A.9 Learning Resources Quick Reference

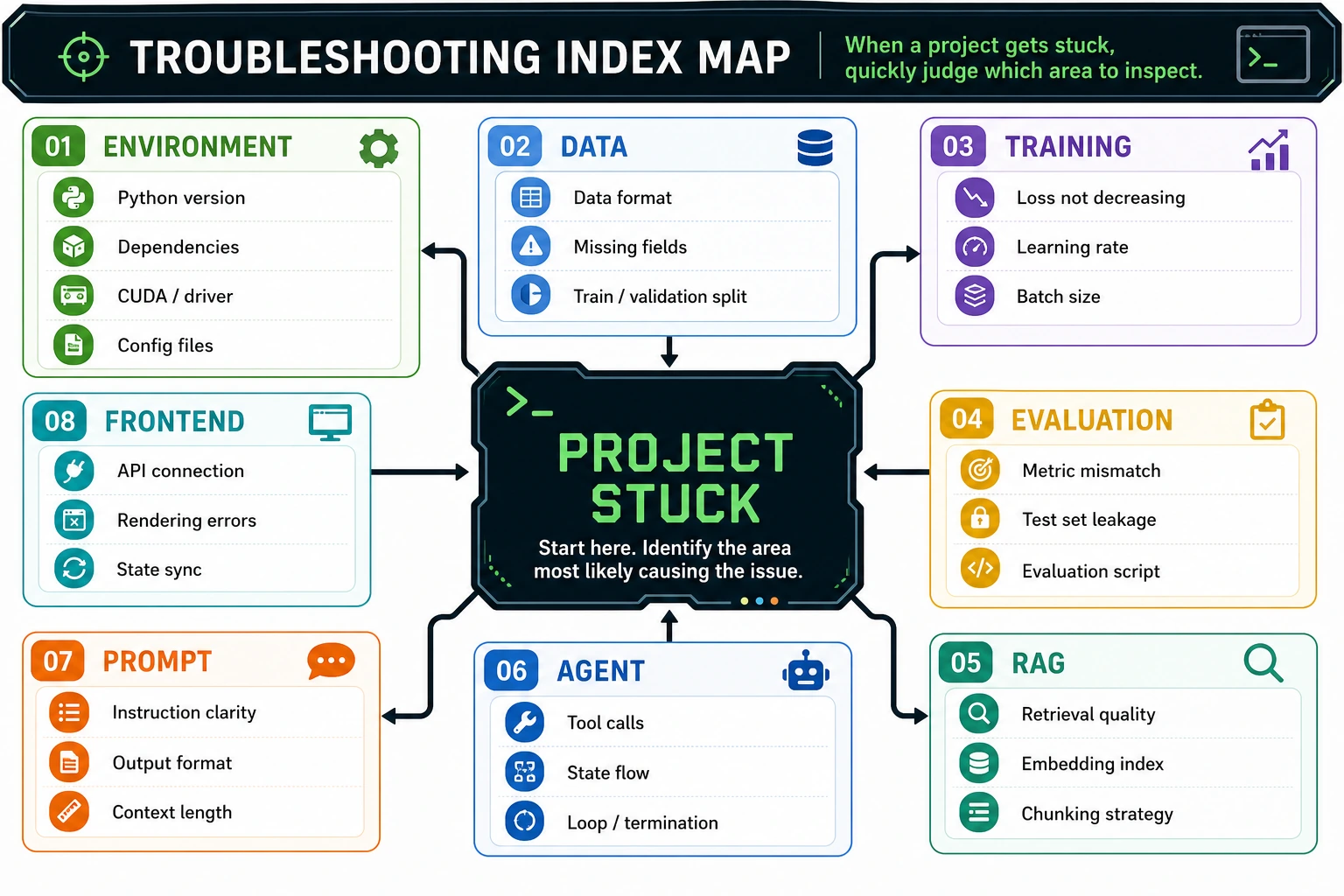
Use this page while building. Do not read it from top to bottom.
Environment checks
python --version
which python
pip --version
pip list
pwd
ls
For the docs site:
npm install
npm run start
npm run build
For NVIDIA GPU:
nvidia-smi
Baseline first
| Task | Try first |
|---|---|
| Tabular classification/regression | Linear model or tree model |
| Text classification | TF-IDF + LogisticRegression |
| Image classification | Transfer learning |
| Named entity recognition | Rules/dictionary baseline, then sequence model |
| Document Q&A | Keyword/BM25 retrieval, then RAG |
| Agent tool use | Single Agent + one safe tool |
Metrics
| Task | First metrics |
|---|---|
| Balanced classification | Accuracy, F1 |
| Imbalanced classification | Precision, Recall, F1, confusion matrix |
| Regression | MAE, RMSE, residual review |
| Retrieval / RAG | Hit@K, MRR, citation accuracy, human review |
| Agent | success rate, tool errors, cost, trace review |
Training warning signs
| Signal | Check first |
|---|---|
| Loss does not decrease | labels, loss function, learning rate, input format |
| Train good, validation poor | overfitting, leakage, distribution mismatch |
| Accuracy unchanged | weak features, wrong labels, model not learning |
| GPU out of memory | batch size, input length, model size |
| Unstable results | random seed, small data, inconsistent split |
RAG checklist
- Documents split correctly?
- Retrieval returns the right chunks?
- Answer includes sources?
- Answer truly uses the retrieved content?
- Permission filtering and no-answer behavior exist?
Agent checklist
- Start with single-turn Q&A.
- Add one tool.
- Add strict parameter schema.
- Add logs and trace replay.
- Add permission boundary and stop condition.
Prompt template
You are a ____.
Your task is ____.
Input:
Output format:
Constraints:
If information is insufficient, say so clearly.
Minimal training loop
data = [(1.0, 2.0), (2.0, 4.0), (3.0, 6.0)]
w = 0.0
lr = 0.01
for epoch in range(3):
total_loss = 0.0
for x, y in data:
pred = w * x
error = pred - y
total_loss += error * error
grad = 2 * error * x
w -= lr * grad
print(f"epoch={epoch} w={w:.3f} loss={total_loss:.3f}")
Expected output:
epoch=0 w=0.521 loss=48.630
epoch=1 w=0.907 loss=26.580
epoch=2 w=1.192 loss=14.528
Read it as: data -> prediction -> loss -> gradients -> parameter update.