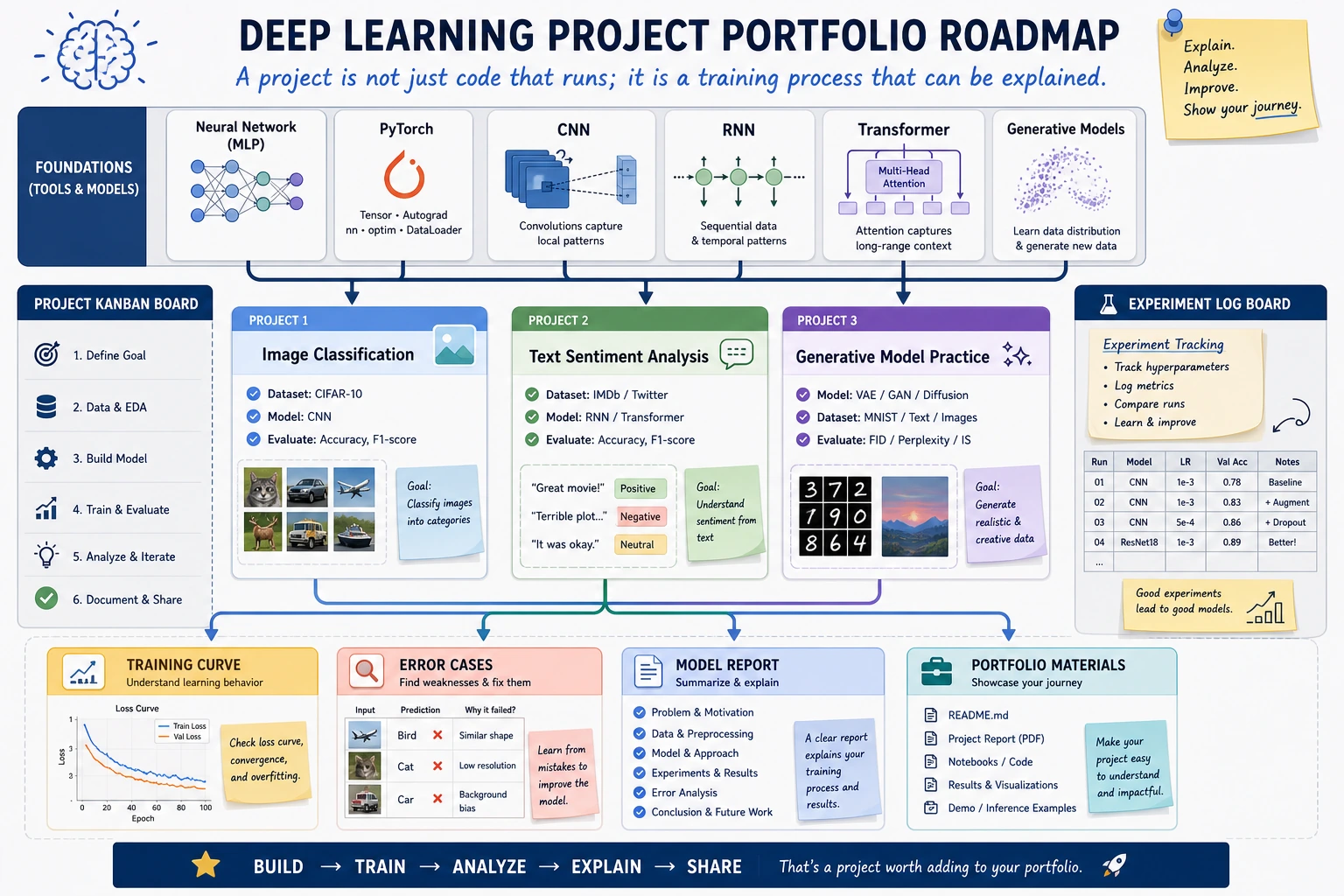
6.8.1 Deep Learning Projects Roadmap: Train, Inspect, Package
This chapter is the exit point of Chapter 6. A deep learning project is not just a training script. It needs data evidence, shape checks, loss logs, prediction samples, failure cases, and a README.
