5.2.5 Ensemble Learning: Forest, Boosting, Stacking
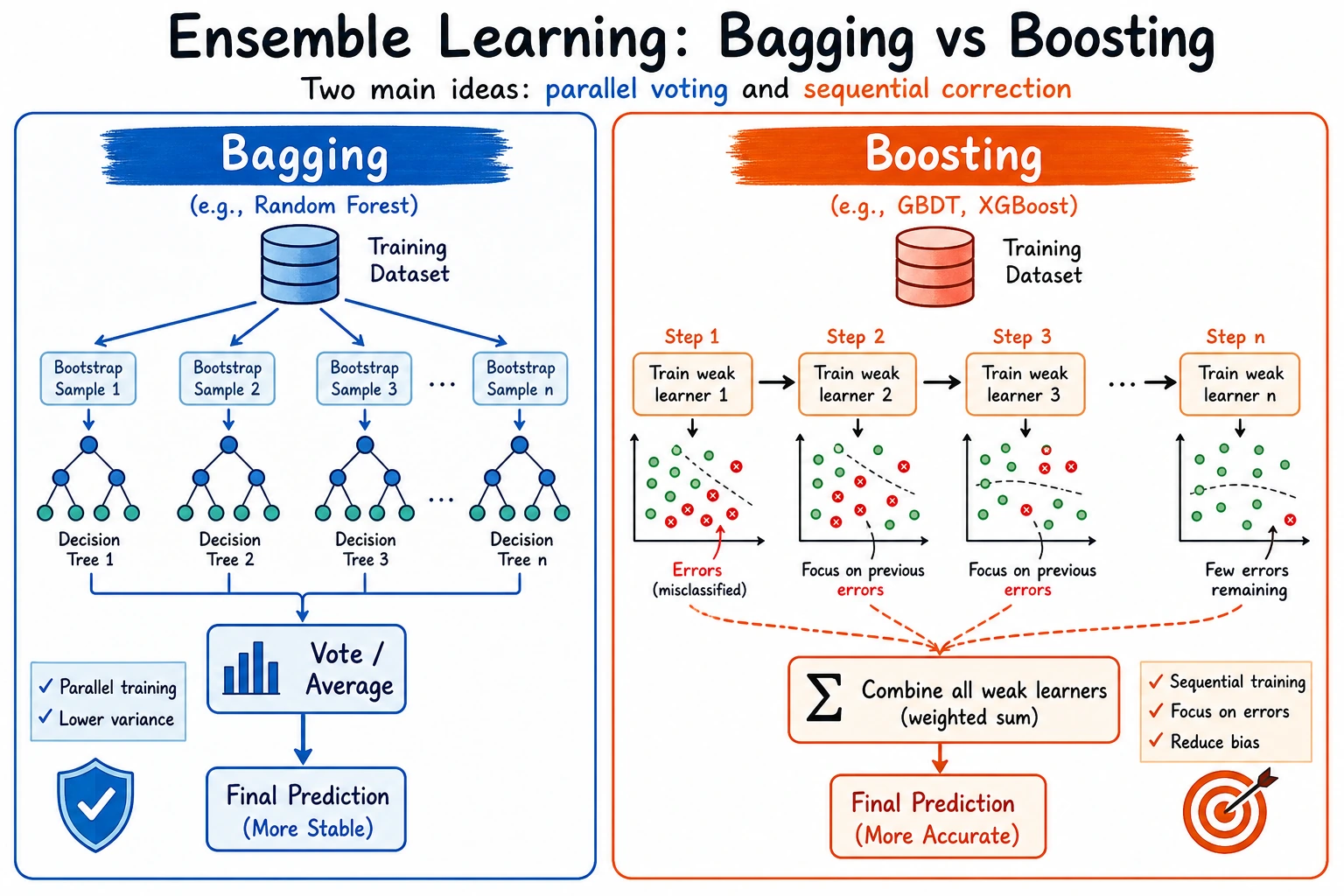
Ensemble learning combines several models so one model's weakness is less likely to dominate the final prediction. For tabular data, this is often the strongest classic ML family.
