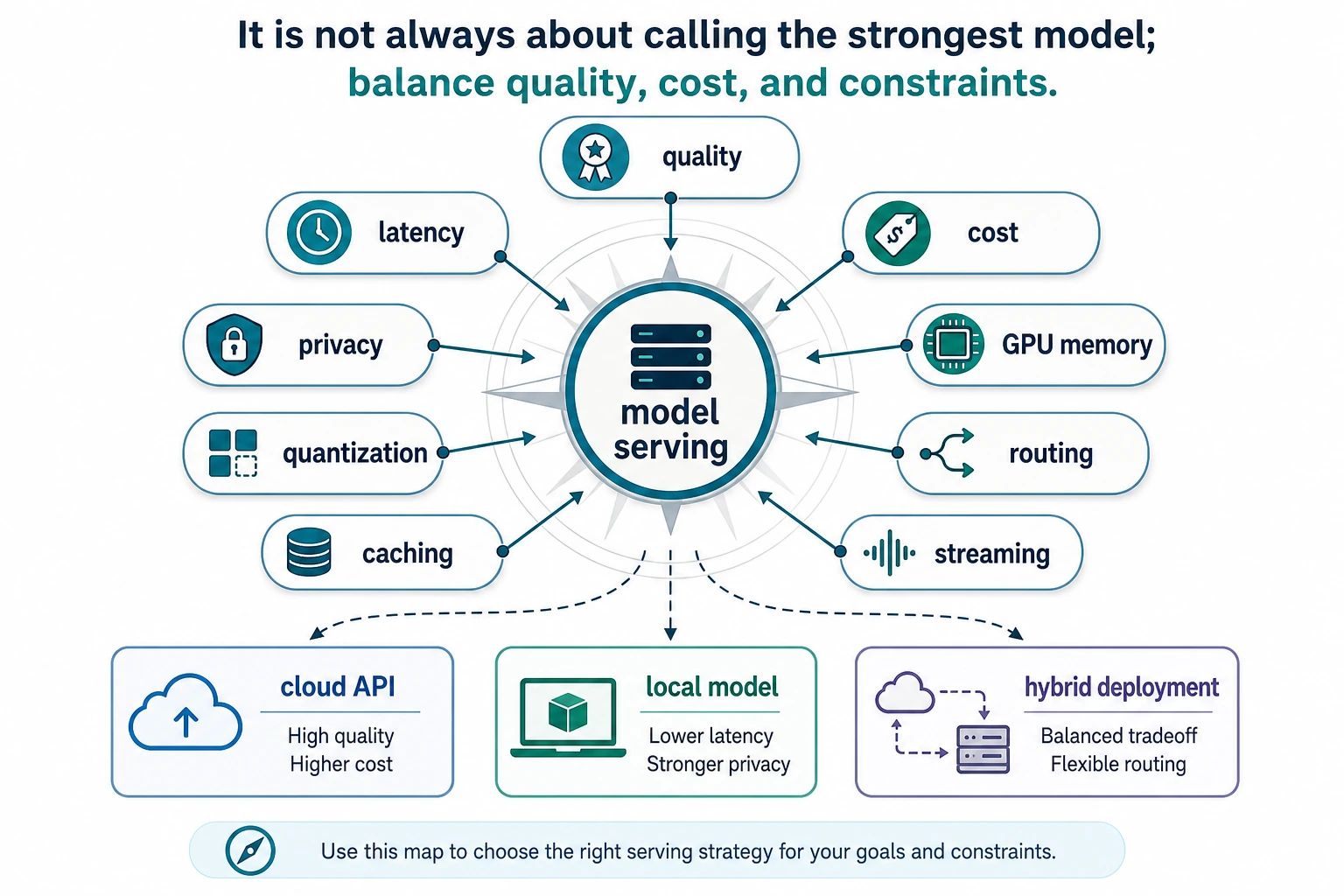

Deployment choices balance quality, latency, cost, privacy, and operational complexity. The strongest model is not always the model you should call.
Run a Model Route Check
Use this as a mental model before setting up real serving tools. It turns deployment into an explicit routing decision.
request = {
"privacy": "high",
"latency_ms": 800,
"quality_need": "medium",
"budget": "low",
}
if request["privacy"] == "high":
route = "local model or private endpoint"
elif request["quality_need"] == "high":
route = "frontier cloud model"
else:
route = "small hosted model"
print("route:", route)
print("contract:", "/v1/chat/completions")
print("watch:", "latency, cost, errors")
Expected output:
route: local model or private endpoint
contract: /v1/chat/completions
watch: latency, cost, errors
The route can change, but the application contract should stay stable.
Learn in This Order
| Step | Read | Practice Output |
|---|---|---|
| 1 | Local models | Load or call one local/private model and record limits |
| 2 | Inference servers | Expose model calls through a service endpoint |
| 3 | Unified API | Keep one application interface for multiple providers |
Pass Check
You pass this chapter when you can explain where the model runs, how the app calls it, what can fail, and what metrics you watch: latency, cost, errors, rate limits, and fallback behavior.
The exit mini project is a small model gateway note or script that routes one request to a chosen model endpoint and records the decision reason.