8.1.8 RAG Evaluation
Learning Objectives
By the end of this section, you will be able to:
- Understand why you cannot judge RAG quality from a single demo alone
- Distinguish the different goals of retrieval evaluation and answer evaluation
- Compute simple metrics on a small sample
- Build the engineering habit of “evaluate first, then optimize”
Why does RAG especially need evaluation?
Because it is not a single module
RAG is not one model. It usually includes at least:
- Document processing
- Retrieval
- Context assembly
- Answer generation
If any step goes wrong, the final answer can get worse.
So you cannot just ask, “Was the answer correct?”
You also need to ask:
- Was the right evidence not retrieved?
- Or was it retrieved but not used well?
- Or was the answer simply poorly written?
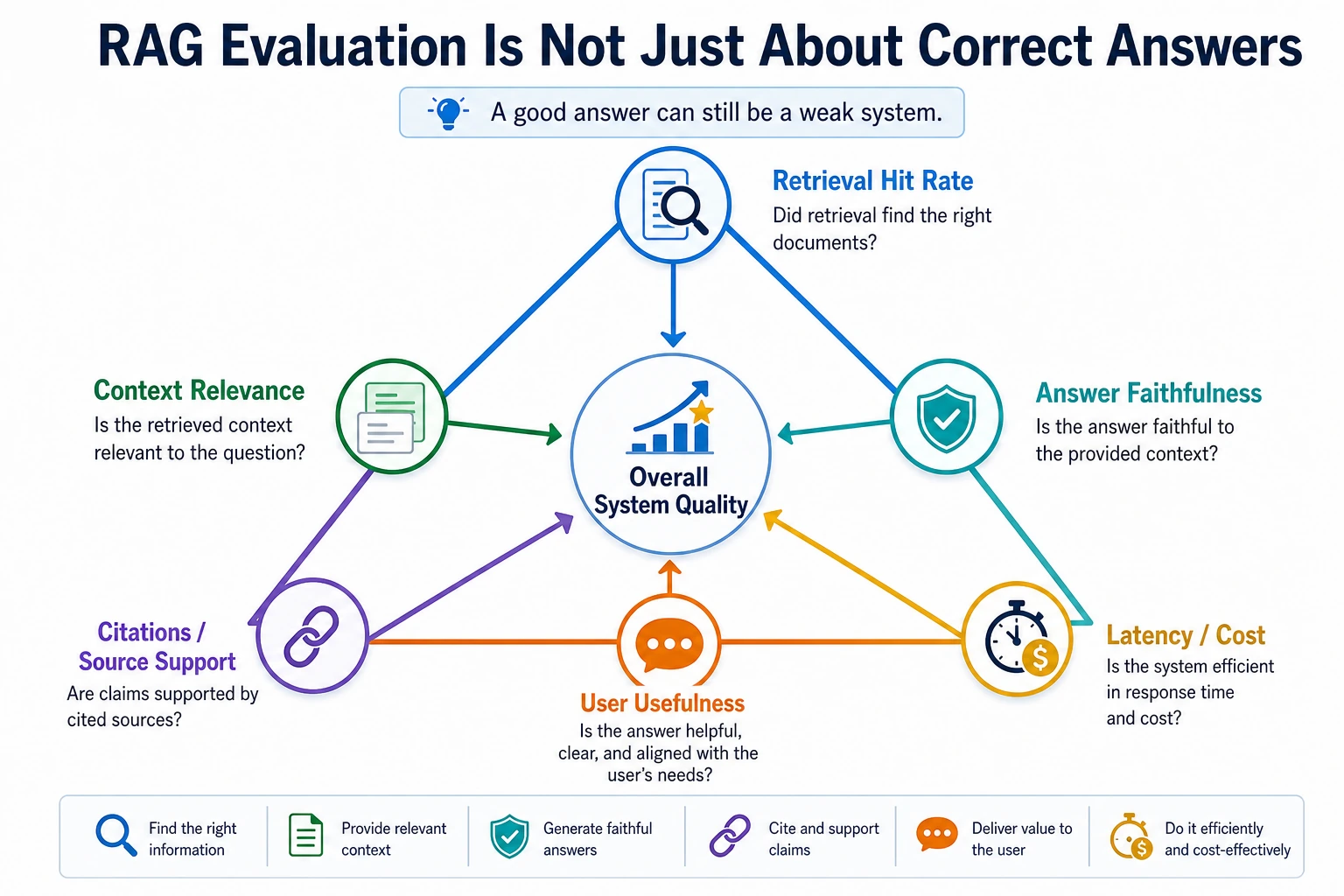
That is why RAG evaluation must be viewed in layers.
