7.8.1 Project Roadmap: Choose Prompt, RAG, or Finetuning
This capstone turns Chapter 7 into one engineering decision: is the problem task expression, missing knowledge, unstable format, unsafe behavior, or weak evaluation?
See the Project Route First
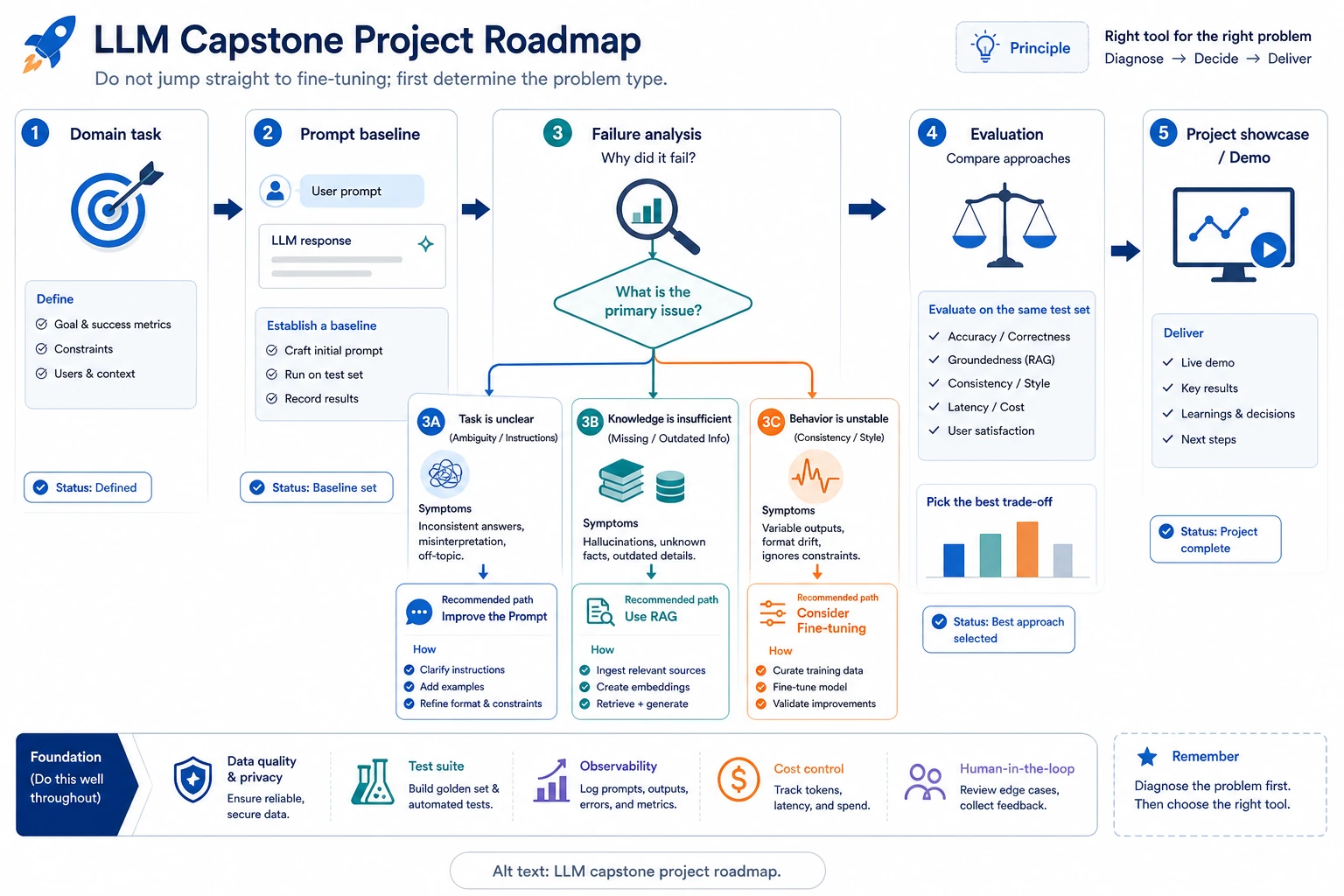
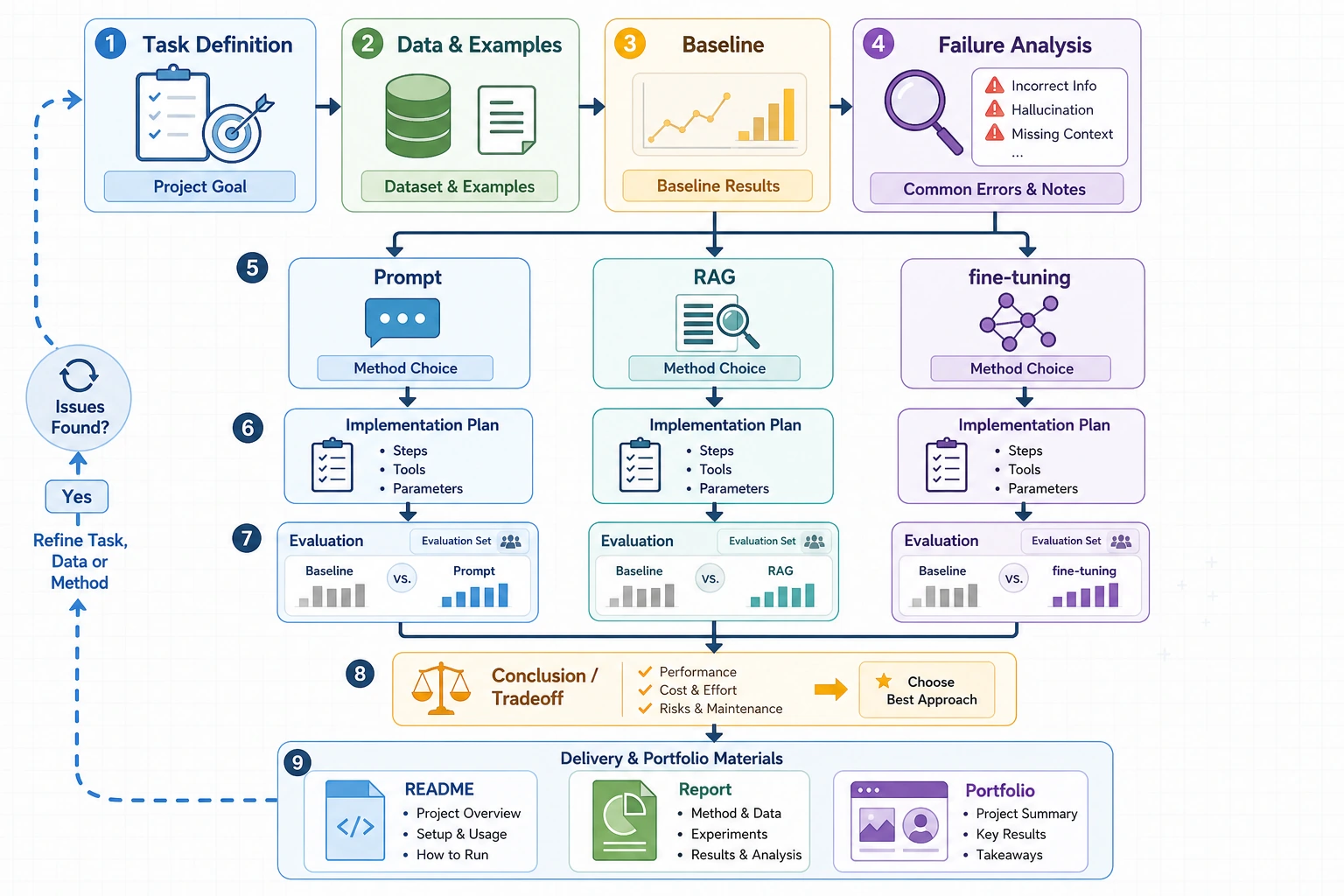
Do not start with the strongest model or the most complex framework. Start with a small domain task, a prompt baseline, fixed examples, and a failure log.
Run an Evidence Pack Check
Use this tiny project log before writing a report. It forces you to show the baseline, improvement, next route, and whether finetuning is actually justified.
project = {
"task": "classify course questions",
"baseline_pass_rate": 0.62,
"prompt_v2_pass_rate": 0.78,
"rag_needed": True,
"finetune_needed": False,
}
improvement = project["prompt_v2_pass_rate"] - project["baseline_pass_rate"]
print("task:", project["task"])
print("improvement:", round(improvement, 2))
print("next_route:", "RAG" if project["rag_needed"] else "Prompt")
print("fine_tune_now:", project["finetune_needed"])
Expected output:
task: classify course questions
improvement: 0.16
next_route: RAG
fine_tune_now: False
If your project cannot fill these fields, keep the project smaller. A clear comparison beats a large but untestable demo.
Learn in This Order
| Step | Do | Evidence |
|---|---|---|
| 1 | Pick one domain task | One-sentence task definition and 10 fixed examples |
| 2 | Build a prompt baseline | Prompt version, outputs, pass/fail notes |
| 3 | Classify failure types | Task wording, missing knowledge, format drift, safety boundary |
| 4 | Choose the next method | Prompt iteration, RAG, or finetuning decision note |
| 5 | Package the result | README, run command, screenshots, failure case, next steps |
If you want a guided starter, run 7.8.4 Hands-on: Full Chapter 7 Workshop before designing your own domain project.
