8.2.3 High-Performance Inference Serving
If the previous section was about:
- whether the model can run locally
then this section is about a more realistic layer:
Can the model reliably handle requests in production?
This is also the first real wall many projects hit when they move from demo to production.
Learning Objectives
- Understand inference serving keywords such as throughput, latency, batching, and queues
- Understand why “it can run” does not mean “it can serve”
- Read a minimal batching-based inference service design
- Build your first intuition for inference serving optimization problems
First, Build a Map
Inference serving is easier to understand by thinking in terms of “how requests come in, how they queue, how they are batched, and how results are returned”:
So what this section really wants to solve is:
- Why successfully running a model once is completely different from serving it
- Why inference serving is naturally a problem of queuing, batching, and resource balance
Why Are Local Inference and Inference Serving Different?
Local inference cares about “does it produce an output?”
For example:
- Can a prompt get an answer?
- Can an image be generated?
Inference serving cares about “how many requests can it handle at the same time?”
Once you go online, you have to deal with:
- multiple requests arriving at once
- traffic spikes
- resource limits
- timeouts
So the core question of inference serving becomes:
How do you balance speed and throughput when resources are limited?
A Better Analogy for Beginners
You can think of inference serving as:
- a restaurant kitchen serving meals
Local inference is more like:
- cooking one meal at home and asking whether you can make it
Inference serving is more like:
- a lunch rush with lots of orders coming in at once
- how the kitchen queues orders, combines them, and keeps customers from waiting too long
This analogy is useful for beginners because it helps you first grasp:
- inference serving is fundamentally a traffic-organization problem
First, Distinguish the Two Most Important Terms
Latency
How long one request has to wait.
Throughput
How many requests can be handled per unit of time.
These two metrics often trade off against each other.
For example:
- if the batch gets larger, throughput may increase
- but the waiting time for a single request may also get longer
So inference serving is not about making one metric as high as possible, but about finding a balance.
Why Is Batching So Important?
An Intuitive View
If 8 requests arrive almost at the same time, you can:
- run them one by one separately
or you can:
- combine them into one batch and run them together
The second approach is usually more efficient on hardware.
A Minimal Example
requests = [12, 8, 15]
batch_size = 8
for r in requests:
num_batches = (r + batch_size - 1) // batch_size
print("needs", num_batches, "batches")
Expected output:
needs 2 batches
needs 1 batches
needs 2 batches
Here requests is an intentionally simplified list of work sizes. The point is the ceiling division: once work exceeds the batch size, serving has to split it across multiple model runs.
What Is This Code Teaching?
It is teaching you:
Inference serving is not about thinking in terms of “one request,” but more like thinking in terms of “queues and batches.”
A Simple Decision Table for Beginners
| Phenomenon | Which Layer Is More Worth Checking First? |
|---|---|
| A single request is fast, but the system cannot handle the overall load | Throughput and batching |
| Responses are slow, but the GPU is not fully utilized | Queueing and batch organization |
| Requests suddenly time out when traffic increases | Queue length and concurrency control |
| A single benchmark looks great, but production is still bad | Service-layer scheduling, not the model itself |
This table is useful for beginners because it breaks “slow inference serving” into several more concrete directions for investigation.
