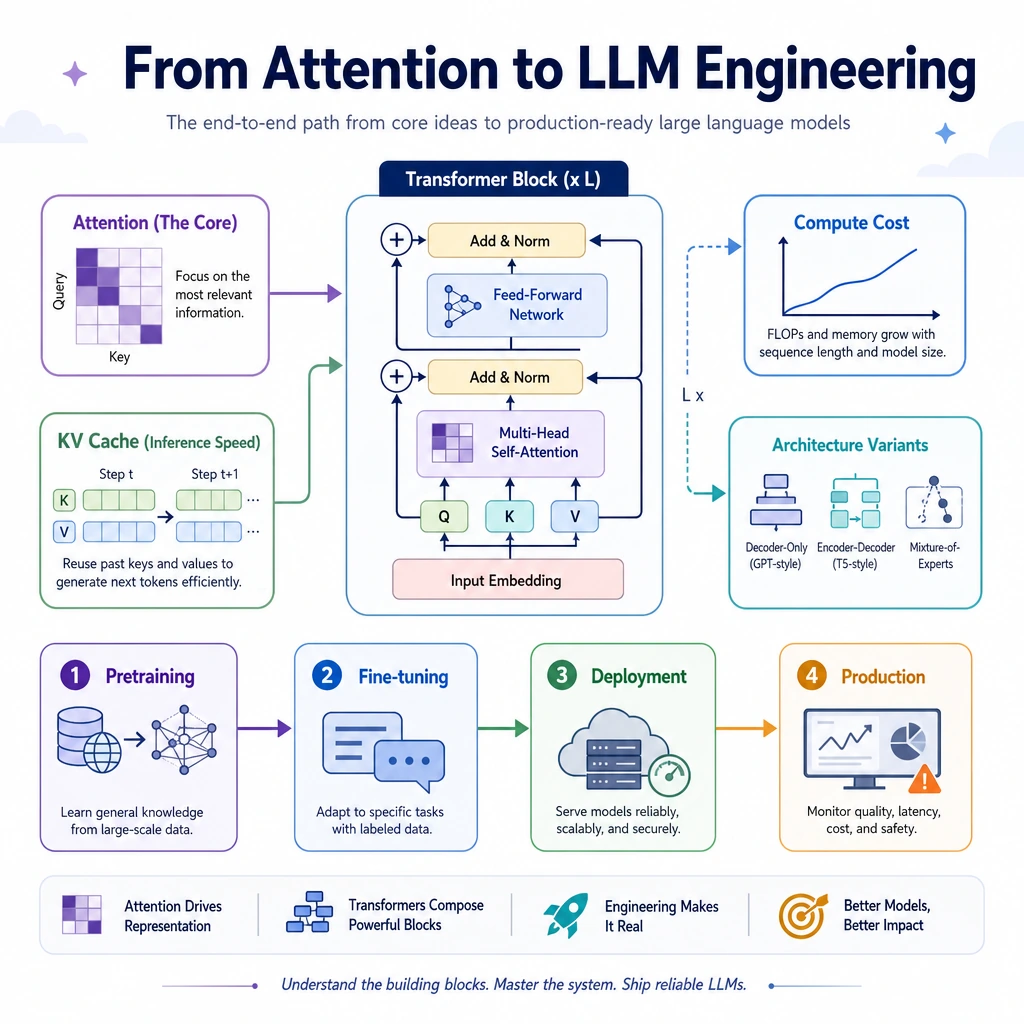
7.3.1 Transformer Deep Dive Roadmap: Blocks, Masks, Cost
This chapter looks inside the Transformer enough to debug LLM behavior and understand why context length, attention, KV cache, and model variants matter.