The first layer: retrieval evaluation
The most common intuitive metric: Hit@k
Hit@k is very simple:
Did the correct evidence appear in the top k retrieval results?
If the correct evidence for the user’s question is in the top 3, that counts as a hit.
Why is this metric important?
Because if the correct material is not retrieved at all, the generation step is almost impossible to get right consistently.
So:
Retrieval evaluation is the foundation of RAG evaluation.
The second layer: answer evaluation
Looking only at whether the response sounds fluent is far from enough
Answer evaluation should at least consider:
- Whether the answer is correct
- Whether it has evidence behind it
- Whether it is hallucinated
Common dimensions
| Dimension | What it focuses on |
|---|---|
| Correctness | Whether the facts in the answer are correct |
| Faithfulness | Whether it is based on the given materials |
| Relevance | Whether it answers the user’s question |
| Completeness | Whether it includes all key information |
In real business scenarios, different dimensions matter differently.
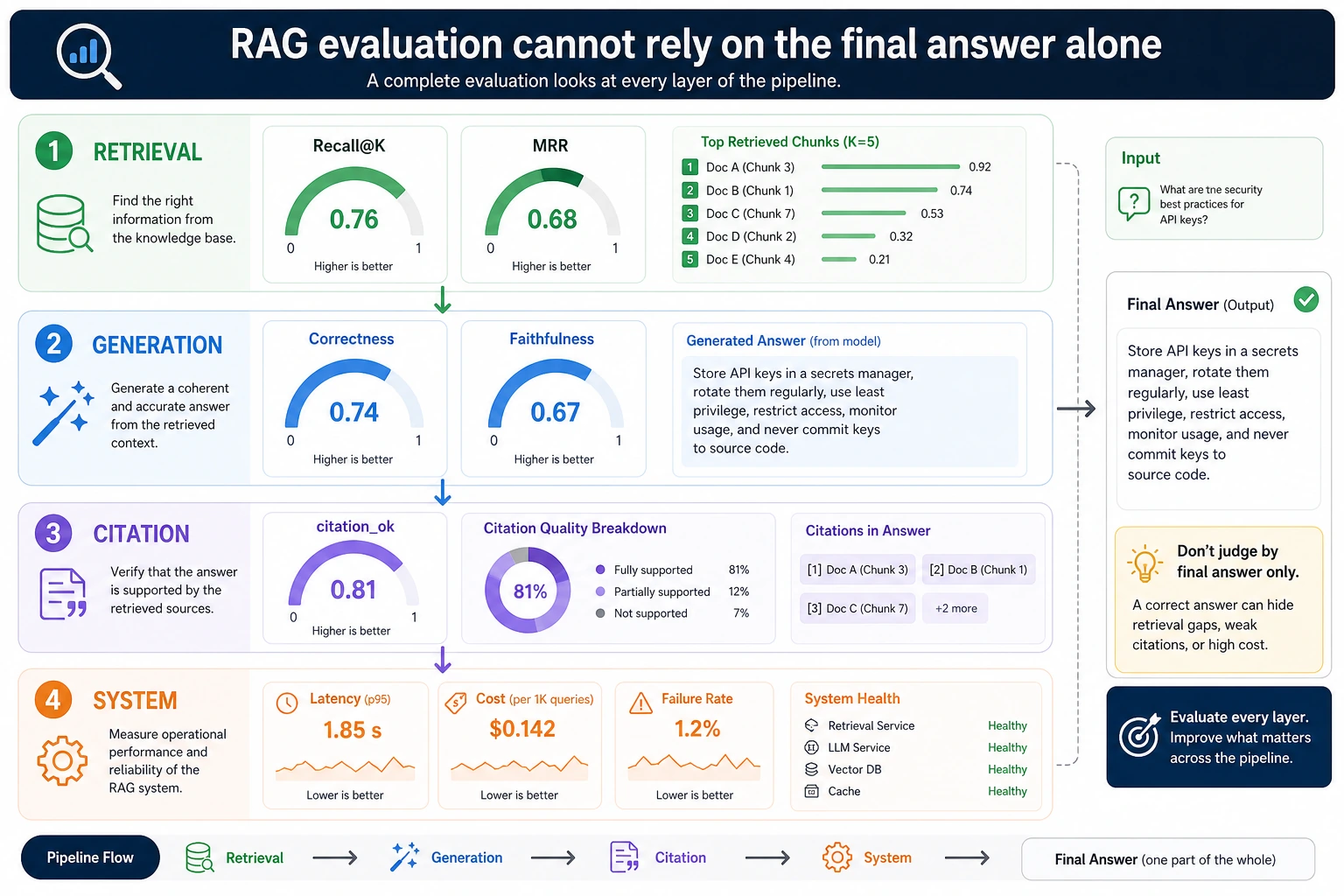

Good evaluation is a loop, not a one-time test: test set -> retrieval -> answer -> citation -> failure analysis -> fix -> re-evaluate.