Look at the Two Main Paths
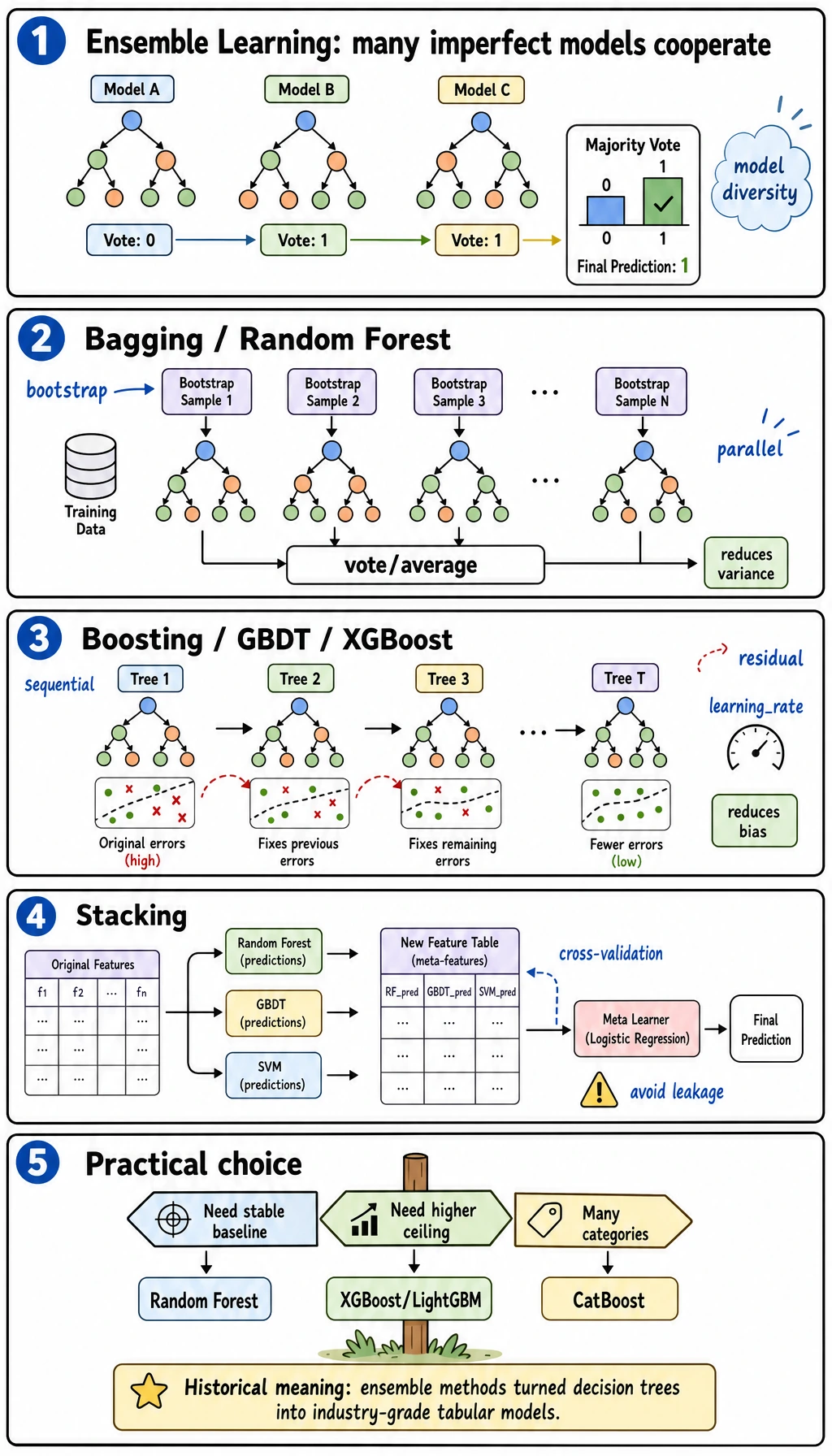
Do not memorize every model name first. Separate the two main ideas:
| Path | Visual idea | Typical model | Main benefit | Main risk |
|---|---|---|---|---|
| Bagging | many models train in parallel and vote | Random Forest | stable, less variance | can become large and less interpretable |
| Boosting | each new model focuses on previous errors | GBDT, XGBoost, LightGBM, CatBoost | strong accuracy | easier to overfit without controls |
| Stacking | base model predictions feed a meta-model | StackingClassifier | combines different model families | leakage if built without cross-validation |
Run the Comparison Lab
Create ch05_ensemble_lab.py.
