5.4.1 Evaluation Roadmap: Trust the Score Before Tuning
Model evaluation answers: is the model actually good, or did the score only look good by accident?
Look at the Evaluation Map First
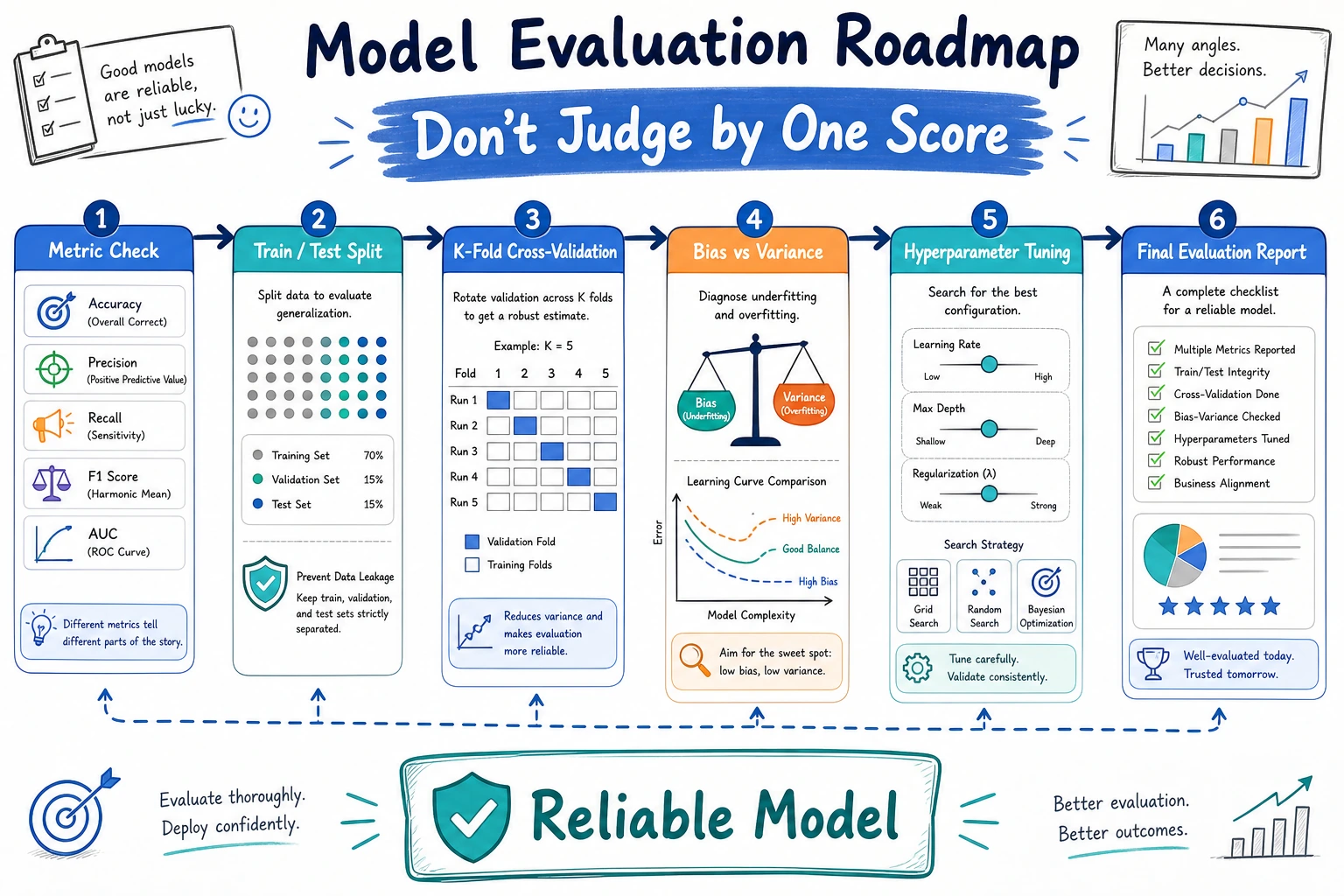
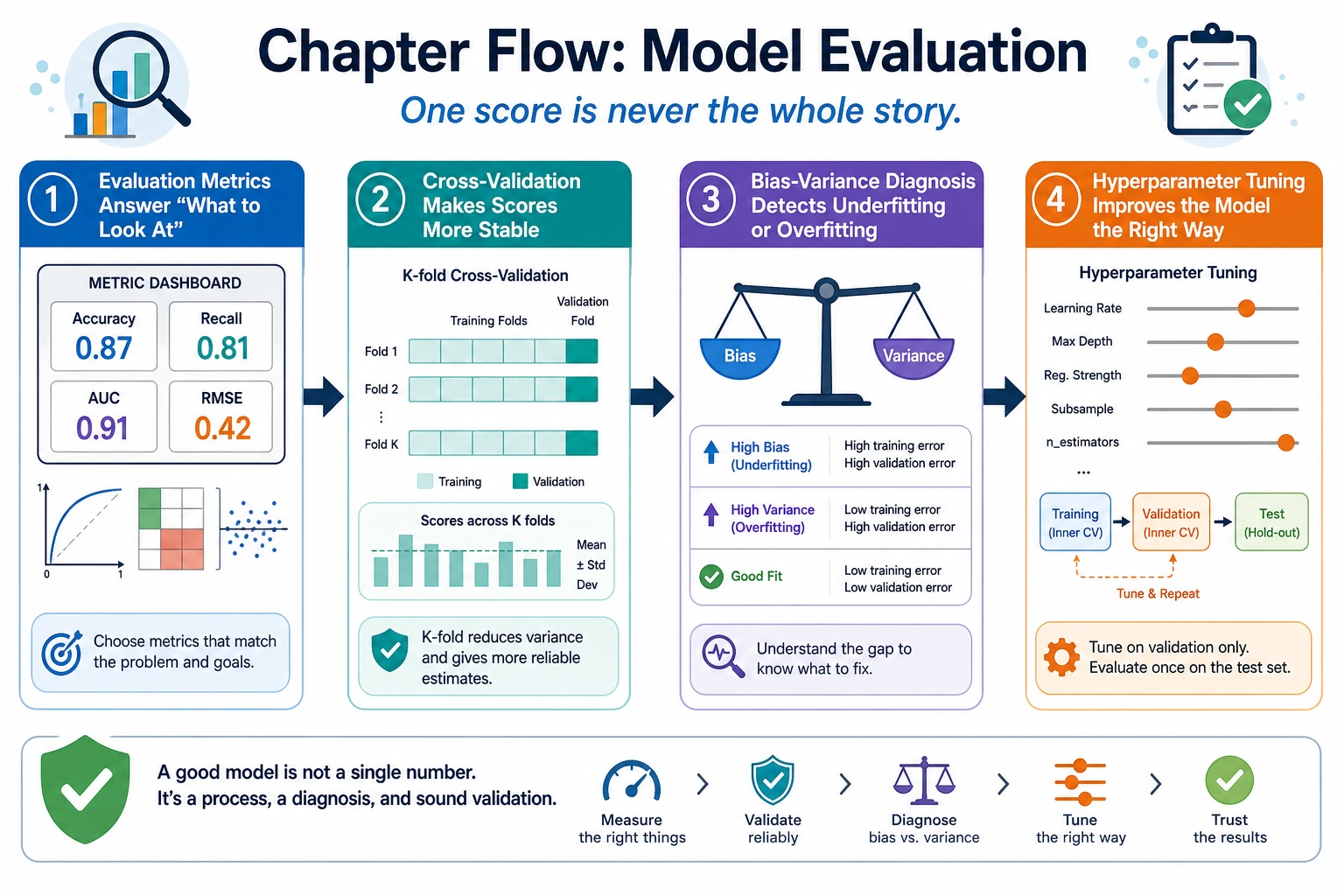
| Topic | First question |
|---|---|
| metrics | what score matches the task? |
| cross-validation | is the score stable across splits? |
| bias-variance | is the model too simple or too flexible? |
| tuning | which parameter change is actually better? |
Run One Cross-Validation Check
Create evaluation_first_loop.py and run it after installing scikit-learn.
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
X, y = load_iris(return_X_y=True)
model = DecisionTreeClassifier(max_depth=2, random_state=42)
scores = cross_val_score(model, X, y, cv=5)
print("fold_scores:", [float(round(score, 3)) for score in scores])
print("mean_accuracy:", round(scores.mean(), 3))
Expected output:
fold_scores: [0.933, 0.967, 0.9, 0.867, 1.0]
mean_accuracy: 0.933
One score is a snapshot. Several folds tell you whether the result is stable enough to trust.
Learn in This Order
| Order | Read | What to practice |
|---|---|---|
| 1 | 5.4.2 Evaluation Metrics | accuracy, precision, recall, F1, R2, RMSE |
| 2 | 5.4.3 Cross-Validation | stable estimates, data split risk |
| 3 | 5.4.4 Bias and Variance | underfitting, overfitting, learning curves |
| 4 | 5.4.5 Hyperparameter Tuning | grid search, comparison records |
Pass Check
You pass this roadmap when you can choose a metric for the task, explain one score stability check, and avoid tuning before the evaluation method is trustworthy.