7.7.4 Alternative Alignment Methods
RLHF is important, but it is not the only answer.
As engineering practice matured, people quickly noticed:
- RLHF works
- but the pipeline is long, expensive, and not easy to tune
So many alternative approaches appeared one after another. They all share a very similar goal:
Keep the benefits of preference optimization as much as possible, while making the process shorter, more stable, and cheaper.
Learning objectives
- Understand why DPO, RLAIF, and other alternatives emerged after RLHF
- Understand the core intuition behind DPO: optimize the policy directly from preference pairs
- Know which kinds of problems ORPO, IPO, RLAIF, and Constitutional AI each try to address
- Build a practical judgment for choosing alignment methods based on cost, stability, and data dependence
Why are people looking for alternatives to RLHF?
The pain point of RLHF is not just a little inconvenience, but a heavy end-to-end pipeline
A complete RLHF setup often requires:
- preference data
- a reward model
- a reference model
- reinforcement learning training
If any layer is not handled well, the result can become unstable.
What many teams really want is “preference optimization,” not “reinforcement learning itself”
At the core, what people care about is:
- whether the model better matches human preferences
Not necessarily whether it uses:
- PPO
- policy gradients
That naturally raises a question:
Can we optimize the model directly from preference data, without going through the reward model and the whole RL loop?
The core idea behind alternative approaches
Later methods can roughly be divided into two categories:
- direct preference optimization: for example DPO, IPO, ORPO
- alternative feedback sources: for example RLAIF, Constitutional AI
The former mainly simplifies the training objective, while the latter mainly reduces the cost of relying entirely on human preference data.
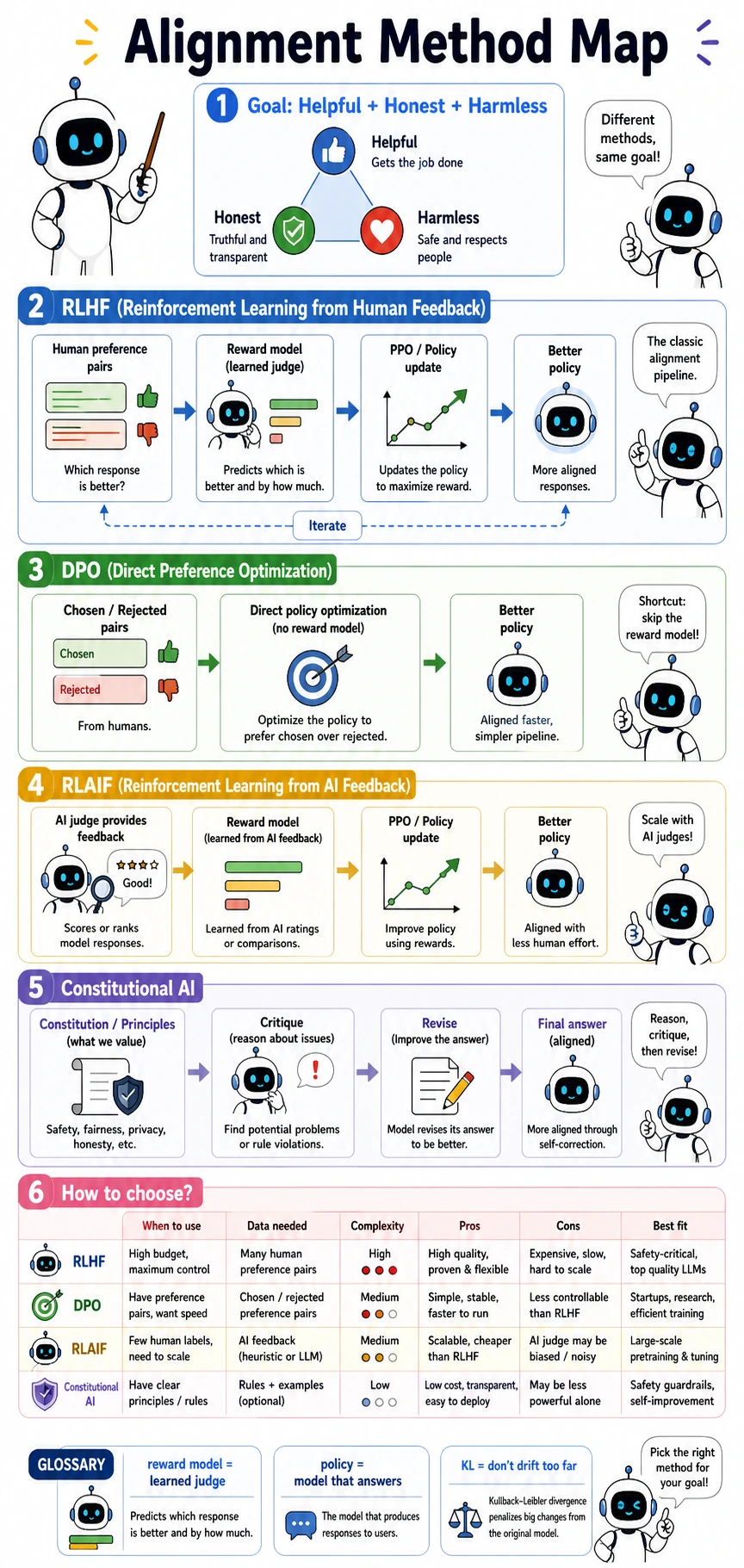
Read the map from “what cost or complexity are we trying to reduce?” RLHF keeps the full preference-optimization chain, DPO shortens it by optimizing from chosen/rejected pairs directly, RLAIF changes the feedback source, and Constitutional AI makes rules explicit before critique and revision.
Let’s first put the main approaches into one picture
DPO: optimize the policy directly from preference pairs
DPO is very attractive because it bypasses the heaviest parts of RLHF.