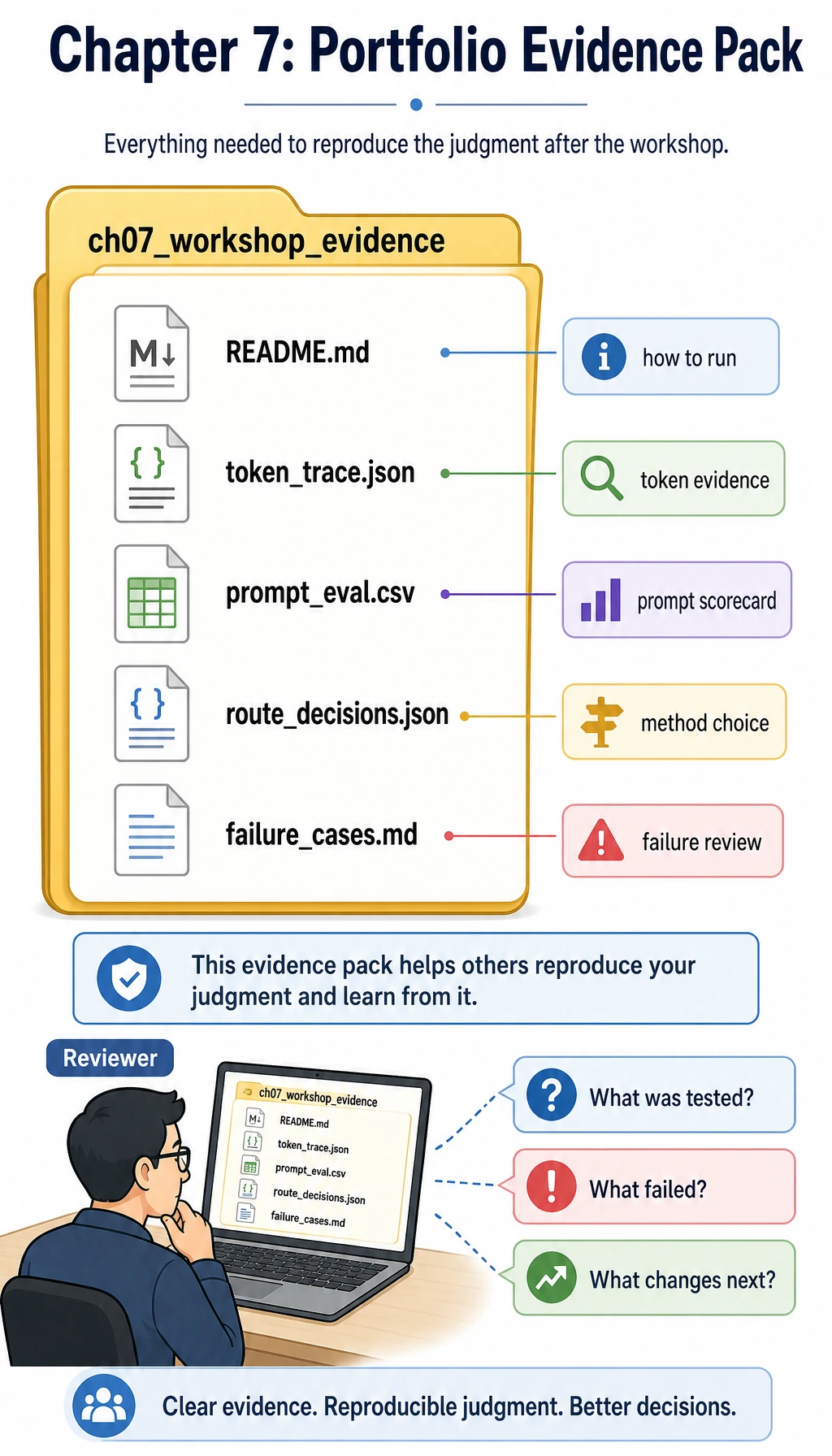
Project Deliverable Standards
| Deliverable | Minimum Standard | Stronger Portfolio Version |
|---|---|---|
| README | Goal, run command, model or API choice, sample input/output | Add method trade-offs, cost notes, evaluation, and retrospective |
| Examples | At least 10 fixed cases | Compare prompt, RAG, finetuning, or rule-based versions |
| Evaluation | Clear pass/fail rule | Add scores, failure-type statistics, and regression notes |
| Prompt/data record | Save prompt versions or sample format | Add schema validation, data quality checks, and safety notes |
| Presentation | Screenshot or short GIF proving it runs | Explain why the chosen route beats alternatives |
Pass Check
You pass this chapter when you can clearly explain “why not finetune here,” “why RAG is needed here,” or “why this prompt change works,” with a fixed evaluation set rather than a single good answer.
The final project can be basic: compare two prompt versions on one domain task. The stronger version adds RAG or a small finetuning experiment, but only after the baseline and failure log prove the need.