6.7.4 Model Compression [Elective]
Model compression is a deployment trade-off, not a magic shrink button. You compress because memory, latency, throughput, or device limits force a decision.
Learning Objectives
- Explain quantization, pruning, and distillation by what they change.
- Estimate model size from parameter count and numeric precision.
- Measure quantization error in a tiny example.
- Choose a compression path from a deployment bottleneck.
- Avoid judging compression by size alone.
Start from the Deployment Bottleneck
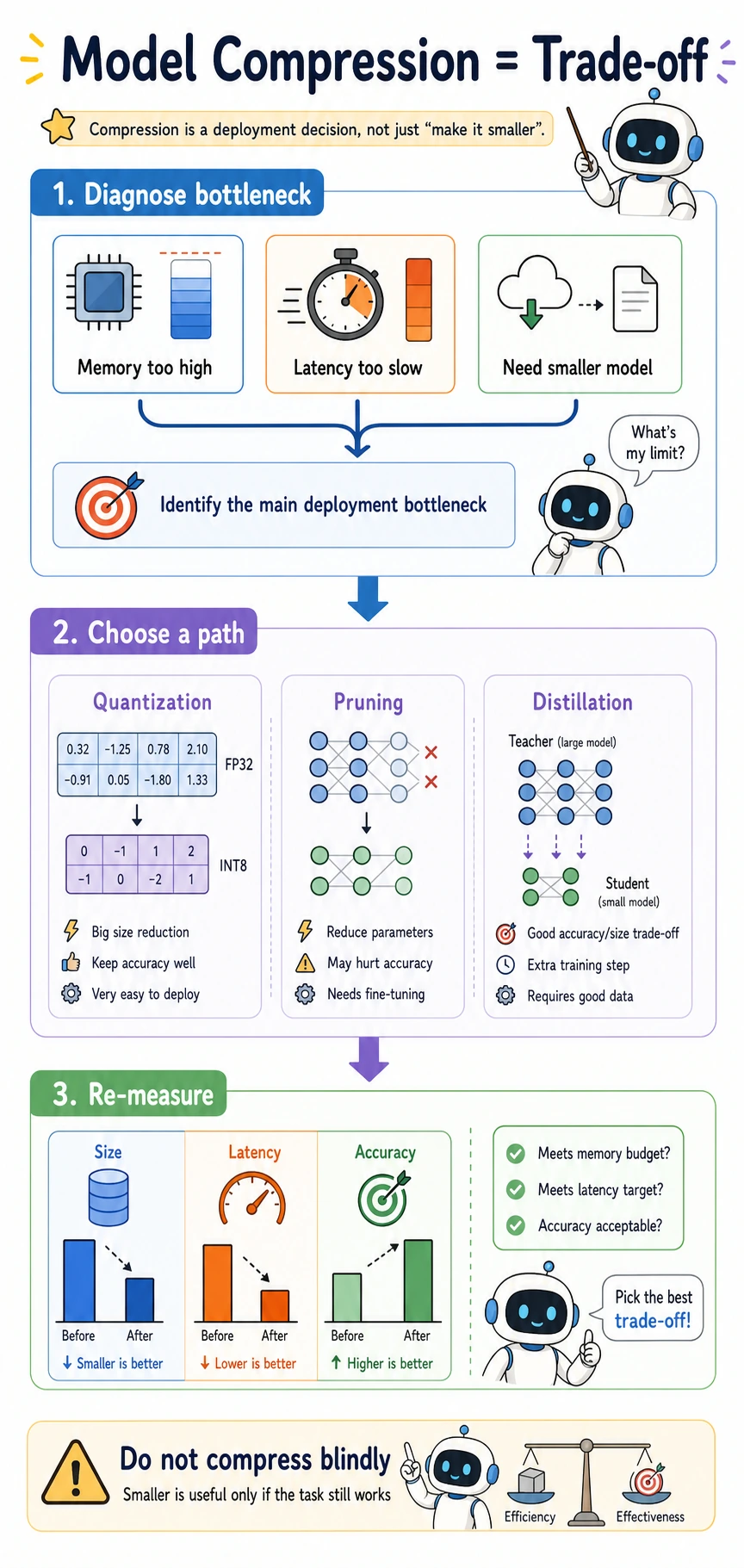
| Bottleneck | First method to consider | Why |
|---|---|---|
| memory too high | quantization | same parameter count, fewer bits per value |
| many redundant weights/channels | pruning | remove structure that contributes little |
| large teacher but retraining is possible | distillation | train a smaller student to imitate behavior |
| latency still high after compression | profiling first | bottleneck may be data transfer or unsupported kernels |
The important habit:
measure bottleneck -> choose method -> remeasure size, latency, and metric
Three Compression Paths
| Method | Changes | Typical benefit | Main risk |
|---|---|---|---|
| Quantization | numeric precision | smaller memory, sometimes faster inference | accuracy drop, hardware support issues |
| Pruning | weights, channels, or blocks | less computation if structure is actually removed | sparse speedup may not appear on all hardware |
| Distillation | training objective | smaller model with teacher-like behavior | requires retraining and teacher outputs |
Compression is not complete until the task still works after compression.