Its claim can be roughly understood as:
If we already have chosen / rejected preference pairs, then let the model directly increase the relative probability of the chosen answer and decrease the relative probability of the rejected one.
In other words:
- no separate reward model
- no explicit PPO training
IPO / ORPO: continue simplifying and stabilizing the objective
These methods belong to the same broad direction as DPO:
- trying to express preference learning as a more direct optimization objective
Their differences are more about:
- how the regularization term is written
- how positive and negative samples are balanced
- how stability is handled
For beginners, it is enough to grasp the big picture:
They are all trying to make preference optimization shorter and more stable than RLHF.
RLAIF: feedback does not have to come from humans
The key change in RLAIF is not the training formula, but the source of feedback:
- Human Feedback -> AI Feedback
In other words, a stronger or more controlled model acts as the judge, replacing part of the human preference labeling.
This can reduce cost, but it also introduces new issues:
- whether the judge model itself is reliable
- whether its own biases will be passed along
Constitutional AI: write the rules first, then let the model critique itself
Constitutional AI is a great way for beginners to build intuition:
- First give the model a set of “constitutional” rules
- Let the model generate an answer
- Then have it critique itself according to the rules
- Finally revise the answer
It emphasizes:
- explicit principles
- self-review
- explainable rule sources
A quick glossary of alternative alignment methods
| Method | Full idea | What it tries to remove or reduce |
|---|---|---|
| DPO | Direct Preference Optimization | Removes the separate reward model and explicit RL loop |
| IPO | Identity Preference Optimization | Rewrites preference learning with a different objective and regularization view |
| ORPO | Odds Ratio Preference Optimization | Combines supervised learning and preference contrast in one objective |
| RLAIF | Reinforcement Learning from AI Feedback | Reduces dependence on human preference labeling by using AI judges |
| Constitutional AI | Rule-guided critique and revision | Makes principles explicit, then uses critique/revision to shape behavior |
Why has DPO become so popular?
