E.A C++ and Model Deployment Roadmap
Use this elective when a Python model already works, but latency, memory, packaging, or serving cost becomes the real problem.
See the Deployment Path First
Section titled “See the Deployment Path First”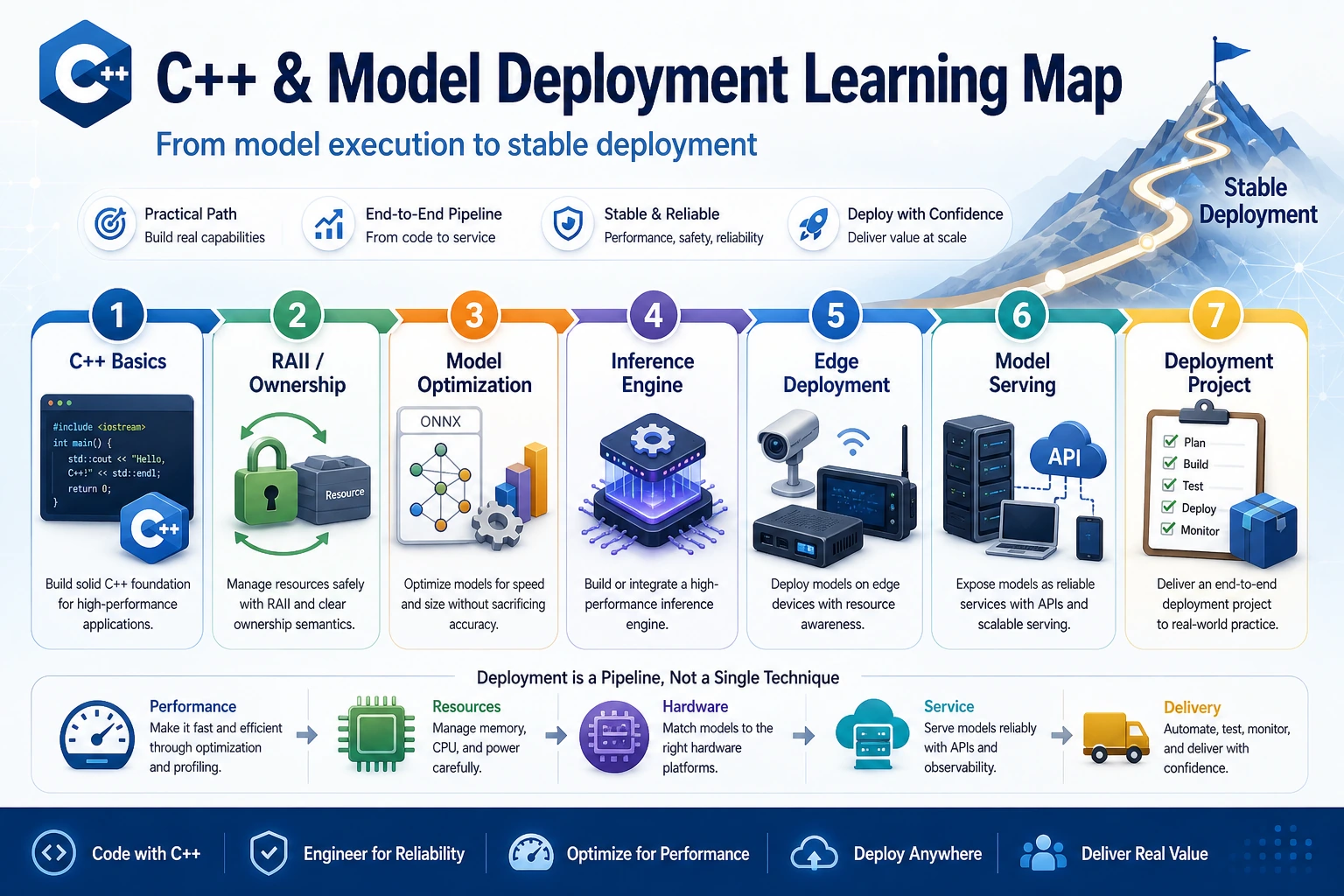
The core question is simple: can you turn model output into a fast, measurable, deployable inference path?
Run the Smallest C++ Inference Step
Section titled “Run the Smallest C++ Inference Step”Create demo.cpp:
#include <iostream>#include <vector>
int main() { std::vector<float> logits = {1.2f, 0.3f, 2.1f}; int best_index = 0;
for (int i = 1; i < static_cast<int>(logits.size()); ++i) { if (logits[i] > logits[best_index]) { best_index = i; } }
std::cout << "best_class=" << best_index << "\n"; std::cout << "score=" << logits[best_index] << "\n"; return 0;}Run it:
c++ -std=c++17 demo.cpp -o demo./demoExpected output:
best_class=2score=2.1This is the smallest deployment habit: input tensor-like values, compute a decision, print a reproducible result.
How To Use This Module In A Real Project
Section titled “How To Use This Module In A Real Project”Use the roadmap as a deployment review sequence. First prove that the same input produces the same output locally. Then ask which constraint is actually painful: build complexity, latency, memory, hardware support, service reliability, or project evidence. The right next lesson depends on that constraint.
For a portfolio project, do not present every deployment topic at once. Pick one target such as “CPU batch inference” or “edge classifier,” then keep one small before/after table. A useful table has the command, the runtime target, latency or memory, and one limitation. That is much stronger than saying “I learned deployment.”
Learn in This Order
Section titled “Learn in This Order”| Step | Lesson | Practice Output |
|---|---|---|
| 1 | E.A.1 C++ Basics | Compile and run a tiny inference helper |
| 2 | E.A.2 Advanced C++ | Explain ownership, RAII, and safe resource release |
| 3 | E.A.3 Optimization | Compare latency, memory, and accuracy trade-offs |
| 4 | E.A.4 Inference Engines | Pick an engine based on hardware and model format |
| 5 | E.A.5 Edge Deployment | Name edge constraints and export a checklist |
| 6 | E.A.6 Model Serving | Design versioned serving with metrics |
| 7 | E.A.7 Project | Deliver a small deployment evidence pack |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Deployment Target
- local inference, edge device, model server, or optimization experiment
- Artifact
- C++ snippet, benchmark, model artifact, serving config, or deployment note
- Metric
- latency, memory, throughput, model size, accuracy drop, or reliability
- Failure Check
- ABI/build issue, hardware mismatch, quantization loss, or serving bottleneck
- Expected Output
- reproducible deployment or optimization evidence, not only theory notes
Pass Check
Section titled “Pass Check”You pass this module when you can compile one C++ example, explain the deployment trade-off, record latency or memory evidence, and connect the result to the Elective Hands-on Workshop.
Check reasoning and explanation
A passing evidence pack should include one successful compile/run output, one latency or memory note, and one sentence that explains the deployment trade-off. For example: “The C++ helper returns the same class as the Python prototype, the optimized variant reduces memory, and the remaining risk is an accuracy check on real cases.”
The answer is weak if it only says “the code runs.” Deployment readiness requires a reproducible artifact plus the reason it matters for an actual target.