Lab 1: Quantization Error
weights = [0.12, -1.87, 3.44, -0.03]
def fake_quantize(values, scale):
return [round(v * scale) / scale for v in values]
def mae(a, b):
return sum(abs(x - y) for x, y in zip(a, b)) / len(a)
q8_like = fake_quantize(weights, scale=16)
q4_like = fake_quantize(weights, scale=4)
print("quant_error_lab")
print("original:", weights)
print("q8_like:", q8_like)
print("q4_like:", q4_like)
print("q8_mae:", round(mae(weights, q8_like), 4))
print("q4_mae:", round(mae(weights, q4_like), 4))
Expected output:
quant_error_lab
original: [0.12, -1.87, 3.44, -0.03]
q8_like: [0.125, -1.875, 3.4375, 0.0]
q4_like: [0.0, -1.75, 3.5, 0.0]
q8_mae: 0.0106
q4_mae: 0.0825
More aggressive quantization usually creates more numerical error. The practical question is whether the downstream task metric still stays acceptable.
Lab 2: Estimate Model Size
import torch
from torch import nn
model = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
)
param_count = sum(p.numel() for p in model.parameters())
print("model_size_lab")
print("params:", param_count)
for name, bits in [("fp32", 32), ("fp16", 16), ("int8", 8), ("int4", 4)]:
mb = param_count * bits / 8 / 1024 / 1024
print(f"{name:>4}: {mb:.4f} MB")
Expected output:
model_size_lab
params: 8906
fp32: 0.0340 MB
fp16: 0.0170 MB
int8: 0.0085 MB
int4: 0.0042 MB
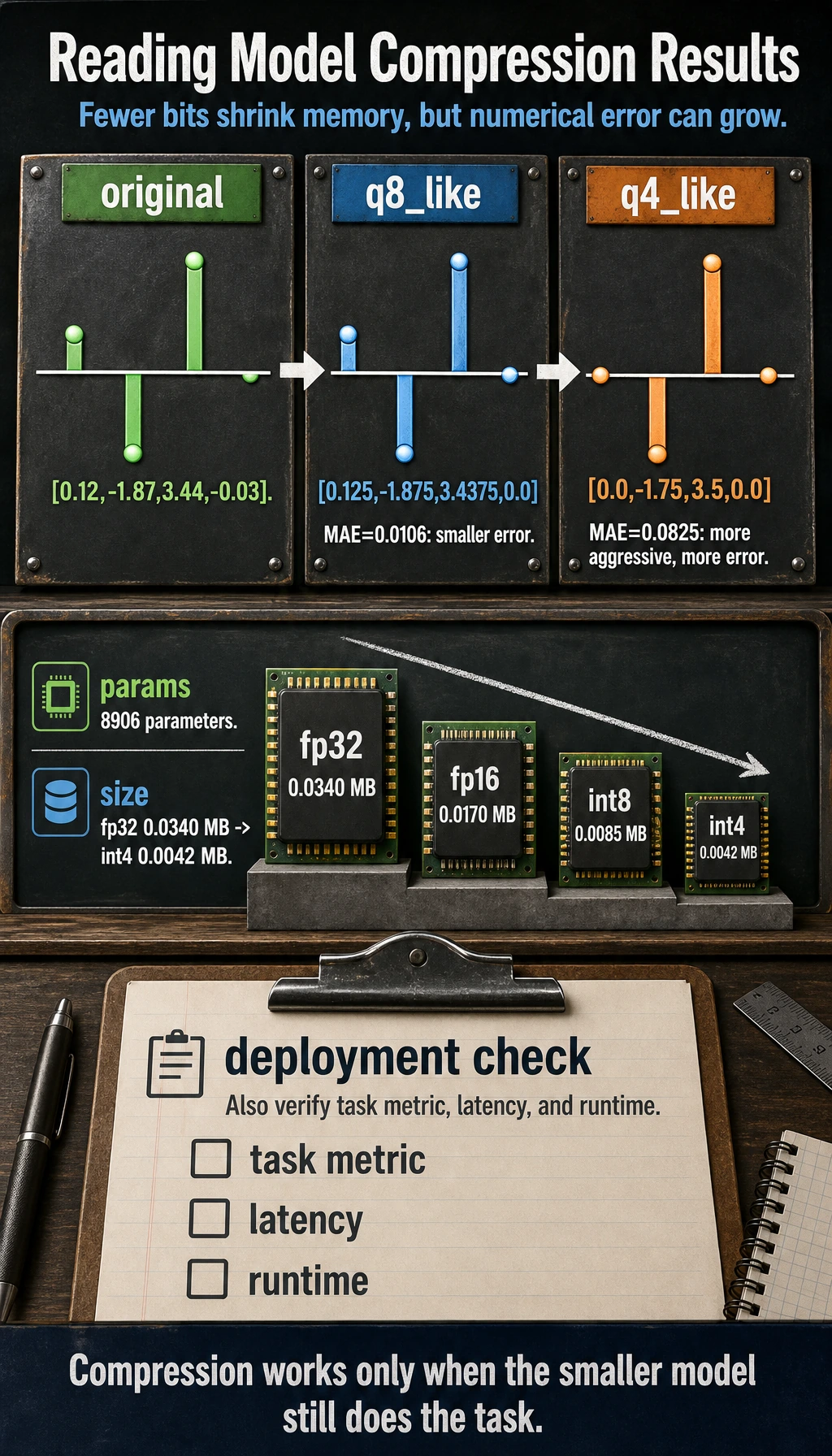
This is an estimate for parameters only. Real deployed size can also include metadata, tokenizer files, runtime overhead, and engine-specific packaging.
Choosing a Path
| Situation | Good first action |
|---|---|
| model does not fit in memory | try quantization first |
| model fits but latency is high | profile latency before pruning |
| most channels appear redundant | consider structured pruning |
| a smaller model must preserve behavior | distill from a teacher model |
| metric drops too much after compression | reduce compression strength or fine-tune |