Do not look only at the final answer score. First check whether the retrieval layer hit the right material, then whether the generation layer is complete and correct, and finally whether the citation layer truly supports the conclusion.
A minimal evaluation dataset
Below we manually construct a tiny evaluation set.
dataset = [
{
"question": "How long after purchase can I request a refund?",
"gold_doc": "Refund Policy",
"gold_answer": "A refund can be requested within 7 days after course purchase"
},
{
"question": "How do I get a certificate?",
"gold_doc": "Certificate Guide",
"gold_answer": "You can get a certificate after completing the project and passing the test"
}
]
predictions = [
{
"retrieved_docs": ["Refund Policy", "Learning Order"],
"answer": "A refund can be requested within 7 days after course purchase"
},
{
"retrieved_docs": ["Learning Order", "Certificate Guide"],
"answer": "You can get a certificate after completing the project and passing the test"
}
]
print(dataset)
print(predictions)
Expected output:
[{'question': 'How long after purchase can I request a refund?', 'gold_doc': 'Refund Policy', 'gold_answer': 'A refund can be requested within 7 days after course purchase'}, {'question': 'How do I get a certificate?', 'gold_doc': 'Certificate Guide', 'gold_answer': 'You can get a certificate after completing the project and passing the test'}]
[{'retrieved_docs': ['Refund Policy', 'Learning Order'], 'answer': 'A refund can be requested within 7 days after course purchase'}, {'retrieved_docs': ['Learning Order', 'Certificate Guide'], 'answer': 'You can get a certificate after completing the project and passing the test'}]
Read this dataset as two columns of truth and prediction: gold_doc / gold_answer are the reference, while retrieved_docs / answer are what your RAG system produced.
Computing a simple Hit@k
Runnable example
dataset = [
{
"question": "How long after purchase can I request a refund?",
"gold_doc": "Refund Policy"
},
{
"question": "How do I get a certificate?",
"gold_doc": "Certificate Guide"
}
]
predictions = [
{
"retrieved_docs": ["Refund Policy", "Learning Order"]
},
{
"retrieved_docs": ["Learning Order", "Certificate Guide"]
}
]
hits = 0
for item, pred in zip(dataset, predictions):
if item["gold_doc"] in pred["retrieved_docs"]:
hits += 1
hit_at_2 = hits / len(dataset)
print("Hit@2 =", round(hit_at_2, 4))
Expected output:
Hit@2 = 1.0
If the correct document appears in the top 2 results for every item, the value is 1.0.
The limitation of this metric
It can only tell you whether the right document was retrieved. It cannot tell you:
- Where it ranked
- Whether the final answer is actually correct
So it is only the first step.
Computing a simple answer accuracy score
The simplest Exact Match idea
In structured short-answer scenarios, you can start with the most straightforward method:
dataset = [
{
"gold_answer": "A refund can be requested within 7 days after course purchase"
},
{
"gold_answer": "You can get a certificate after completing the project and passing the test"
}
]
predictions = [
{
"answer": "A refund can be requested within 7 days after course purchase"
},
{
"answer": "You can get a certificate after completing the project and passing the test"
}
]
correct = 0
for item, pred in zip(dataset, predictions):
if item["gold_answer"] == pred["answer"]:
correct += 1
exact_match = correct / len(dataset)
print("Exact Match =", round(exact_match, 4))
Expected output:
Exact Match = 1.0
But real-world scenarios are often not that simple
The same correct answer can have many different phrasings. So online systems often also introduce:
- Semantic matching
- LLM-as-a-judge
- Manual sampling and review
Faithfulness: is the answer supported by evidence?