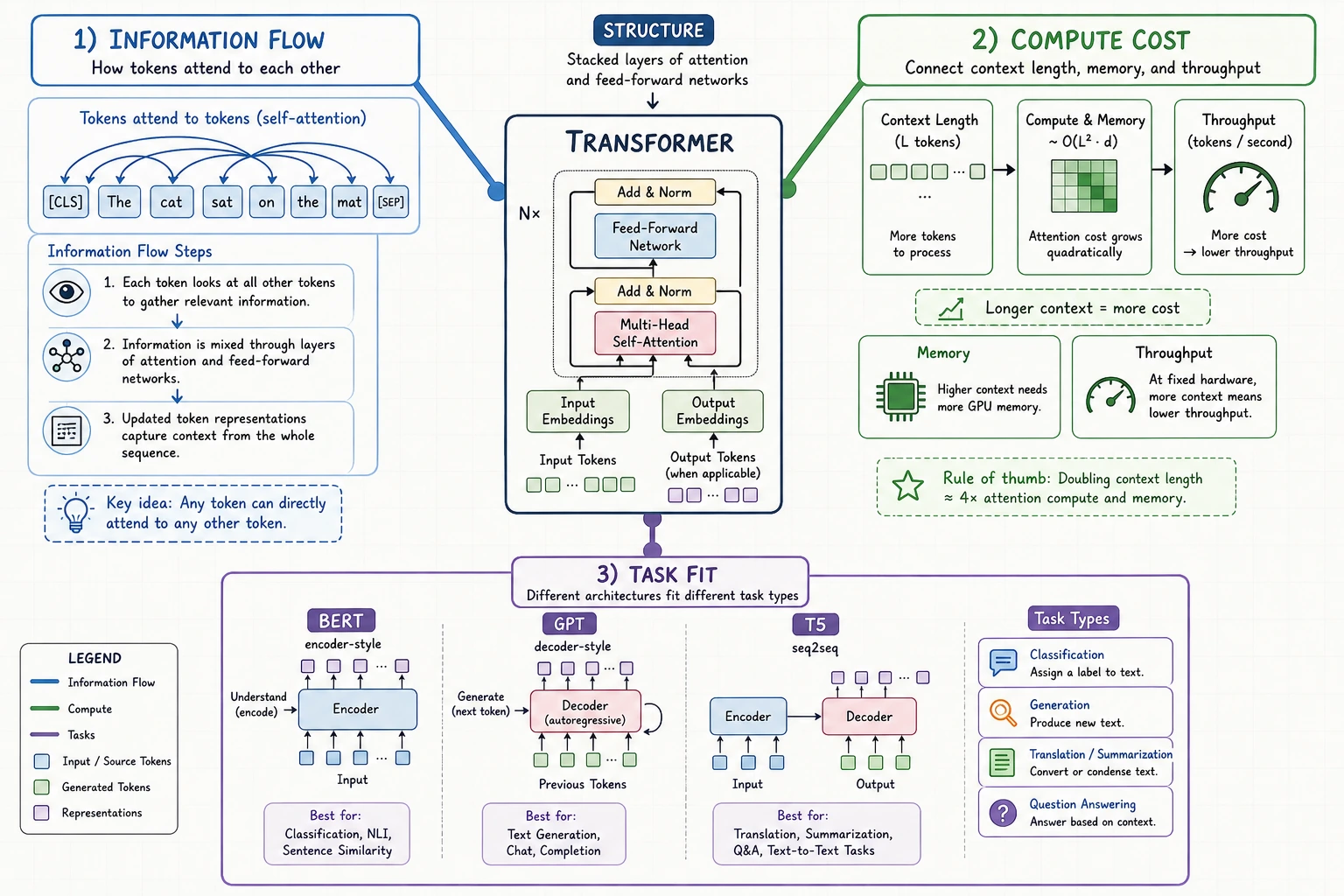
Look at the Internal Flow First
Build a Causal Mask
seq_len = 4
mask = []
for query_pos in range(seq_len):
row = []
for key_pos in range(seq_len):
row.append("allow" if key_pos <= query_pos else "block")
mask.append(row)
for row in mask:
print(row)
Expected output:
['allow', 'block', 'block', 'block']
['allow', 'allow', 'block', 'block']
['allow', 'allow', 'allow', 'block']
['allow', 'allow', 'allow', 'allow']
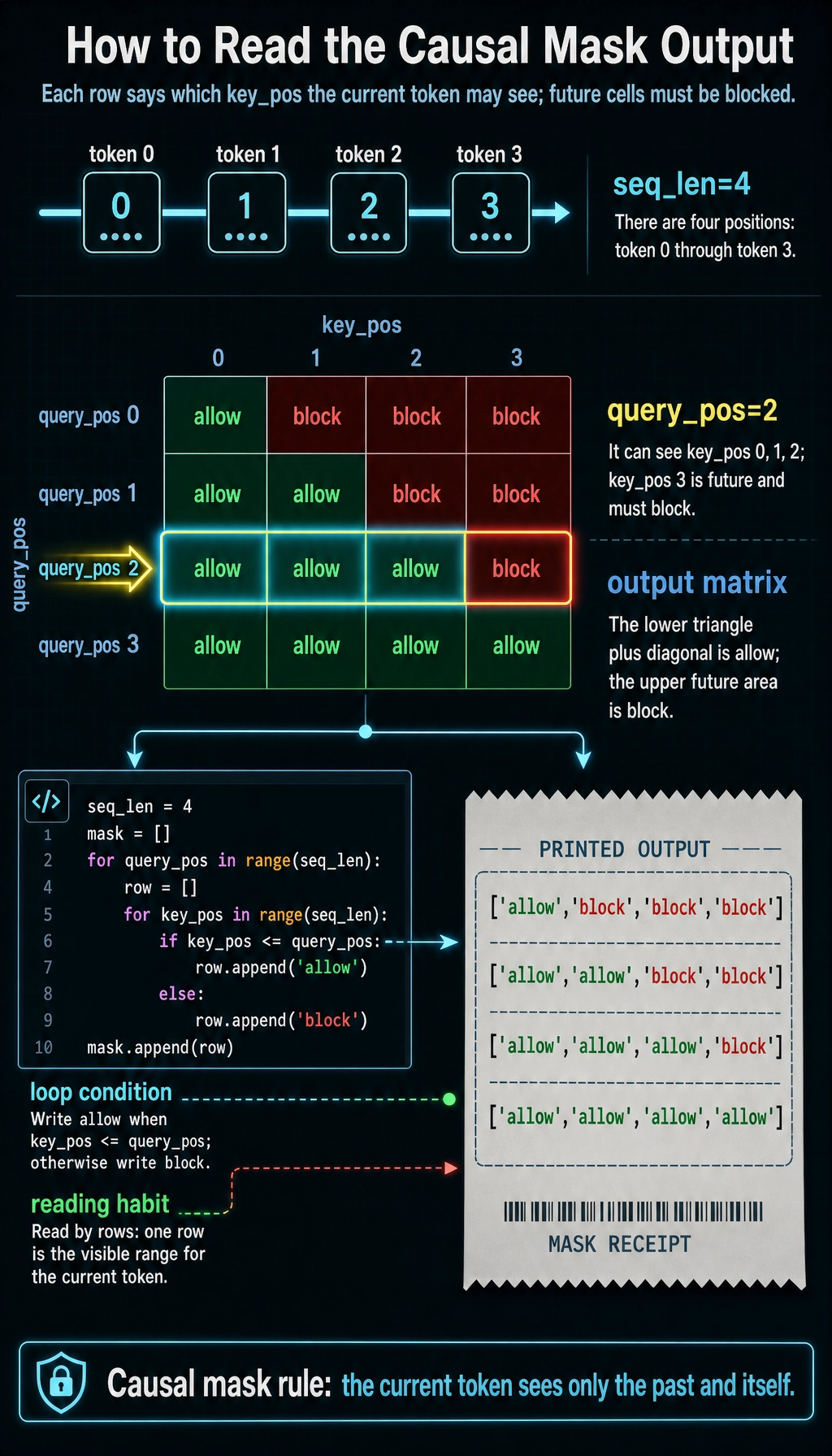
Generation uses this "no future peeking" rule: a token can attend to earlier tokens, but not future tokens.
Learn in This Order
| Order | Read | What to focus on |
|---|---|---|
| 1 | 7.3.2 Architecture Review | attention, residual, normalization |
| 2 | 7.3.3 Modern Decoder Block | decoder-only LLM block |
| 3 | 7.3.4 Model Variants | encoder, decoder, encoder-decoder |
| 4 | 7.3.5 Efficient Attention | KV cache, MQA/GQA, long context |
| 5 | 7.3.6 Scale and Computation | cost, latency, memory |
Pass Check
You pass this roadmap when you can explain why decoder-only models need a causal mask, why attention gets expensive as context grows, and why KV cache helps generation.