7.4.1 Pretraining Roadmap: Data, Objective, Engineering
Pretraining is how a model first learns broad language patterns. The useful engineering view is: clean data, choose an objective, train at scale, track risk.
Look at the Pretraining Triangle First
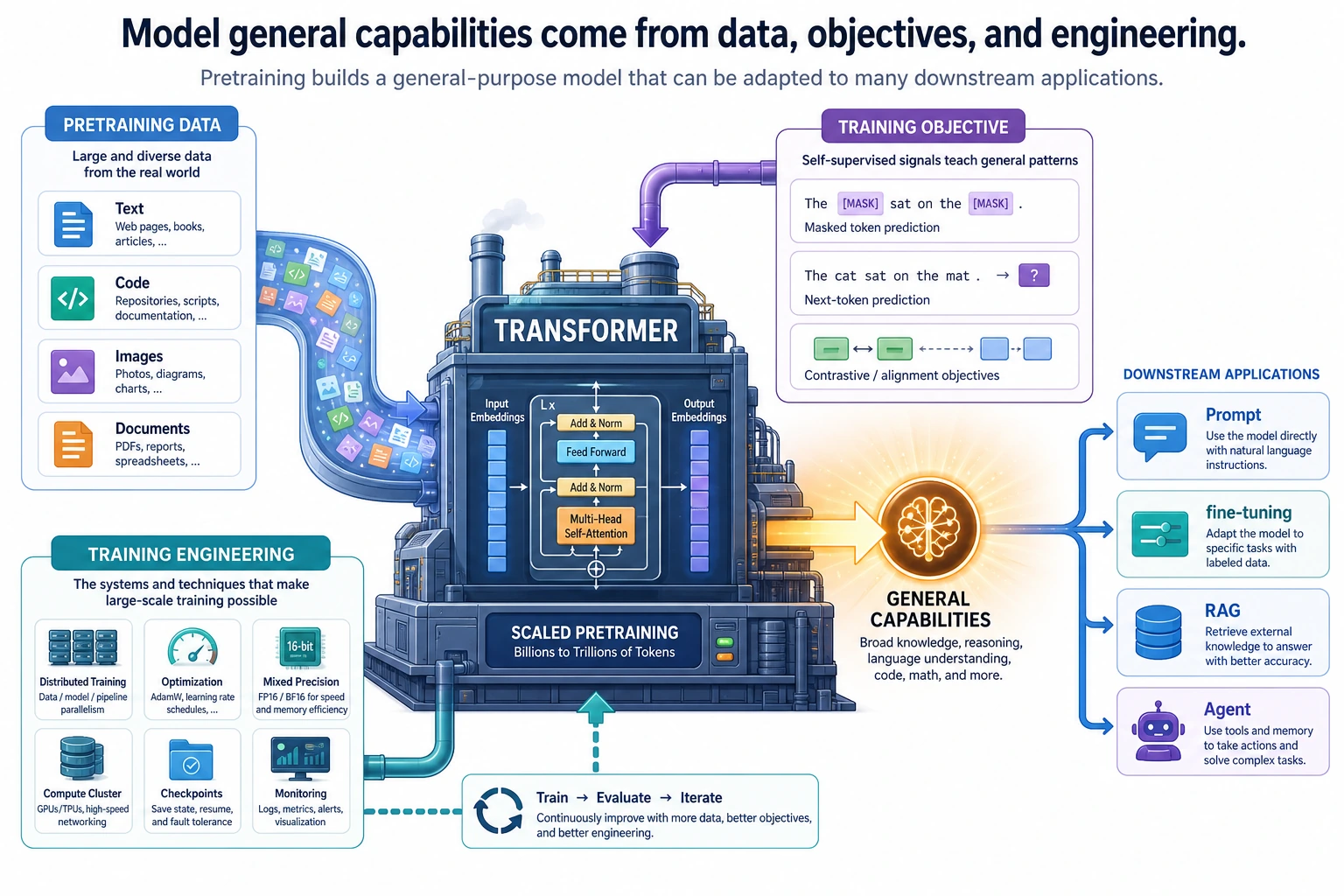
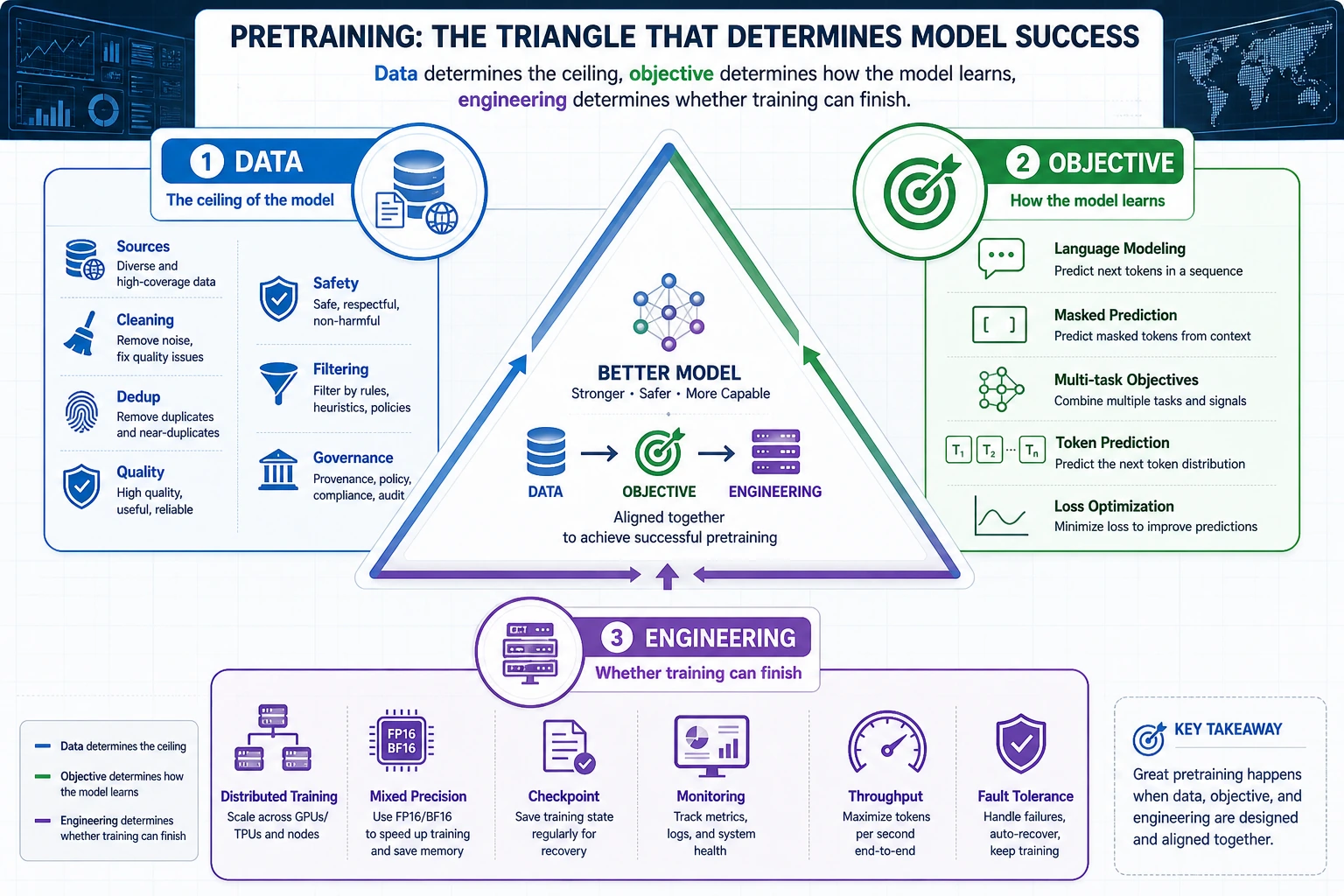
| Piece | First question |
|---|---|
| data | what text enters training and what must be filtered? |
| objective | what prediction task creates learning signal? |
| engineering | how are scale, checkpoints, logs, and failures handled? |
| evaluation | what can the model do, and where does it fail? |
Create Next-Token Pairs
tokens = ["AI", "learns", "from", "text"]
pairs = list(zip(tokens[:-1], tokens[1:]))
for source, target in pairs:
print(f"{source} -> {target}")
Expected output:
AI -> learns
learns -> from
from -> text
This tiny example is the shape of next-token prediction. Real pretraining repeats this over massive text with careful data governance.
Learn in This Order
| Order | Read | What to focus on |
|---|---|---|
| 1 | 7.4.2 Pretraining Data | sources, filtering, deduplication, contamination |
| 2 | 7.4.3 Pretraining Methods | next-token prediction, loss, scaling |
| 3 | 7.4.4 Pretraining Engineering | distributed training, checkpoints, monitoring |
Pass Check
You pass this roadmap when you can explain how data, objective, and engineering each affect the final model, and why contamination can make evaluation misleading.