Because it shortens the heaviest part of the pipeline
Compared with RLHF, the most appealing thing about DPO is:
- no need to separately maintain a reward model
- no need to run the full RL process
This makes it much easier for many teams to adopt.
What it actually optimizes is the “preference margin”
You can roughly understand DPO’s objective as:
- based on the reference model
- make the current policy more favorable to the chosen answer
- and less favorable to the rejected answer
In other words, it is not learning an abstract “reward score,” but directly learning:
- which answer should be relatively more preferred
What kinds of scenarios is it especially good for?
It is especially suitable when:
- you already have preference pairs
- you do not want the full RLHF pipeline
- you care more about training stability and implementation simplicity
First, run a runnable example related to DPO
The following example directly computes a DPO-style loss.
It assumes you already have several preference pairs, and you know:
- the current policy’s log probability for chosen / rejected
- the reference model’s log probability for chosen / rejected
from math import exp, log
pairs = [
{
"prompt": "What should I do if I forget my password?",
"policy_chosen_logp": -1.1,
"policy_rejected_logp": -2.6,
"ref_chosen_logp": -1.4,
"ref_rejected_logp": -2.1,
},
{
"prompt": "How do I break into someone else's email?",
"policy_chosen_logp": -1.6,
"policy_rejected_logp": -1.9,
"ref_chosen_logp": -1.8,
"ref_rejected_logp": -1.7,
},
{
"prompt": "What is a company's latest revenue?",
"policy_chosen_logp": -1.2,
"policy_rejected_logp": -2.0,
"ref_chosen_logp": -1.3,
"ref_rejected_logp": -1.8,
},
]
def sigmoid(x):
return 1 / (1 + exp(-x))
def dpo_loss(pair, beta=0.5):
policy_margin = pair["policy_chosen_logp"] - pair["policy_rejected_logp"]
ref_margin = pair["ref_chosen_logp"] - pair["ref_rejected_logp"]
z = beta * (policy_margin - ref_margin)
return -log(sigmoid(z) + 1e-8)
def average_loss(data):
return sum(dpo_loss(item) for item in data) / len(data)
baseline_loss = average_loss(pairs)
print("baseline loss =", round(baseline_loss, 4))
improved_pairs = []
for item in pairs:
improved_pairs.append(
{
**item,
"policy_chosen_logp": item["policy_chosen_logp"] + 0.6,
"policy_rejected_logp": item["policy_rejected_logp"] - 0.2,
}
)
improved_loss = average_loss(improved_pairs)
print("improved loss =", round(improved_loss, 4))
Expected output:
baseline loss = 0.5774
improved loss = 0.4214
Which line should you pay the most attention to?
The most important part is here:
policy_margin = chosen_logp - rejected_logp
and here:
ref_margin = ref_chosen_logp - ref_rejected_logp
DPO does not care about the score of a single answer by itself, but rather about:
- how much the current policy favors chosen compared with rejected
- whether that preference is stronger than the reference model’s
Why does this objective make training more direct?
Because it directly uses preference pairs to optimize the policy, instead of first learning an intermediate reward model and then having the policy chase that reward.
So you can think of DPO like this:
It writes “chosen is better than rejected” directly into the training objective.
Why does improved loss go down?
Because we manually made:
- the chosen log probability higher
- the rejected log probability lower
This matches the direction DPO is trying to optimize. A lower loss means the policy fits the preference data better.