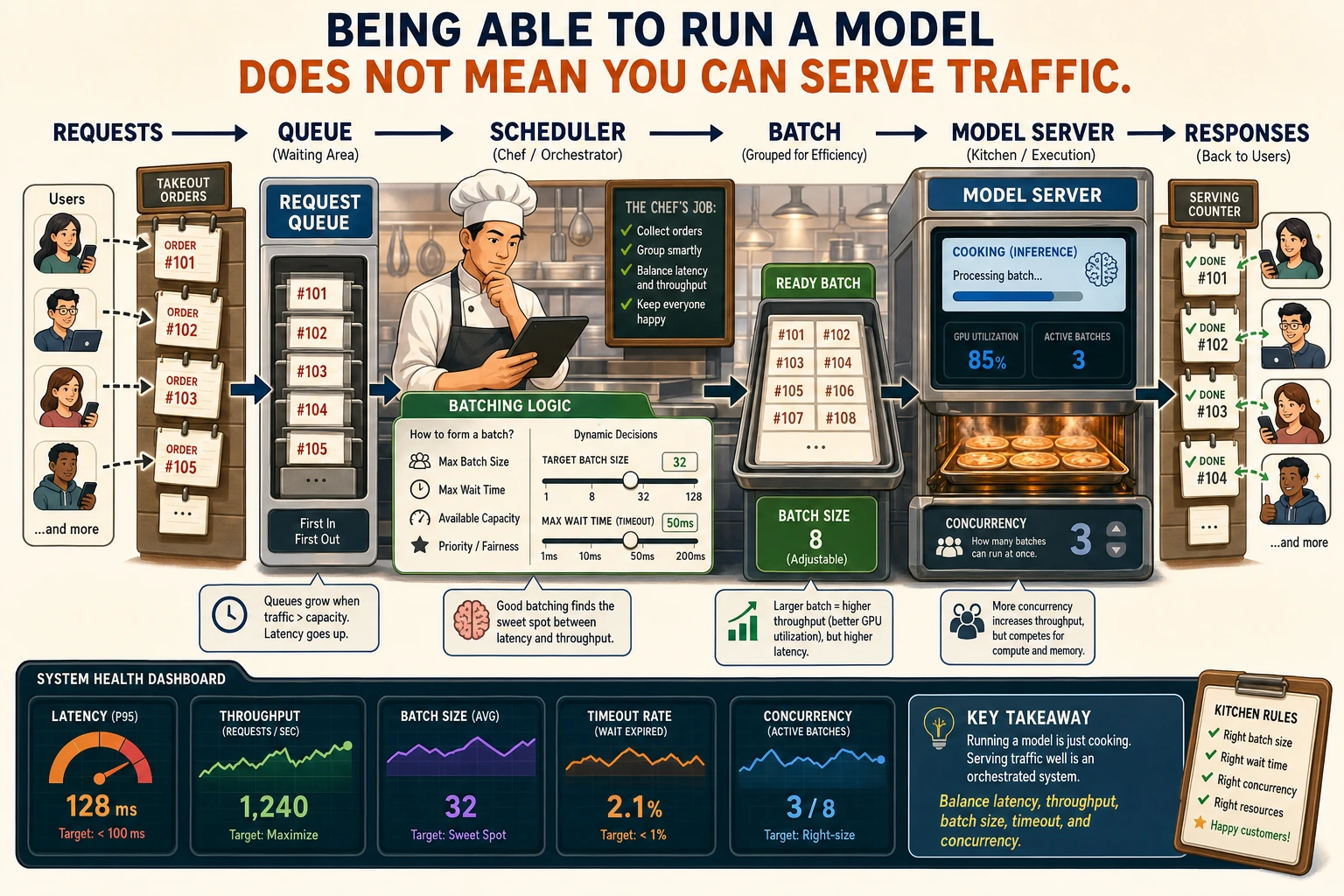
Requests do not go straight into the model. They first queue up, then get batched, and then are executed. Batching can improve throughput, but it also increases waiting time, so serving optimization is always about balancing latency and throughput.
Why Are Queues a Core Component of High-Performance Serving?
Because Requests Do Not Arrive in a Neat Order
Real traffic often has:
- peaks
- valleys
- bursts
Without a queue, the system can easily:
- suddenly crash
- drop requests directly
A Minimal Queue Example
from collections import deque
queue = deque(["req1", "req2", "req3", "req4", "req5"])
batch_size = 2
while queue:
batch = []
for _ in range(min(batch_size, len(queue))):
batch.append(queue.popleft())
print("run batch:", batch)
Expected output:
run batch: ['req1', 'req2']
run batch: ['req3', 'req4']
run batch: ['req5']
This example is simple, but it already shows:
- requests are queued first
- then they are executed in batches
This is the most basic behavior pattern of many inference services.
