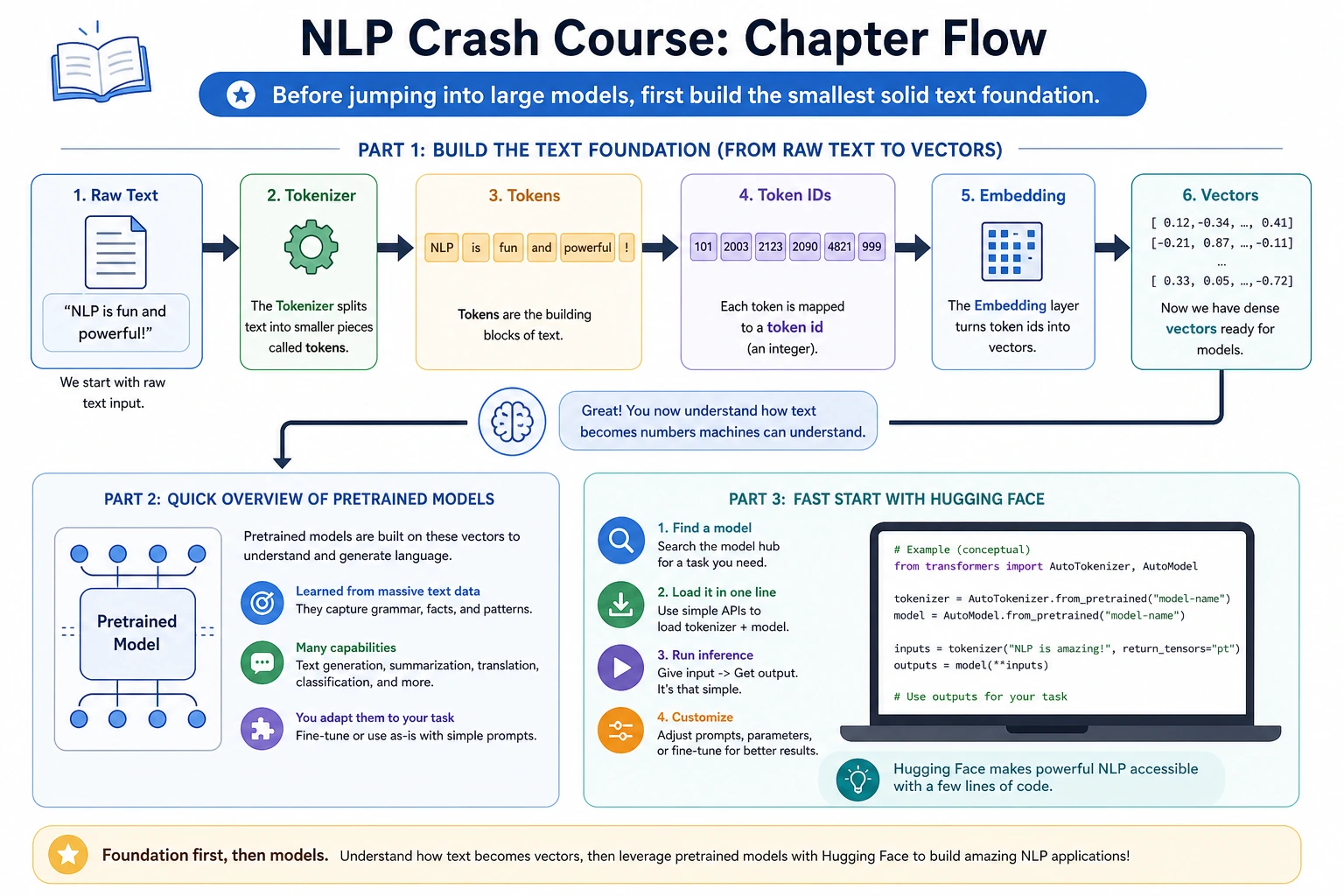
7.1.1 NLP Crash Roadmap: Text to Tokens to Vectors
Before LLMs feel understandable, first see how text becomes pieces a model can process: text -> tokens -> IDs -> vectors -> model output.
Look at the Flow First
| Word | First meaning |
|---|---|
| token | a piece of text used by the model |
| tokenizer | tool that splits text and maps pieces to IDs |
| embedding | dense vector for a token or text |
| pretrained model | model already trained on broad text |
| Hugging Face | model/dataset/tool ecosystem |
Run One Tiny Token Lab
text = "RAG retrieves evidence before answering"
tokens = text.lower().split()
vocab = {token: index for index, token in enumerate(sorted(set(tokens)))}
ids = [vocab[token] for token in tokens]
print("tokens:", tokens)
print("ids:", ids)
print("unique_tokens:", len(vocab))
Expected output:
tokens: ['rag', 'retrieves', 'evidence', 'before', 'answering']
ids: [3, 4, 2, 1, 0]
unique_tokens: 5
Real tokenizers are smarter, but this shows the main idea: text must become stable pieces and IDs before vectors and models can work.
Learn in This Order
| Order | Read | What to practice |
|---|---|---|
| 1 | 7.1.2 Tokenizer | text -> tokens -> IDs |
| 2 | 7.1.3 Embeddings | tokens/text -> vectors |
| 3 | 7.1.4 Pretrained Models | load and reuse model capability |
| 4 | 7.1.5 Hugging Face Quickstart | pipeline, model card, local run |
| 5 | 7.1.6 Tokenizer and Embedding Lab | inspect tokens and vectors |
Pass Check
You pass this roadmap when you can explain why raw text needs tokenization, why embeddings are vectors, and why pretrained models are reused instead of trained from zero.