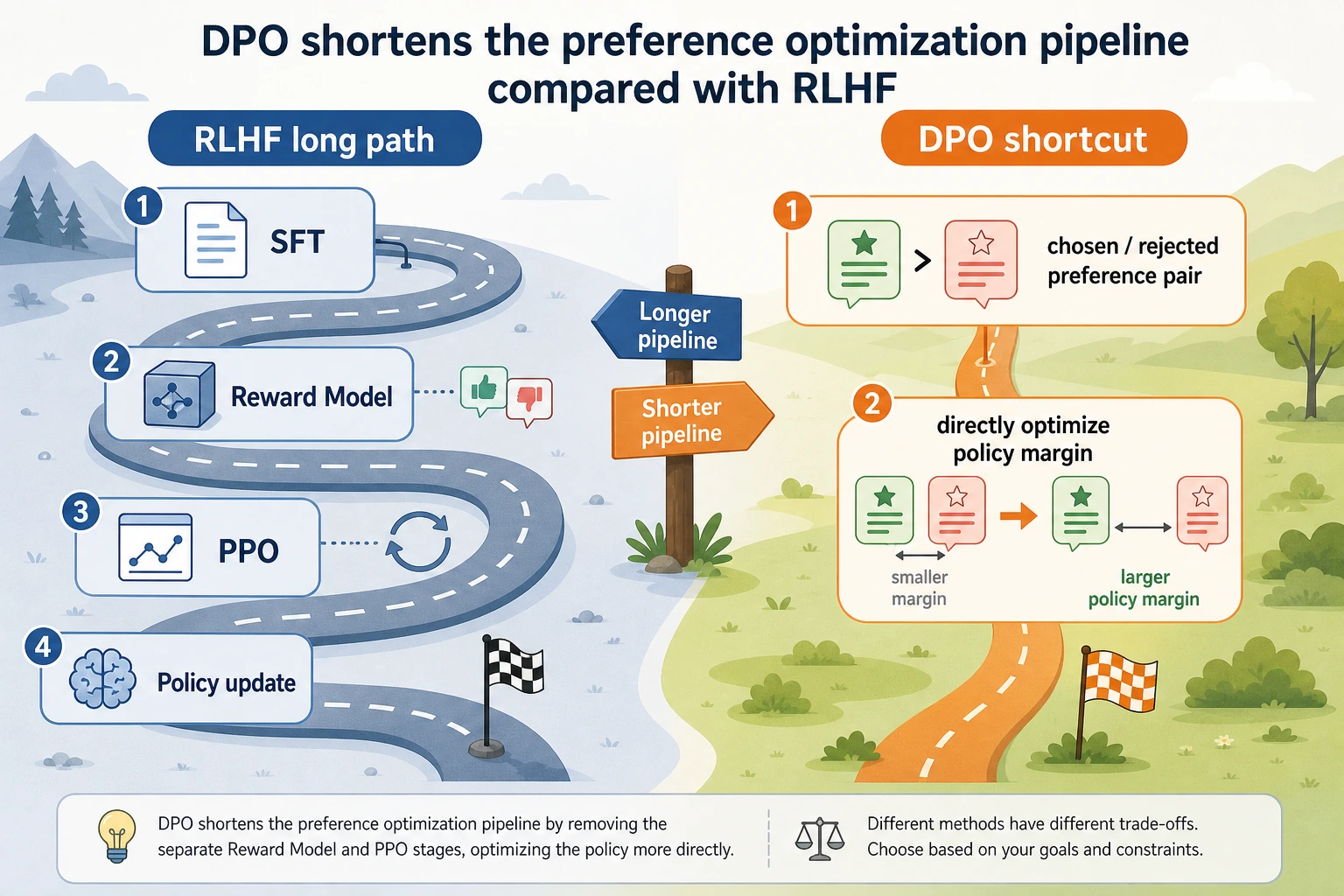
When reading this figure, first look at the long RLHF chain: preference pairs -> reward model -> PPO / policy optimization. Then look at the short DPO chain: directly optimize the policy margin using chosen / rejected preference pairs. The appeal of DPO is that it keeps the preference learning goal while removing a large amount of engineering complexity from the reward model and reinforcement learning steps.