Concurrency and Batching Are Not the Same Thing
This is one of the easiest places for beginners to get confused.
Concurrency
Multiple requests move through the system at the same time.
Batching
Multiple requests are combined into one batch at the model layer and computed together.
So you can remember it like this:
- concurrency is a scheduling-layer problem
- batching is a model-execution-layer problem
These two often appear together, but they are not the same.
A Minimal Inference Service Main Loop
from collections import deque
queue = deque(["q1", "q2", "q3", "q4"])
batch_size = 2
def run_model(batch):
return [f"answer_for_{item}" for item in batch]
while queue:
batch = []
for _ in range(min(batch_size, len(queue))):
batch.append(queue.popleft())
results = run_model(batch)
for item, result in zip(batch, results):
print(item, "->", result)
Expected output:
q1 -> answer_for_q1
q2 -> answer_for_q2
q3 -> answer_for_q3
q4 -> answer_for_q4
Why Is This Code Important?
Because it already includes the most important skeleton of a high-performance inference service:
- enqueue
- batch
- infer
- return results
This chain is the actual essence of “serving.”
The Safest Default Order When You Build an Inference Service for the First Time
A more stable order is usually:
- Make sure a single request can return reliably
- Then introduce a queue
- Then add batching
- Finally tune batch size and resource utilization
This is usually much easier than chasing “maximum throughput” from the start.
Why Is High-Performance Inference Serving Always About Balance?
You usually have to trade off among these dimensions:
- larger batch size means higher throughput
- smaller batch size means faster response
- keeping the model resident is faster, but uses more resources
- more instances are more stable, but cost more
This means:
Inference serving optimization is not absolute optimization, but balanced optimization under business constraints.
The Metrics Worth Watching in Real Services
At a minimum, you usually want to monitor:
- average latency
- P95 / P99 latency
- queue length
- batch utilization
- error rate
- GPU / CPU utilization
These metrics tell you:
- whether the bottleneck is on the request side
- or on batching
- or on model execution
A Simple Monitoring Table for Beginners
| Metric | What Question Should You Ask First? |
|---|---|
| Average / P95 latency | How long did users actually wait? |
| Queue length | Are requests piling up? |
| Batch utilization | Are we really making full use of the hardware? |
| GPU / CPU utilization | Is the bottleneck in model execution or somewhere else? |
This table is useful for beginners because it turns “monitor many metrics” into a few more intuitive questions.
The Most Common Mistakes
Only Looking at a Single Inference Benchmark
What really matters in production is performance under overall traffic.
Setting the Batch Size Very Large Right Away
Throughput may go up, but latency may get dragged down.
Being Able to Run the Model, But Not Knowing How to Inspect Queues and Resource Utilization
This makes it very hard to truly understand where the system bottleneck is.
Summary
The most important thing in this section is not memorizing a specific inference-serving term, but understanding:
The core of high-performance inference serving is turning model calls from “single executions” into a system that can balance throughput, latency, and resource usage under real traffic.
That is also the fundamental difference from simply “getting the model to run locally.”
If You Turn This Into a Project or System Design, What Is Most Worth Showing?
What is most worth showing is usually not:
- “the model can run concurrently”
but rather:
- How requests are queued and batched
- How you balance throughput and latency
- What the most important production monitoring metrics are
- When the bottleneck is the queue, and when it is model execution
That way, other people can more easily see that:
- you understand serving-based inference
- you are not just able to call a model
Exercises
- Explain in your own words: why are batching and concurrency not the same thing?
- Think about this: if your product requires very low latency, would you prefer a large batch or a small batch?
- Design a minimal monitoring checklist for an inference service.
- Why do we say the real challenge of inference serving is “balance,” not pushing one metric to the extreme?