Look at the Project Loop First
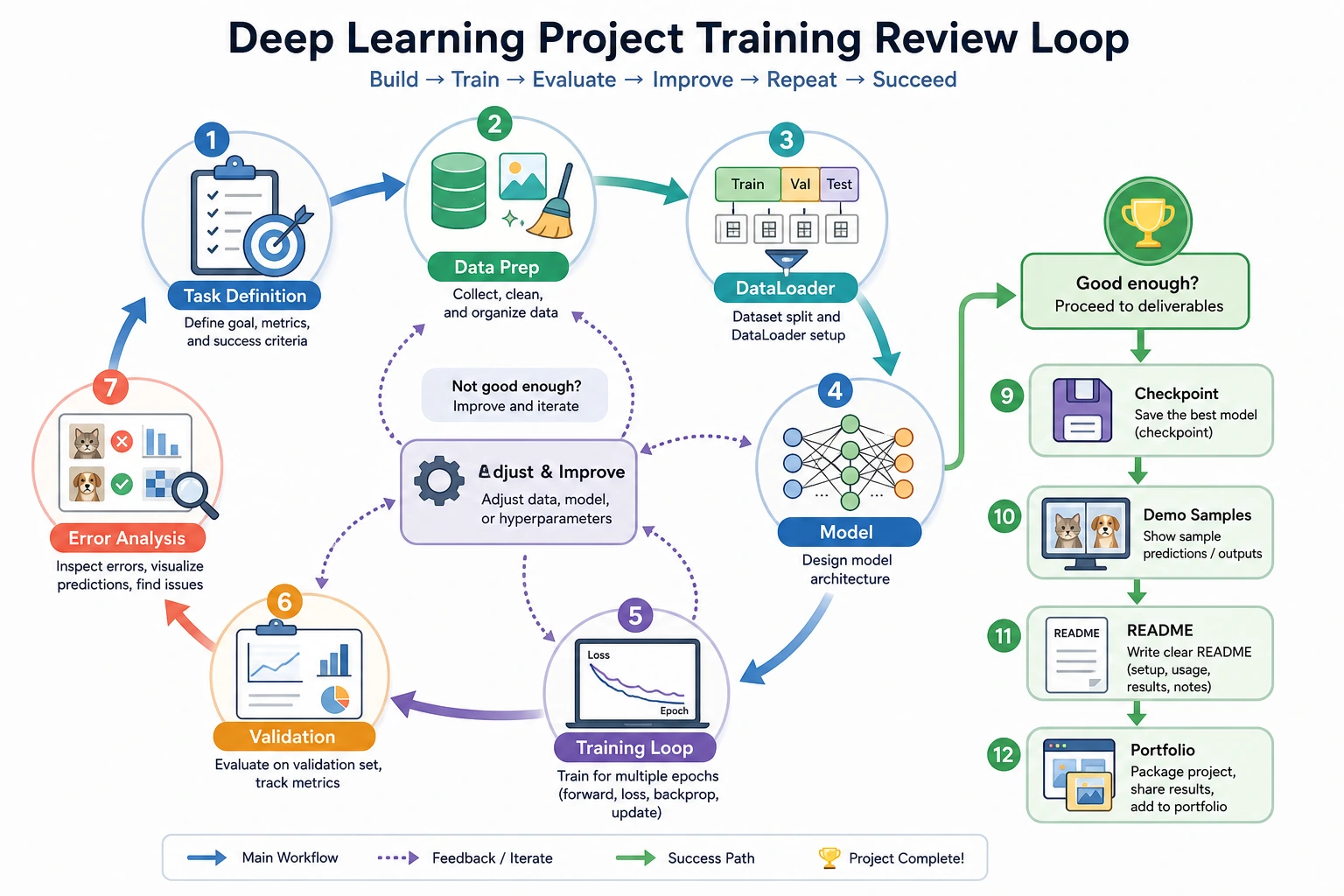
dataset -> model -> training log -> evaluation -> failure cases -> package
Keep One Evidence Record
Create dl_project_evidence_first_loop.py.
evidence = {
"task": "image classification",
"baseline_accuracy": 0.71,
"current_accuracy": 0.82,
"failure_case_count": 5,
"next_step": "inspect confused classes and add augmentation",
}
print("task:", evidence["task"])
print("improvement:", round(evidence["current_accuracy"] - evidence["baseline_accuracy"], 3))
print("failure_case_count:", evidence["failure_case_count"])
print("next_step:", evidence["next_step"])
Expected output:
task: image classification
improvement: 0.11
failure_case_count: 5
next_step: inspect confused classes and add augmentation
This is the project habit: every improvement needs a baseline, metric, failure evidence, and next step.
Learn in This Order
| Order | Read | What to deliver |
|---|---|---|
| 1 | 6.8.2 Image Classification | dataset, CNN/transfer baseline, prediction samples |
| 2 | 6.8.3 Sentiment Analysis | text pipeline, training log, error examples |
| 3 | 6.8.4 Generative Practice | generated samples and review notes |
| 4 | 6.8.5 Hands-on DL Workshop | one reproducible PyTorch evidence pack |
Project Deliverable Standards
Keep at least these files for one project: README.md, run command, dataset note, model summary, loss curve or log, metric table, prediction samples, failure cases, and next-step plan.
Pass Check
You pass this roadmap when another learner can run your project, inspect the training evidence, see both success and failure samples, and understand what you would improve next.