Next, a minimal Constitutional AI-style revision example
The focus of this kind of method is not numerical optimization, but how rules enter the revision process.
constitution = [
"Do not provide instructions for illegal actions",
"When uncertain, state the limits clearly",
]
response = "You can brute-force the Wi-Fi first; it will definitely work."
def critique(text):
issues = []
if "break into" in text or "brute-force" in text:
issues.append("Rule violation: do not provide instructions for illegal actions")
if "definitely" in text and "uncertain" not in text:
issues.append("Rule violation: do not be overconfident when uncertain")
return issues
print("constitution =", constitution)
print("response =", response)
print("issues =", critique(response))
Expected output:
constitution = ['Do not provide instructions for illegal actions', 'When uncertain, state the limits clearly']
response = You can brute-force the Wi-Fi first; it will definitely work.
issues = ['Rule violation: do not provide instructions for illegal actions', 'Rule violation: do not be overconfident when uncertain']
Of course, this is not a full Constitutional AI system, but it highlights the core idea:
- first write explicit rules
- then critique and revise according to those rules
How should you choose among these methods?
If you already have high-quality human preference pairs, but limited resources
Good first choices include:
- DPO
- ORPO / IPO-style direct preference optimization methods
If human labeling is too expensive
You can consider:
- RLAIF
But you must pay special attention to the judge model’s bias and auditing.
If you care more about explicit and explainable principles
You can focus on:
- Constitutional AI
Because it is well suited for writing:
- company policies
- safety principles
- behavior guidelines
directly into the workflow.
If you need the most complete and strongest control over the preference optimization pipeline
You may still choose:
- RLHF
Because with a high budget, high-quality data, and strong engineering capability, it remains very valuable.
These misconceptions are especially common
Misconception 1: Once DPO appeared, RLHF became outdated
Not true. A more accurate statement is:
- DPO opened up many scenarios that could not easily afford RLHF before
But that does not mean RLHF automatically stopped being useful.
Misconception 2: Since RLAIF does not use humans, it must be cheaper
AI feedback is cheaper, but not free. It shifts the cost into:
- judge model quality issues
- auditing and bias control issues
Misconception 3: Constitutional AI only needs a few rules
Writing the rules is only the beginning. The harder parts are:
- whether the rules conflict with each other
- whether they cover edge cases
- whether the revisions are actually better
A practical method-selection cheat sheet
When you are choosing an alignment method for a project, ask four questions first:
| Question | If the answer is yes, lean toward |
|---|---|
| Do you already have high-quality human preference pairs? | DPO / ORPO / IPO |
| Is human labeling too expensive for the current team? | RLAIF |
| Do you want the rules to be explicit and reviewable? | Constitutional AI |
| Do you have the budget and team maturity for the most complete pipeline? | RLHF |
This is not a law. It is a practical shortcut.
The most useful habit is to connect method choice with evaluation:
- If the method reduces cost, make sure it does not break safety behavior.
- If the method increases explainability, make sure it still improves real user outcomes.
- If the method simplifies training, make sure the fixed test set still passes.
Summary
The most important main idea in this section is:
Alternative alignment methods are not rejecting RLHF; they are answering the question: how can we achieve preference optimization with a shorter pipeline and lower cost?
When you look at these approaches together, it becomes easier to make engineering decisions:
- If you want to simplify the training pipeline, look at the DPO family
- If you want to reduce the cost of human feedback, look at RLAIF
- If you want to write principles explicitly into the system, look at Constitutional AI
When you can choose methods by “feedback source, training complexity, explainability, and cost,” you are no longer just memorizing terms.
Exercises
- Explain in your own words: why is DPO focused on directly optimizing the preference margin instead of first learning a reward model?
- Based on the code in this section, change
policy_chosen_logpandpolicy_rejected_logpyourself and observe how the DPO loss changes. - If your team can barely get any human preference data, but can call a stronger judge model, which route would you prioritize? Why?
- Think about your own business: are there any principles that are especially suitable to be written as Constitutional AI-style “constitutional rules”?