This is more important than “does it sound plausible?”
An answer may read very fluently, but if it was not derived from the retrieved materials, the risk is high.
A simplified checking idea
The example below is very rough, but it helps you understand the concept of whether an answer is supported by evidence.
evidence = "A refund can be requested within 7 days after course purchase"
answer = "A refund can be requested within 7 days after course purchase"
faithful = answer in evidence or evidence in answer
print("Supported by evidence:", faithful)
Expected output:
Supported by evidence: True
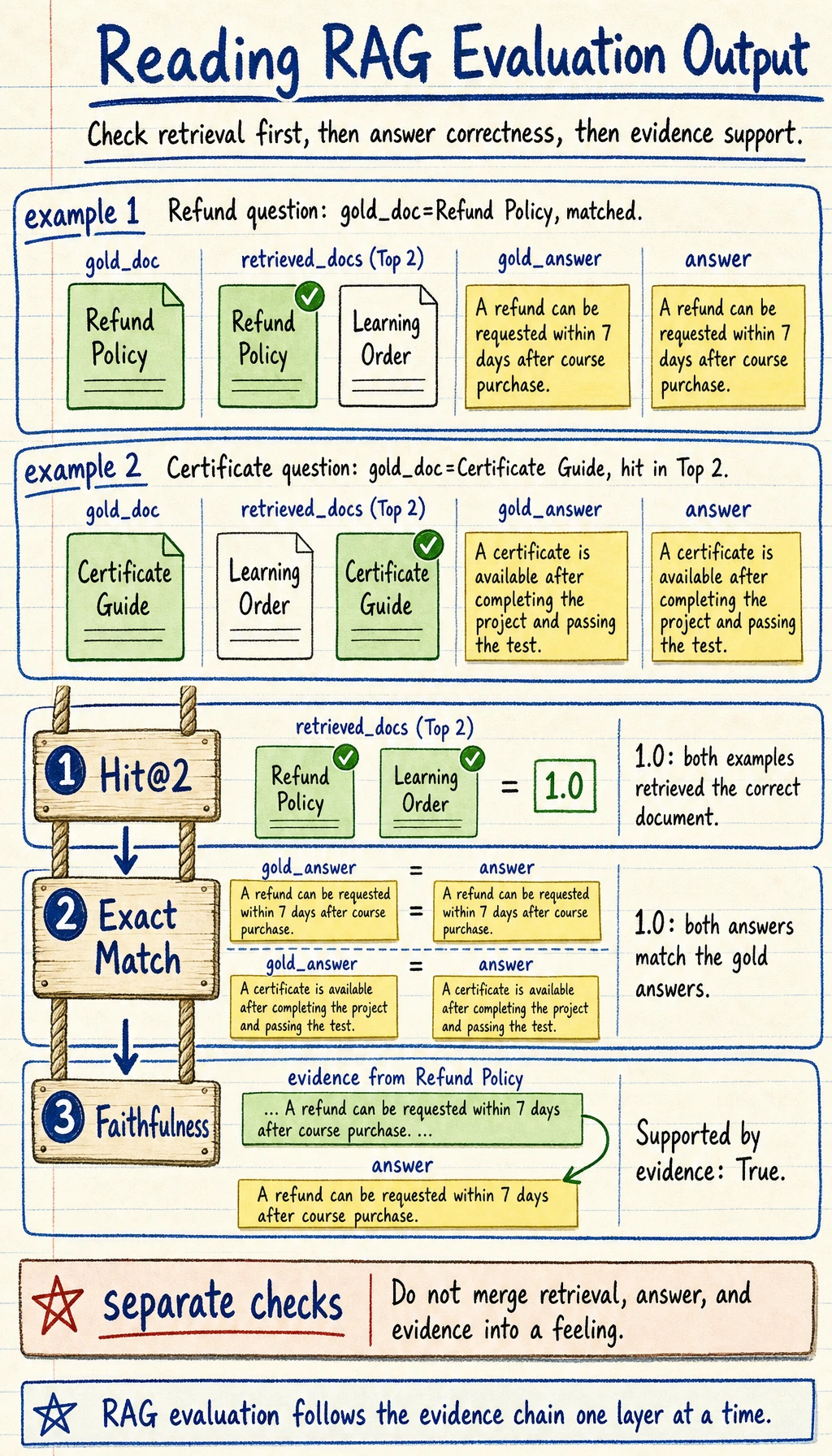
Real systems of course do not rely only on string matching, but the idea is correct:
The answer should be supported by the retrieval evidence as much as possible.