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier, StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, f1_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data,
data.target,
test_size=0.25,
random_state=42,
stratify=data.target,
)
models = {
"single_tree": DecisionTreeClassifier(max_depth=4, random_state=42),
"random_forest": RandomForestClassifier(
n_estimators=200,
max_depth=6,
random_state=42,
),
"gradient_boost": GradientBoostingClassifier(
n_estimators=120,
learning_rate=0.05,
max_depth=2,
random_state=42,
),
}
models["stacking_cv"] = StackingClassifier(
estimators=[
("rf", models["random_forest"]),
("gb", models["gradient_boost"]),
("lr", make_pipeline(
StandardScaler(),
LogisticRegression(max_iter=2000, random_state=42),
)),
],
final_estimator=LogisticRegression(max_iter=2000, random_state=42),
cv=5,
)
for name, model in models.items():
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(f"{name:<15} accuracy={accuracy_score(y_test, pred):.3f} f1={f1_score(y_test, pred):.3f}")
rf = models["random_forest"]
importances = rf.feature_importances_
top = importances.argsort()[-3:][::-1]
print("top_rf_features=")
for idx in top:
print(f"- {data.feature_names[idx]}: {importances[idx]:.3f}")
Run:
python ch05_ensemble_lab.py
Expected output:
single_tree accuracy=0.944 f1=0.956
random_forest accuracy=0.958 f1=0.967
gradient_boost accuracy=0.944 f1=0.956
stacking_cv accuracy=0.986 f1=0.989
top_rf_features=
- worst perimeter: 0.146
- worst area: 0.140
- worst concave points: 0.109

Small score changes across sklearn versions are acceptable. Keep the comparison table and top features as project evidence.
Read the Result
The single tree is the baseline. Random Forest usually improves stability by averaging many different trees.
Boosting is not automatically better in every small dataset. It needs careful control of tree depth, learning rate, number of trees, and validation performance.
Stacking can win here because it combines different model families, but it must use cross-validation. Training the meta-model on predictions made on the same rows used to fit the base models leaks information.
Bagging: Random Forest
