8.4.3 API Design and Serviceization
When building LLM applications, many people can write a local script, but once they move to serviceization, things quickly get messy. The real question is not “Can you write an endpoint?”, but:
Can this endpoint be called reliably by others for a long time?
This section is here to answer that question.
Learning Goals
- Understand the most basic things an LLM service API should define
- Learn how to design clear request and response structures
- Understand key service concepts such as idempotency, error returns,
trace_id, and version management - Read and understand a minimal API processing loop
Beginner terminology bridge
API design becomes much easier once these words are no longer mysterious:
| Term | Beginner meaning | In this lesson |
|---|---|---|
API | Application Programming Interface, a stable way for one program to call another program | The service entry point that other code depends on |
endpoint | A specific callable address, such as /api/v1/chat | The URL path where a capability is exposed |
schema | A rule that defines which fields are allowed and required | It keeps request and response structures predictable |
payload | The data body sent with a request | In this lesson, it is usually the user query and related metadata |
trace_id | A unique ID for following one request through the system | It helps connect API logs, retrieval logs, model logs, and errors |
idempotency | Repeating the same request does not create uncontrolled side effects | It matters when retries happen after timeouts or network failures |
Do not memorize these as vocabulary only. In a real system, these terms are the pieces that let frontend, backend, logs, evaluation, and deployment cooperate.
Why API design is not “just wrapping some JSON”
What does a bad interface look like?
bad_request = {
"msg": "What is the refund policy?"
}
bad_response = {
"text": "Refunds are available within 7 days"
}
What’s wrong here?
- What is
msg? User message? System message? - No
trace_id - No error structure
- No version information
- No context field
What is a good API design doing?
At its core, it answers:
- What does the input look like?
- What does the output look like?
- How should errors be represented?
- Can it stay stable when called 10 times or 100,000 times?
In other words, API design is not “just writing an entry point”; it is defining:
The contract between the system and the outside world.
First, design the request structure
A minimal request structure usually needs at least these fields
queryuser_id(optional)session_id(for multi-turn scenarios)metadata(optional)
A clearer request object
request = {
"query": "What is the refund policy?",
"user_id": 1,
"session_id": "sess_001",
"metadata": {
"channel": "web"
}
}
print(request)
Expected output:
{'query': 'What is the refund policy?', 'user_id': 1, 'session_id': 'sess_001', 'metadata': {'channel': 'web'}}
Here, you can already feel:
- What the query is
- Who sent it
- Which session it belongs to
- What extra context is included
This is much better than “passing only a string.”
Then, design the response structure
Why must the response also be standardized?
Because real consumers are often not just people, but also:
- Frontend applications
- Other services
- Logging systems
- Evaluation systems
They all need to consume the result reliably.
A more robust response structure
response = {
"trace_id": "trace_001",
"answer": "A refund can be requested within 7 days after purchase, provided the learning progress is below 20%.",
"sources": [
{"id": "doc_001", "section": "Refund Policy"}
],
"usage": {
"prompt_tokens": 120,
"completion_tokens": 35
}
}
print(response)
Expected output:
{'trace_id': 'trace_001', 'answer': 'A refund can be requested within 7 days after purchase, provided the learning progress is below 20%.', 'sources': [{'id': 'doc_001', 'section': 'Refund Policy'}], 'usage': {'prompt_tokens': 120, 'completion_tokens': 35}}
Why are these fields valuable?