For pruning, prefer structured pruning for deployment because removing whole channels or blocks is easier for hardware to exploit than random sparse weights.
For distillation, the common pattern is:
teacher logits or outputs -> student learns labels + teacher behavior
What to Report in a Compression Experiment
| Metric | Before | After | Why it matters |
|---|---|---|---|
| model size | required | required | did memory improve? |
| latency | required | required | did inference actually speed up? |
| throughput | useful | useful | can the service handle more requests? |
| task metric | required | required | did quality remain acceptable? |
| hardware/runtime | required | required | compression depends on deployment stack |
Never report “int8 works” without task metric and latency. Smaller is not automatically better.
Common Mistakes
| Mistake | Fix |
|---|---|
| compressing before measuring bottlenecks | measure memory, latency, and metric first |
| assuming quantization always speeds things up | verify hardware and runtime support |
| counting only parameter size | include tokenizer, runtime, and packaging where relevant |
| using unstructured pruning and expecting automatic speedup | benchmark on target hardware |
| ignoring accuracy after compression | compare task metric before and after |
Exercises
- Change
scale=16toscale=32in Lab 1. Does MAE decrease? - Add a third Linear layer to Lab 2 and recompute model size.
- Choose a compression strategy for a model that fits in memory but is too slow.
- Write a before/after report template with size, latency, throughput, and metric.
- Explain why structured pruning is usually easier to deploy than unstructured pruning.
Key Takeaways
- Compression starts from deployment constraints.
- Quantization changes numeric precision.
- Pruning changes model structure.
- Distillation changes the training process.
- Compression is successful only if the deployed task still meets quality and latency requirements.