Split the answer into a few key conclusions, then link each one back to the evidence. What can be linked is supported; what cannot be linked is unsupported. This is more reliable than “the answer sounds fluent.”
How should the evaluation set be built?
Minimal usable evaluation set
It should include at least:
- The user question
- The reference answer
- The correct evidence document or evidence snippet
The evaluation set should cover different difficulty levels
For example:
- Simple factual Q&A
- Questions with paraphrased wording
- Cross-paragraph questions
- Easy-to-confuse questions
If the evaluation set is too narrow, optimization results can be misleading.
Online evaluation is also important
Offline evaluation cannot represent everything
No matter how good the offline dataset is, it cannot fully cover real user questions.
Common online signals
For example:
- Follow-up question rate
- User correction rate
- Likes / dislikes
- Manual quality inspection samples
A mature RAG system is usually evaluated with both offline evaluation and online feedback.
If your goal is a “knowledge-base-driven courseware generation assistant,” what should the evaluation set focus on?
This kind of project is not quite the same as a normal Q&A system. You are not only concerned with whether the answer sounds right. You also need to care about:
- Whether the topic materials were retrieved correctly
- Whether the practice questions were selected correctly
- Whether the final section was placed in the right position
- Whether the source can be traced back
So the evaluation table that fits this kind of project usually needs at least one more layer:
| Dimension | What it is closer to checking |
|---|---|
| Topic hit | Whether the core materials for this topic were found |
| Example retrieval | Whether materials suitable as teaching examples were found |
| Structural correctness | Whether concepts, examples, and exercises were placed in the right sections |
| Source completeness | Whether the final output can be traced back to the original materials |
You can think of it like this:
Evaluation for a courseware generation project is not just “answering correctly,” but “finding correctly, placing correctly, and citing correctly.”
A minimal evaluation example that looks more like a courseware generation project
dataset = [
{
"topic": "Discount word problems",
"gold_concepts": ["Discount = original price × discount rate"],
"gold_examples": ["If a product costs 100 yuan and is discounted to 80%, what is the final price?"],
}
]
prediction = {
"concepts": ["Discount = original price × discount rate"],
"examples": ["If a product costs 100 yuan and is discounted to 80%, what is the final price?"],
"source_refs": [{"doc_id": "word_001", "page_or_slide": 3}],
}
print(dataset[0])
print(prediction)
Expected output:
{'topic': 'Discount word problems', 'gold_concepts': ['Discount = original price × discount rate'], 'gold_examples': ['If a product costs 100 yuan and is discounted to 80%, what is the final price?']}
{'concepts': ['Discount = original price × discount rate'], 'examples': ['If a product costs 100 yuan and is discounted to 80%, what is the final price?'], 'source_refs': [{'doc_id': 'word_001', 'page_or_slide': 3}]}
This example is very small, but it helps beginners build the right evaluation intuition:
- The final object of evaluation is often not a single sentence answer
- It is an entire structured result
Common beginner mistakes
Only looking at one or two successful cases
A demo can be encouraging, but it cannot replace evaluation.
Evaluating only the answer, not the retrieval
Then it becomes hard to locate which layer caused the problem.
Changing the system without a fixed evaluation set
Without a fixed evaluation set, it is hard to tell whether you improved the system or just saw random fluctuation.
RAG project evaluation metrics summary
When working on a RAG project, do not just look at whether the answer sounds right. A more reliable approach is to split evaluation into four layers: retrieval, generation, citation, and system.
| Layer | Metric | Description |
|---|---|---|
| Retrieval layer | Hit rate, Recall@K, MRR | Whether the correct material was found and how high it ranked |
| Generation layer | Answer accuracy, completeness, consistency | Whether the model answered based on the material and whether it missed key conditions |
| Citation layer | Citation coverage, citation faithfulness | Whether the key conclusions in the answer can be traced to sources |
| System layer | Latency, cost, failure rate | Whether it can serve real users stably and at an acceptable cost |
For a minimal evaluation set, it is recommended to prepare 20–50 questions first, and for each question, write down the reference answer, the document that should be hit, and the key citations. That way, when you optimize chunking, embedding, reranking, or query rewriting, you can tell whether the system truly got better or whether only a few examples happened to look nicer.