trace_id: makes it easy to trace the request pathanswer: the actual business outputsources: helps with citation and verificationusage: helps with cost analysis
Error responses must also be designed
Many systems only design successful responses
But in real engineering, the more common issues are actually:
- Invalid parameters
- Upstream timeouts
- Insufficient permissions
- Empty knowledge base
A unified error structure
error_response = {
"trace_id": "trace_002",
"error": {
"code": "INVALID_ARGUMENT",
"message": "query cannot be empty"
}
}
print(error_response)
Expected output:
{'trace_id': 'trace_002', 'error': {'code': 'INVALID_ARGUMENT', 'message': 'query cannot be empty'}}
This step is very important because it makes the caller clearly understand:
- What went wrong
- What category the error belongs to
- Whether it is worth retrying
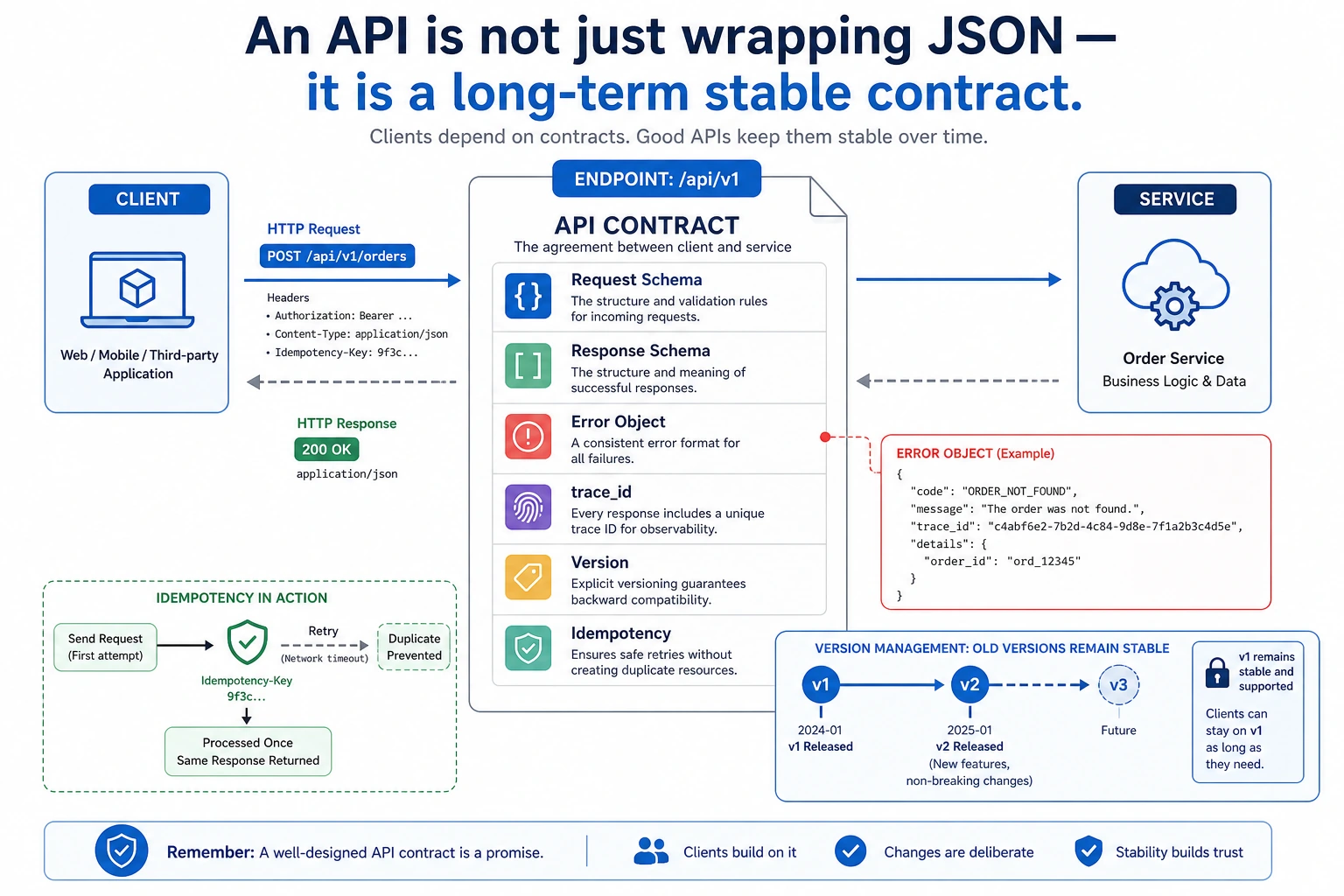
An API is a system contract, not just JSON. When reading the diagram, focus on request schema, response schema, error object, trace_id, and version, because they determine whether the interface can be consumed stably over time by the frontend, evaluation systems, and other services.
A minimal runnable service handling function
Simulate an API handler with pure Python first
def handle_chat(request):
trace_id = "trace_demo_001"
if "query" not in request or not request["query"].strip():
return {
"trace_id": trace_id,
"error": {
"code": "INVALID_ARGUMENT",
"message": "query cannot be empty"
}
}
answer = f"System reply: {request['query']}"
return {
"trace_id": trace_id,
"answer": answer,
"sources": [],
"usage": {"prompt_tokens": 12, "completion_tokens": 8}
}
print(handle_chat({"query": "What is the refund policy?"}))
print(handle_chat({"query": ""}))
Expected output:
{'trace_id': 'trace_demo_001', 'answer': 'System reply: What is the refund policy?', 'sources': [], 'usage': {'prompt_tokens': 12, 'completion_tokens': 8}}
{'trace_id': 'trace_demo_001', 'error': {'code': 'INVALID_ARGUMENT', 'message': 'query cannot be empty'}}
What is this code actually teaching?
It teaches you:
- Validate the request first
- Every request should have a
trace_id - Both success and failure need a unified structure
This is already the most important layer of service design.
Why is idempotency important?
What is idempotency?
Simply put:
Repeated calls with the same request should produce the same or a controlled result.
