E.A.3 Model Optimization Techniques
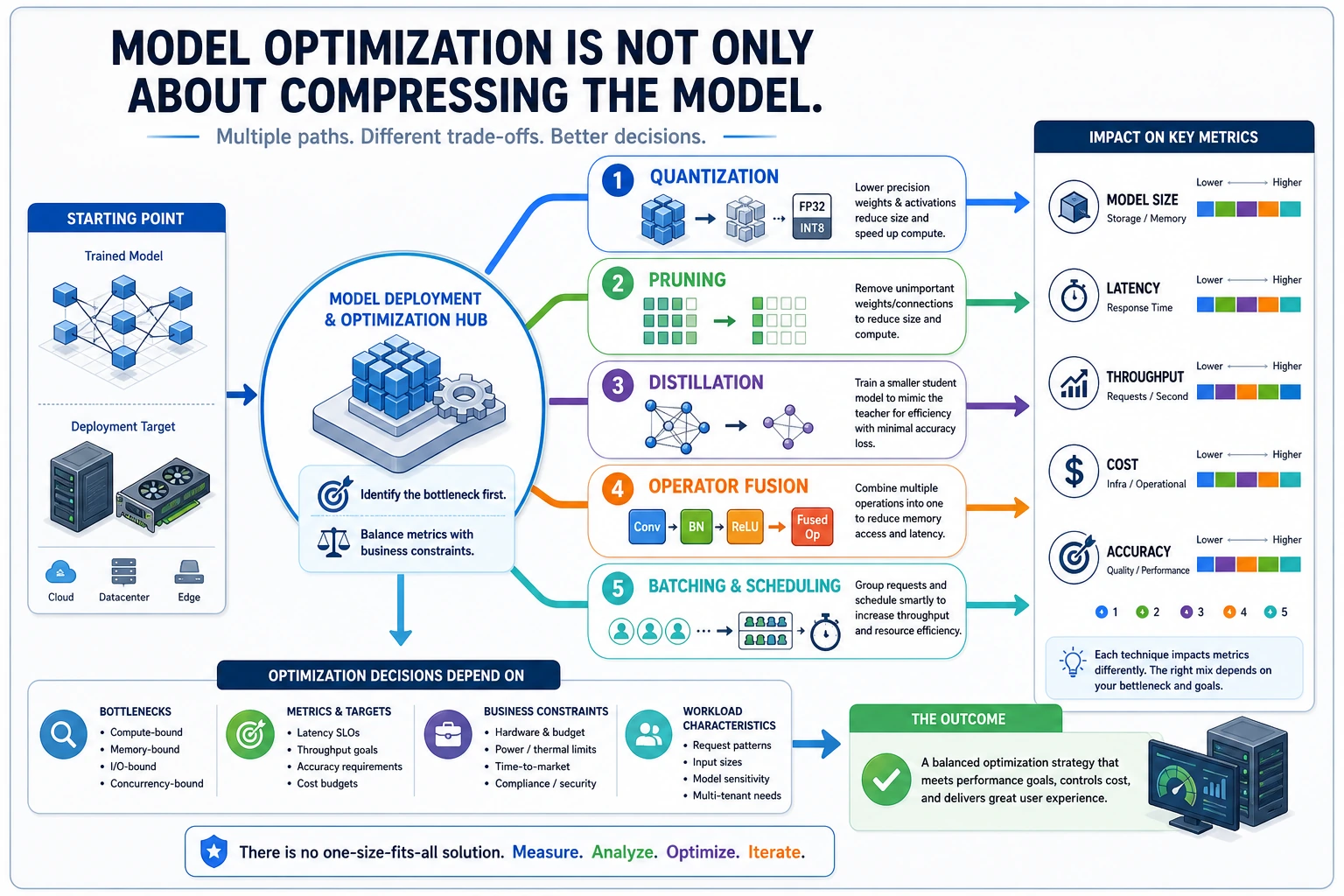
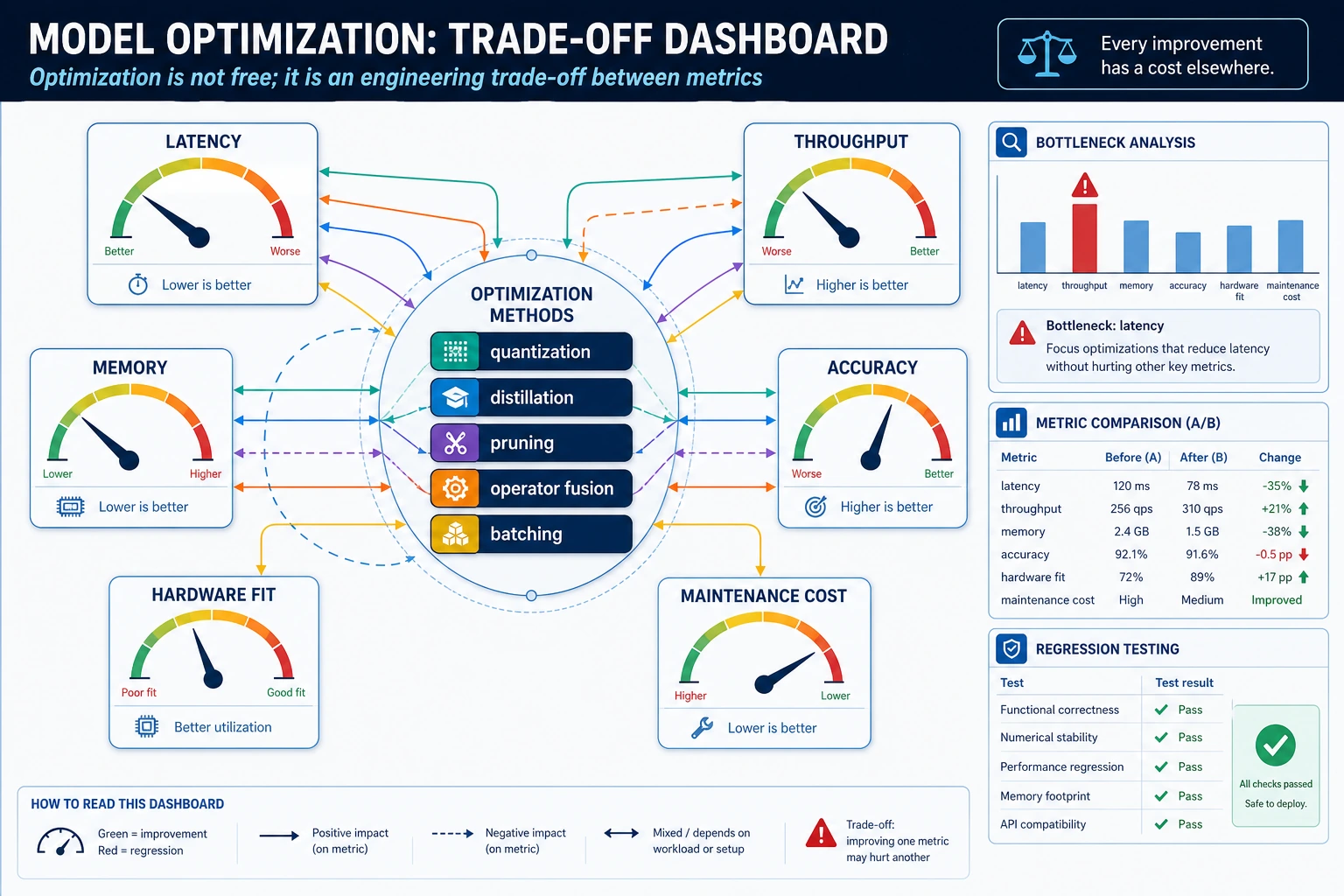
Optimization does not mean “make the model as small as possible.” It means improving one constraint while checking what you lose.
Run a tiny quantization-error check
values = [0.1234, 0.5678, 0.9012]
quantized = [round(value * 255) / 255 for value in values]
errors = [abs(original - compressed) for original, compressed in zip(values, quantized)]
print([round(value, 4) for value in quantized])
print(f"max_error={max(errors):.4f}")
Expected output:
[0.1216, 0.5686, 0.902]
max_error=0.0018
This is the smallest optimization habit: compress, measure the error, and decide whether the error is acceptable.
Choose the right optimization path
| Technique | Best when | Check before shipping |
|---|---|---|
| Quantization | Latency and memory are too high | Accuracy drop on real validation cases |
| Pruning | Many weights or channels are not useful | Whether the runtime actually speeds up |
| Distillation | A smaller model can imitate a larger one | Whether the student fails on edge cases |
| Operator fusion | Runtime overhead is high | Whether your engine supports the fused graph |
| Batching / scheduling | Many requests arrive together | Latency tail and queue delay |
Practical order
- Measure baseline latency, memory, and accuracy.
- Try one optimization at a time.
- Record before/after metrics.
- Keep failure examples.
- Only ship when the trade-off is visible.
Pass check
You pass this lesson when you can explain one optimization’s benefit, its possible cost, and the metric you would inspect before using it in a real deployment.