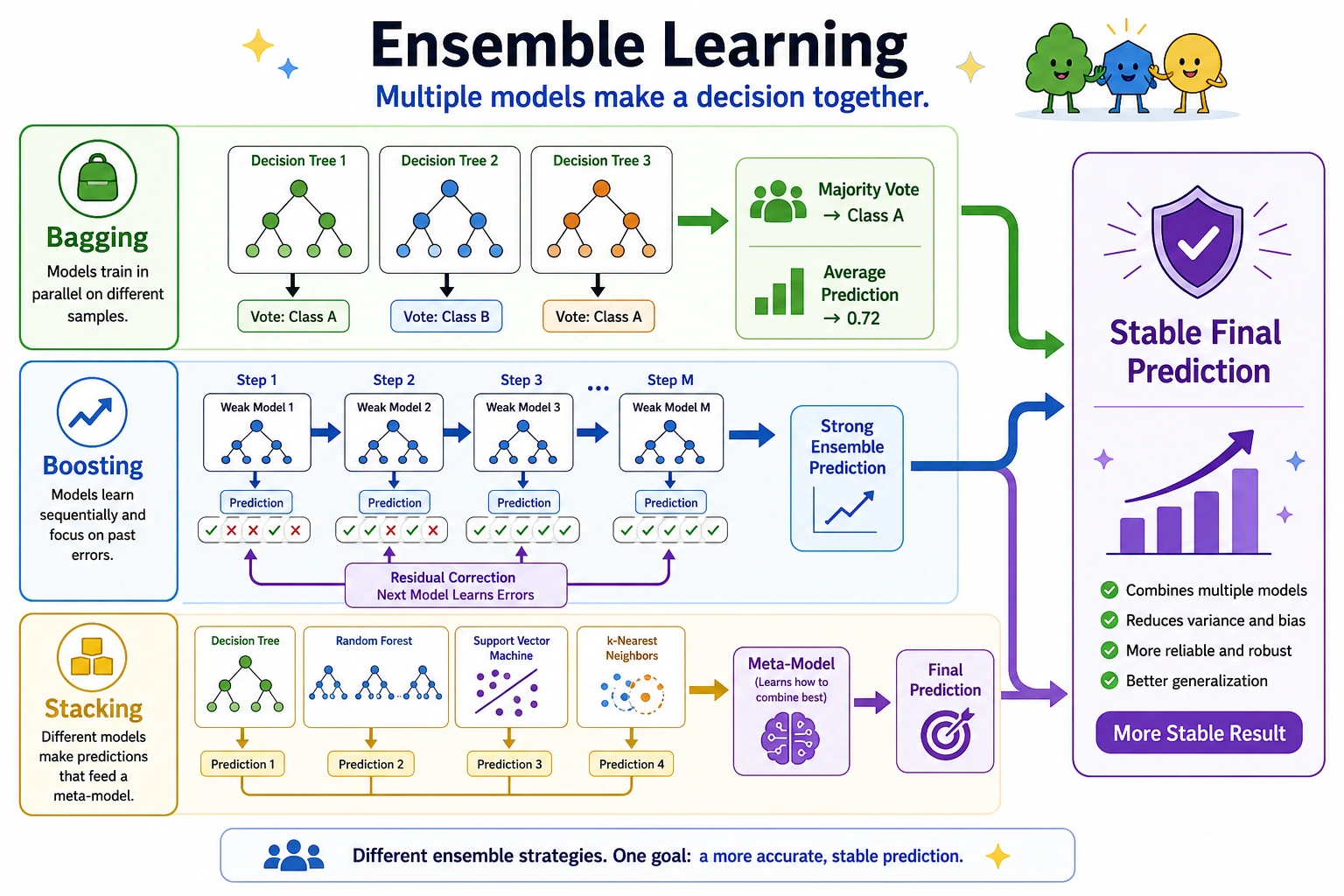
Random Forest trains many decision trees on randomized views of the data and averages/votes their predictions.
Good first settings:
| Parameter | What it controls | Beginner default |
|---|---|---|
n_estimators | number of trees | 100 to 300 |
max_depth | tree depth | start small, then increase |
min_samples_leaf | minimum samples in a leaf | increase if overfitting |
random_state | reproducibility | always set it while learning |
Boosting: GBDT and Toolkits
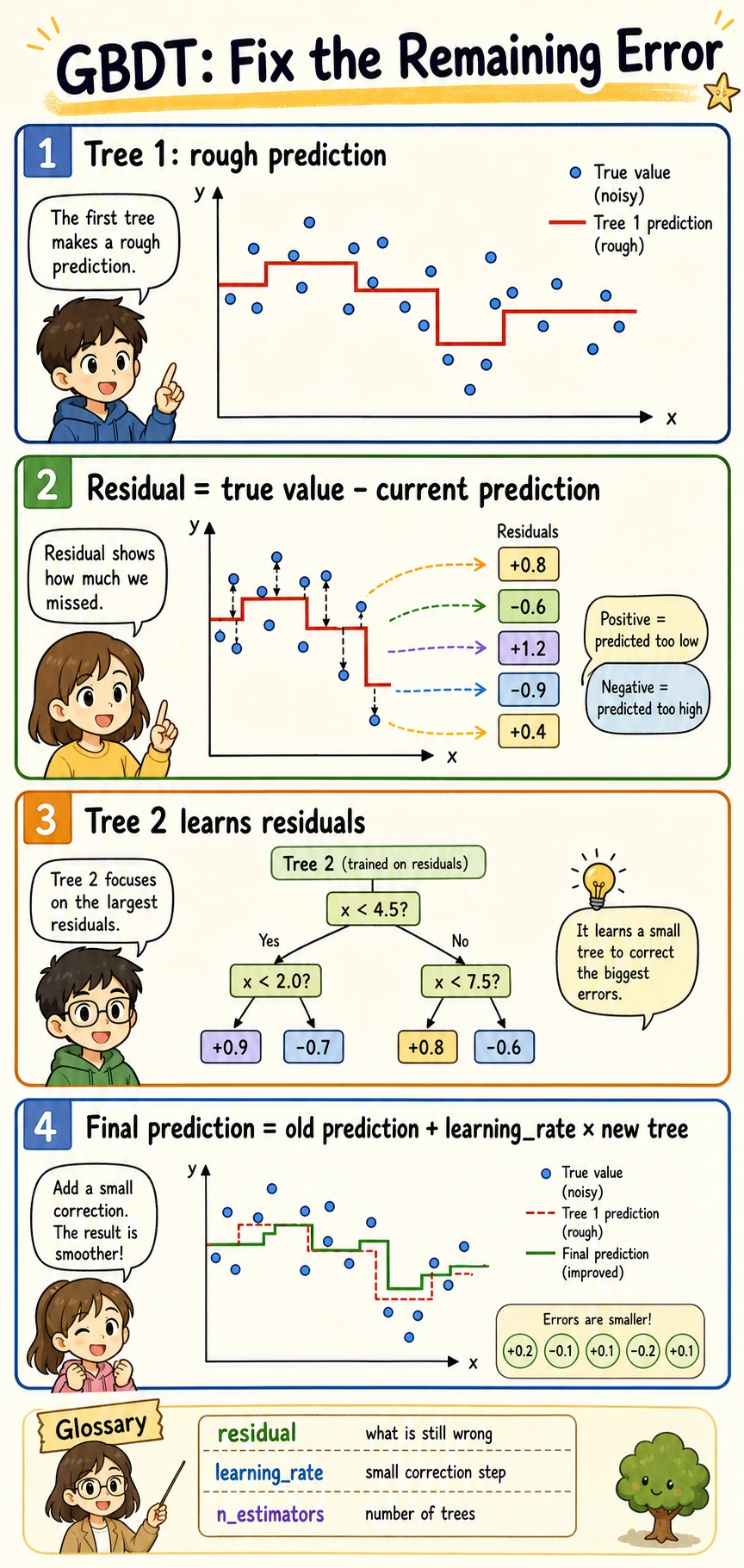
Boosting builds models in sequence:
first small tree -> find errors -> next small tree focuses on errors -> repeat
In sklearn, start with GradientBoostingClassifier or HistGradientBoostingClassifier. In real tabular projects, XGBoost, LightGBM, and CatBoost are common external libraries, but do not add them before the sklearn baseline is clear.
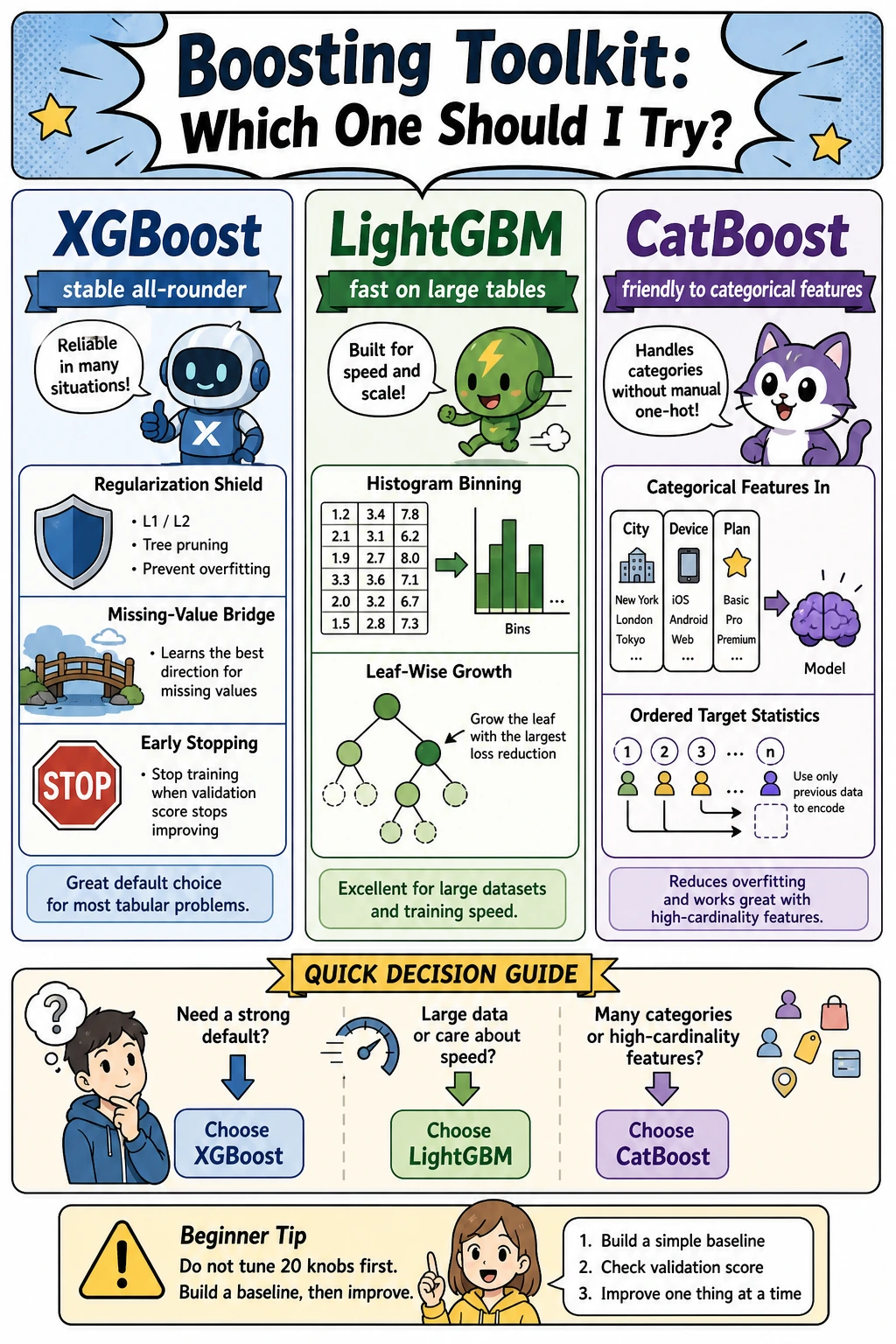
First tuning order for boosting:
| Step | Change | Why |
|---|---|---|
| 1 | learning_rate and n_estimators | controls step size and training length |