This is especially important in these scenarios:
- Retries
- Re-sending after a timeout
- Network instability
Which APIs need idempotency more?
Especially:
- Ticket creation
- Payment initiation
- Order changes
A pure question-answering API is usually more like a “read-only operation,” so idempotency is easier to handle.
Why can’t version management be added later?
Once others integrate with your API, changing fields casually becomes hard
If today the response returns:
answer
and tomorrow it changes to:
response_text
the caller will break immediately.
A simple versioning strategy
api_info = {
"version": "v1",
"endpoint": "/api/v1/chat"
}
print(api_info)
Expected output:
{'version': 'v1', 'endpoint': '/api/v1/chat'}
Even for a small project, it is best to build version awareness early.
A FastAPI example closer to a real service
If you want to see a style closer to a real backend, take a look at this minimal version.
pip install fastapi uvicorn
uvicorn app:app --reload
from fastapi import FastAPI
from pydantic import BaseModel, Field
class ChatRequest(BaseModel):
query: str = Field(min_length=1)
session_id: str | None = None
app = FastAPI()
@app.post("/api/v1/chat")
def chat(payload: ChatRequest):
return {
"trace_id": "trace_demo_002",
"answer": f"System reply: {payload.query}",
"session_id": payload.session_id,
}
Although this code is simple, it is already closer to a real service because ChatRequest is a request schema. FastAPI uses it to validate the payload before your business logic runs. In production, you would usually add authentication, structured errors, logging, and a real trace ID generator.
If your goal is a “knowledge-base-driven courseware generation assistant,” what should the minimal API look like?
These systems usually need more than just a /chat endpoint.
At minimum, they often have interfaces like these:
| Endpoint | What it is responsible for |
|---|---|
/courseware/generate | Generate courseware structure or document based on a topic |
/courseware/preview | Preview structured results first |
/documents/ingest | Upload and parse PDF / Word / PPT |
/retrieval/search | Debug retrieval results |
When building for the first time, a more stable default approach is usually:
- Start with only one
generateendpoint - Return structured results or an export link first
- Then add debugging and batch interfaces
A very small request structure can be defined like this first:
generate_request = {
"topic": "Discount word problems",
"audience": "Upper elementary school",
"doc_format": "word",
"style": "classroom explanation",
"exercise_count": 3,
}
print(generate_request)
Expected output:
{'topic': 'Discount word problems', 'audience': 'Upper elementary school', 'doc_format': 'word', 'style': 'classroom explanation', 'exercise_count': 3}
The value of this object is:
- It turns the slots collected during multi-turn conversation into actual service API parameters
Hands-on: Simulate a Courseware Generation API Contract
Before building a real FastAPI endpoint, first write the request validation and response contract in pure Python. This makes the service boundary clear.