Layered failure attribution table
The value of evaluation is not just producing a total score. It is also about helping you know what to fix next. You can put the table below into your experiment log and attribute every failure to a layer first.
| Failure symptom | Attribution layer | What to check | Next action |
|---|---|---|---|
| The correct document did not enter the top-k | Retrieval layer | Query, chunking, embedding, keyword matching | Adjust chunking, add hybrid retrieval, or use query rewrite |
| The correct document entered the top-k but not the final context | Context layer | Context packing, deduplication, length limits | Adjust ranking, compression, or packing strategy |
| The context contains evidence but the answer misses key conditions | Generation layer | Prompt, answer format, whether the model follows evidence | Require step-by-step evidence-based answering and preserve constraints |
| The answer conclusion is correct but the citation does not support it | Citation layer | source_refs, citation snippets, answer sentences | Perform citation authenticity checks and forbid unsupported citations |
| Offline evaluation looks good but users still ask follow-up questions frequently | Product layer | Real question distribution, evaluation-set coverage | Add online questions to the evaluation set |
If you only look at “final answer accuracy,” these issues will be mixed together. Layered attribution makes optimization actions clearer: if retrieval is wrong, do not start by tuning the prompt; if citations are wrong, do not only check whether the answer is fluent.
A reusable evaluation record template
When working on a RAG project, it is recommended to keep a fixed format for every evaluation round. Even if you start with only a dozen questions, this is much more stable than looking at a single demo.
| Field | Example | Purpose |
|---|---|---|
question | How long after purchase can I request a refund? | User question |
gold_doc | Refund Policy | The material that should be hit |
gold_answer | A refund can be requested within 7 days after course purchase | Reference answer or key fact |
retrieved_docs | Refund Policy; Learning Order | Documents actually retrieved |
answer | Refund can be requested within 7 days | System answer |
citation_ok | true | Whether the citation supports the answer |
failure_type | none / retrieval / generation / citation | Failure attribution |
notes | Correct hit and supported by citation | Manual notes |
A minimal CSV can look like this:
question,gold_doc,gold_answer,retrieved_docs,answer,citation_ok,failure_type,notes
How long after purchase can I request a refund?,Refund Policy,A refund can be requested within 7 days after course purchase,"Refund Policy;Learning Order",A refund can be requested within 7 days after course purchase,true,none,Correct hit and supported by citation
How do I get a certificate?,Certificate Guide,You can get a certificate after completing the project and passing the test,"Learning Order;Certificate Guide",You can get a certificate after completing the project,false,generation,Missing the key condition of passing the test
The key point of this template is not the number of fields, but that each sample can answer three questions: what should have been hit, what was actually hit, and whether the final answer was supported by evidence.
Acceptance rubric for courseware-generation RAG
If the project goal is to generate courseware or learning materials, evaluation should not stop at the Q&A level. The rubric below can be used as an acceptance checklist for a portfolio project.
| Level | Retrieval requirement | Generation requirement | Citation requirement |
|---|---|---|---|
| Practice level | Can hit topic-related materials | Can generate basic answers or snippets | Can display the source filename |
| Project level | Can retrieve concepts, examples, and exercises by topic and content type | Can organize output into fixed sections | Each key section has a source |
| Portfolio level | Has a fixed evaluation set and failure samples | Can explain which failures came from retrieval, generation, or templates | Key conclusions can be traced line by line to the source text |
| Interview level | Can compare baseline, hybrid retrieval, reranking, and other strategies | Can explain the trade-offs among quality, cost, and latency | Can perform citation authenticity spot checks and record improvements |
You can put this table directly into your project README. It shows that you did not just build a “can answer questions” demo, but are evaluating a knowledge-base-driven system with an engineering mindset.
Summary
The most important takeaway from this section is:
RAG evaluation is not a nice-to-have; it is the steering wheel of system iteration.
Without evaluation, you can only optimize by feel. With evaluation, you can know where the problem is and whether a change truly brought improvement.
Exercises
- Add 3 more questions to the evaluation set, and manually write
gold_docandgold_answerfor them. - Modify
predictionsso that one answer is wrong on purpose, then recompute Hit@k and Exact Match. - Think about this: if Hit@k is very high but the final answer is still often wrong, which layer is the problem more likely to be in?