| 2 | max_depth / leaf settings | controls model complexity |
| 3 | validation or early stopping | stops overfitting |
| 4 | feature preprocessing | improves signal quality |
Stacking Safely
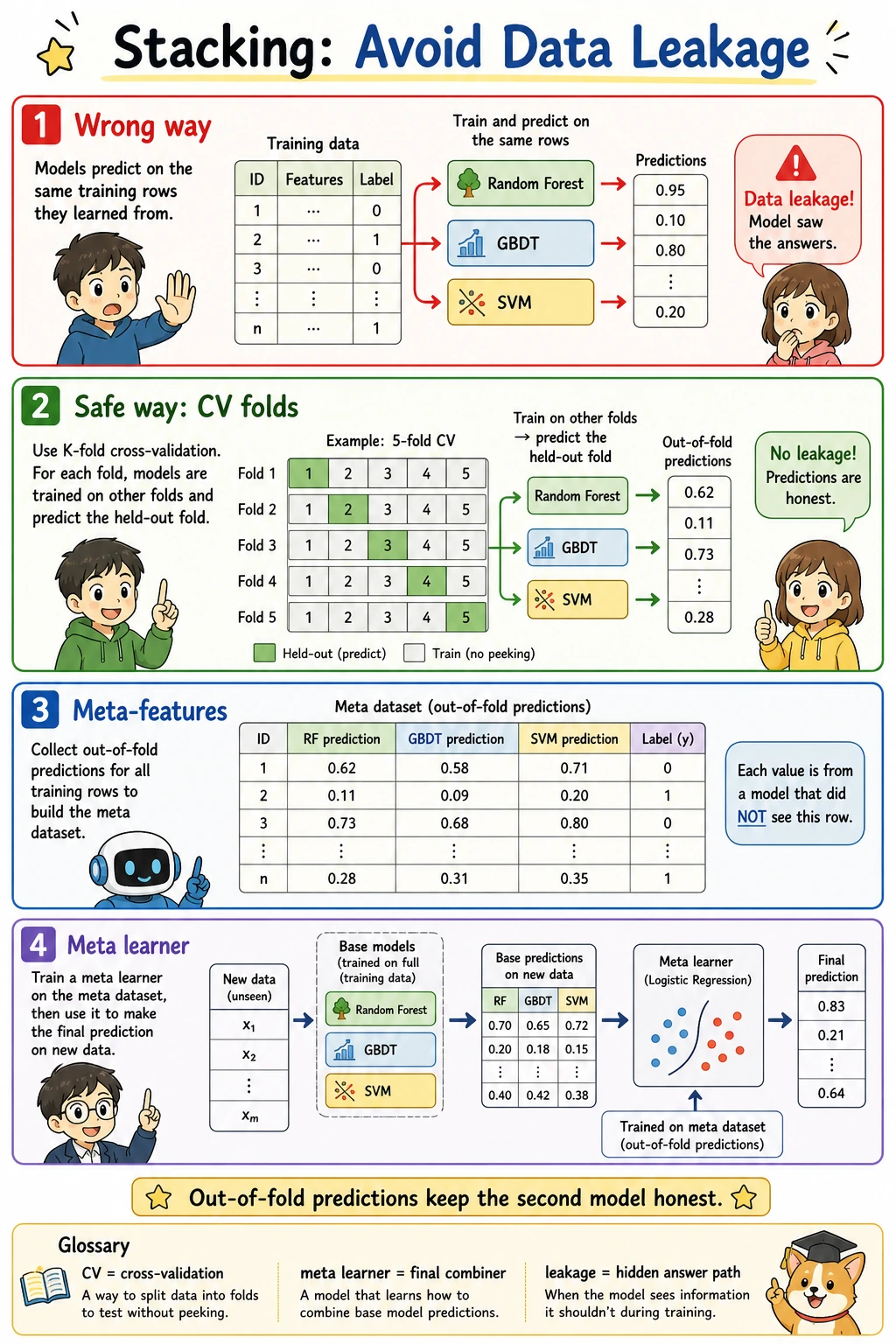
Stacking is powerful only if the meta-model sees out-of-fold predictions:
train base models in CV folds -> collect out-of-fold predictions -> train meta-model -> evaluate on holdout test
Use sklearn's StackingClassifier(cv=5) instead of manually reusing predictions from the training rows.
Choosing a Model
| Situation | Start with |
|---|---|
| need a strong, stable baseline | Random Forest |
| tabular data with many nonlinear patterns | Gradient Boosting / XGBoost / LightGBM |
| categorical-heavy tabular data | CatBoost, after baseline |
| several model families perform differently | Stacking with cross-validation |
| need easiest explanation | shallow tree or Random Forest feature importance |
Common Failures
| Symptom | First check | Usual fix |
|---|---|---|
| ensemble barely beats one tree | features are weak or split is unstable | add features, use cross-validation |
| train score high, test score low | overfitting | lower depth, increase leaf size, add validation |
| boosting gets worse as trees increase | too many rounds | reduce learning rate or use early stopping |
| stacking looks unrealistically perfect | leakage | use out-of-fold predictions or StackingClassifier(cv=...) |
| feature importance overread | correlated features | validate with permutation importance or ablation |
Practice
- Change Random Forest
max_depthfrom6to3andNone. - Change Gradient Boosting
learning_ratefrom0.05to0.2. - Remove
cv=5from your mental model and explain why stacking would leak without cross-validation. - Save a model comparison table and one paragraph explaining which model you would ship first.
Pass Check
You are ready to continue when you can explain:
- the difference between Bagging and Boosting;
- why Random Forest is usually safer than one tree;
- why Boosting needs validation control;
- why Stacking must use cross-validation;
- why the best leaderboard score is not always the best production choice.