REQUIRED_FIELDS = ["topic", "audience", "doc_format", "style", "exercise_count"]
def validate_generate_request(payload):
missing = [field for field in REQUIRED_FIELDS if not payload.get(field)]
if missing:
return False, {
"code": "INVALID_ARGUMENT",
"message": f"missing fields: {missing}"
}
if payload["doc_format"] not in {"word", "ppt"}:
return False, {
"code": "INVALID_ARGUMENT",
"message": "doc_format must be word or ppt"
}
return True, None
def handle_generate(payload):
trace_id = "trace_courseware_001"
ok, error = validate_generate_request(payload)
if not ok:
return {"trace_id": trace_id, "error": error}
return {
"trace_id": trace_id,
"status": "accepted",
"courseware": {
"title": payload["topic"],
"audience": payload["audience"],
"format": payload["doc_format"],
"sections": ["Knowledge Review", "Example Explanation", "Classroom Practice"],
}
}
generate_request = {
"topic": "Discount word problems",
"audience": "Upper elementary school",
"doc_format": "word",
"style": "classroom explanation",
"exercise_count": 3,
}
print(handle_generate(generate_request))
print(handle_generate({"topic": "Discount word problems", "doc_format": "pdf"}))
Expected output:
{'trace_id': 'trace_courseware_001', 'status': 'accepted', 'courseware': {'title': 'Discount word problems', 'audience': 'Upper elementary school', 'format': 'word', 'sections': ['Knowledge Review', 'Example Explanation', 'Classroom Practice']}}
{'trace_id': 'trace_courseware_001', 'error': {'code': 'INVALID_ARGUMENT', 'message': "missing fields: ['audience', 'style', 'exercise_count']"}}
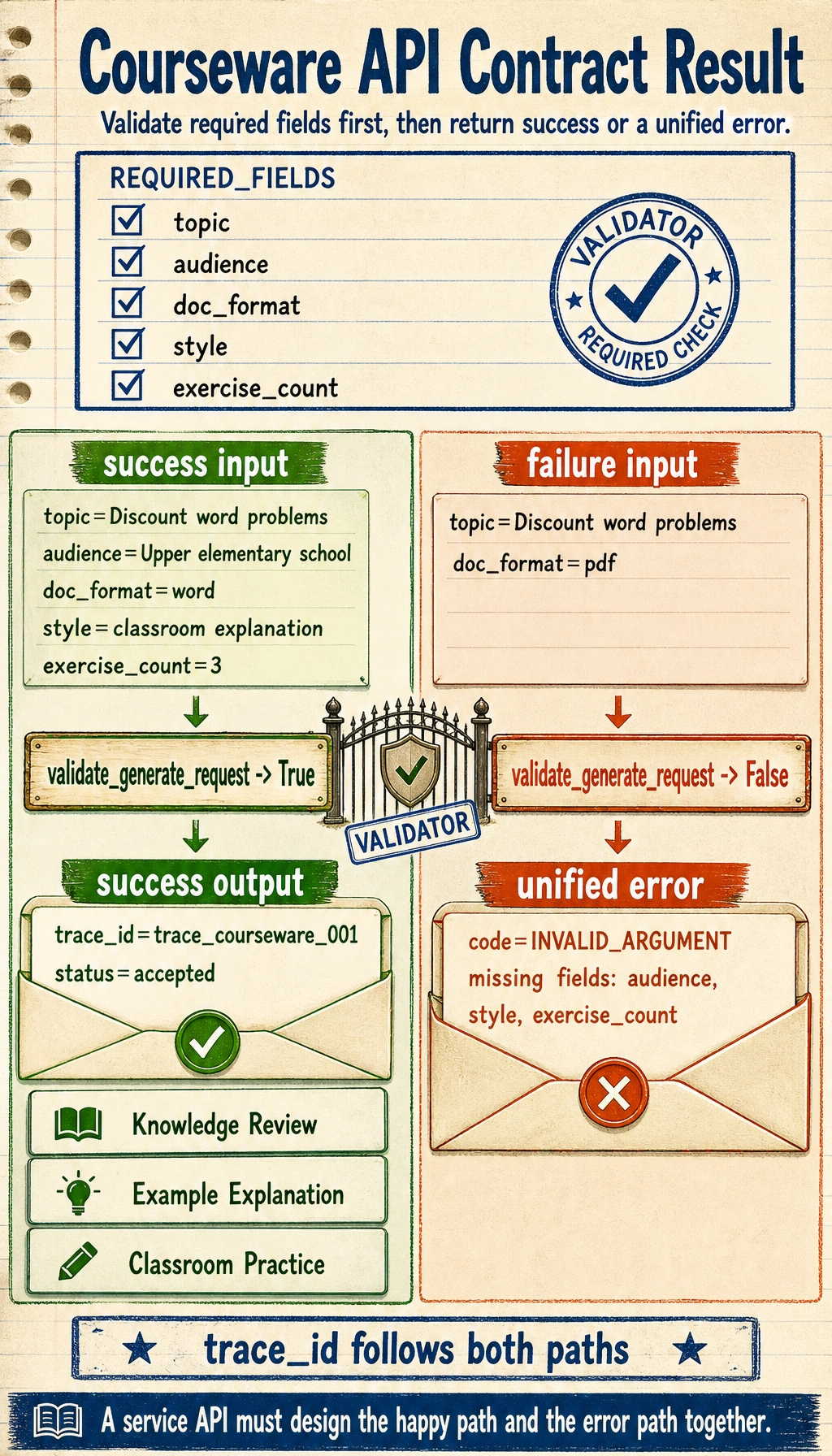
Follow the two lanes through the same validation gate. The complete payload becomes status=accepted courseware, while the incomplete payload stops at a unified INVALID_ARGUMENT error before business logic runs.
This exercise is useful because it forces you to design success and failure together. A service is not ready just because it can return a happy-path answer.
Common mistakes beginners make most often
The request structure is too loose
It may feel convenient at first, but it becomes very painful later.
The error structure is inconsistent
This makes it increasingly difficult for the frontend and other services to integrate.
No trace_id
When something goes wrong, it becomes hard to trace the request path.
Binding the API too tightly to a single business logic from the start
This makes future expansion very difficult.
Summary
The most important thing in this section is not getting the API to run, but understanding:
The core of API design is turning input, output, errors, and traceability into a stable system contract.
Once the contract is clear, the service can truly be relied on by others for the long term.
Exercises
- Add support for a
session_idfield tohandle_chat(). - Design a unified error code enum, such as
INVALID_ARGUMENT,TIMEOUT, andNOT_FOUND. - Think about it: if this were a “ticket creation” API, how would you consider idempotency?
- Explain in your own words: why is API design essentially about defining a system contract?