5.3.1 Unsupervised Learning Roadmap: Find Structure Without Labels
Unsupervised learning starts when the data has no labels. The model does not tell you the final truth. It helps you discover possible structure.
Look at the Structure Map First
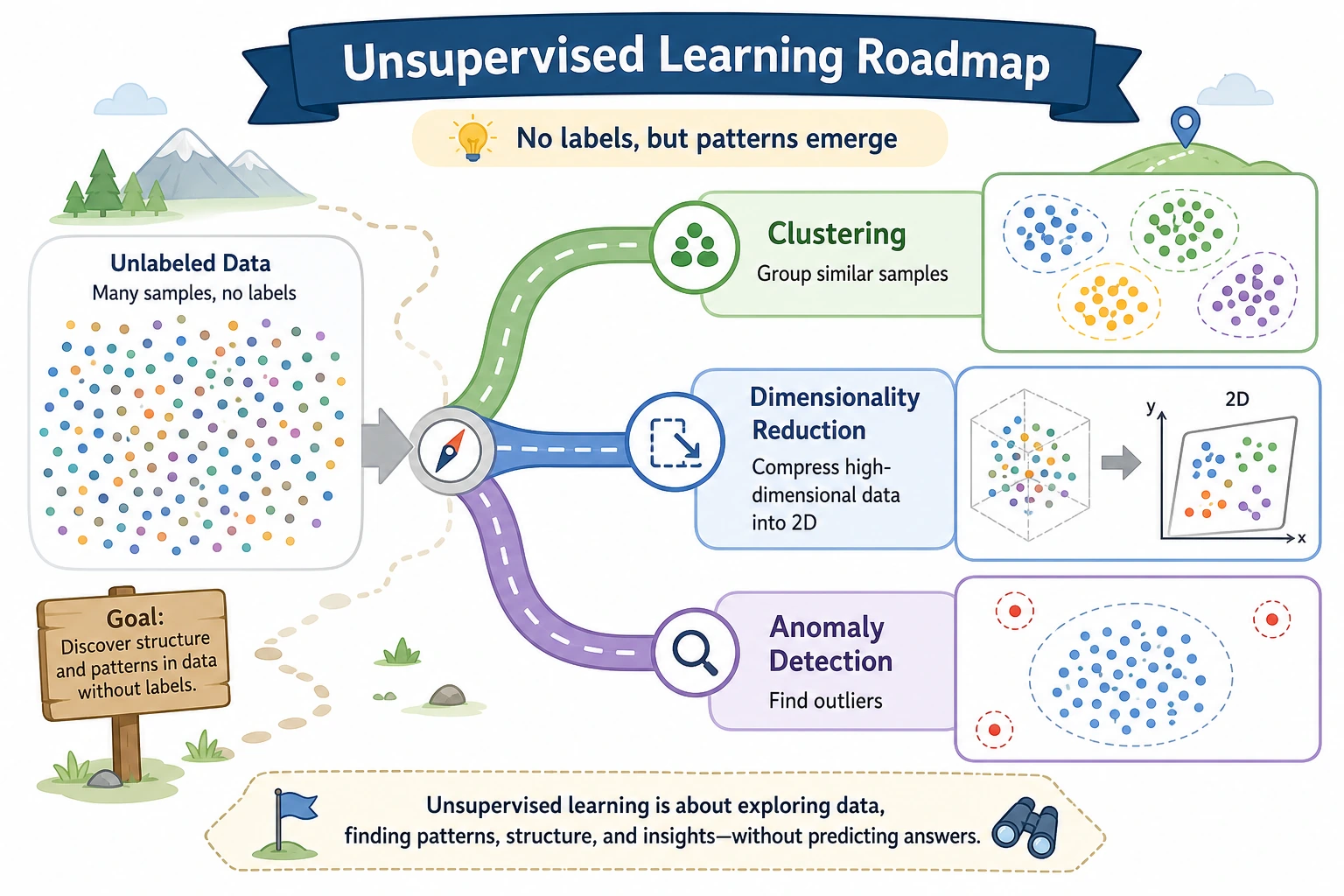
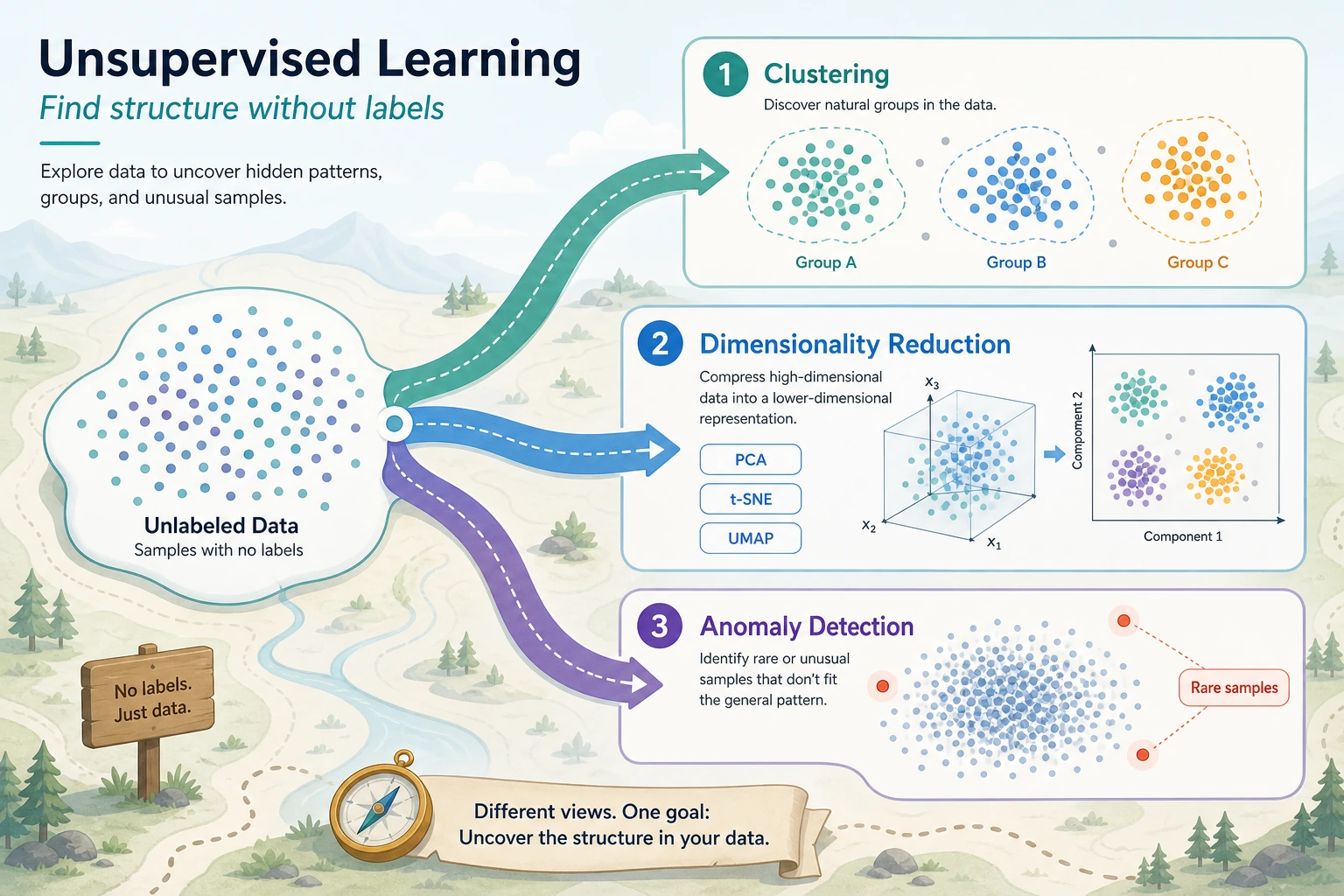
| If you want to... | Start with... |
|---|---|
| find natural groups | clustering |
| compress high-dimensional data | dimensionality reduction |
| find unusual points | anomaly detection |
The key question is not "is the label correct?" but "does this structure have evidence and meaning?"
Run One Clustering Baseline
Create unsupervised_first_loop.py and run it after installing scikit-learn.
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
X, _ = make_blobs(n_samples=30, centers=3, random_state=7, cluster_std=0.8)
model = KMeans(n_clusters=3, random_state=7, n_init="auto")
labels = model.fit_predict(X)
print("cluster_count:", len(set(labels)))
print("first_five_labels:", labels[:5].tolist())
print("inertia:", round(model.inertia_, 2))
Expected output:
cluster_count: 3
first_five_labels: [2, 0, 0, 1, 0]
inertia: 43.44
Clustering gives group IDs, not human meaning. You still need charts, feature summaries, and domain interpretation.
Learn in This Order
| Order | Read | What to practice |
|---|---|---|
| 1 | 5.3.2 Clustering | K-Means, cluster interpretation, bad cluster choices |
| 2 | 5.3.3 Dimensionality Reduction | PCA, visualization, compression |
| 3 | 5.3.4 Anomaly Detection | outliers, thresholds, alert evidence |
Pass Check
You pass this roadmap when you can explain what structure you are looking for, run one unsupervised model, and write one cautious interpretation instead of treating the output as absolute truth.