6.5.1 Transformer Roadmap: Attention Lets Tokens Look at Each Other
Transformer is the bridge from deep learning to modern LLMs. Its first idea is simple: each token can decide which other tokens matter.
Look at the Attention Flow First
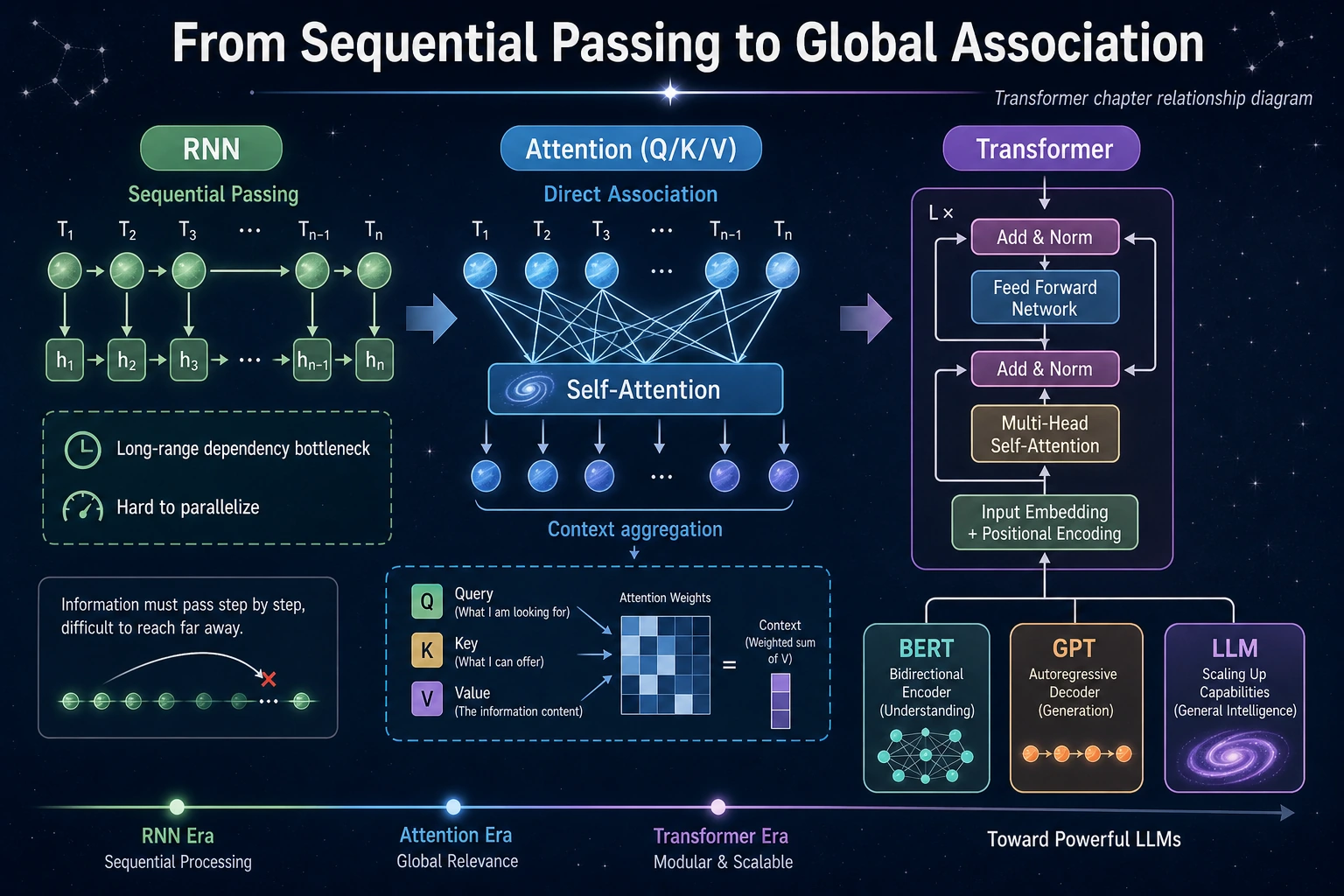
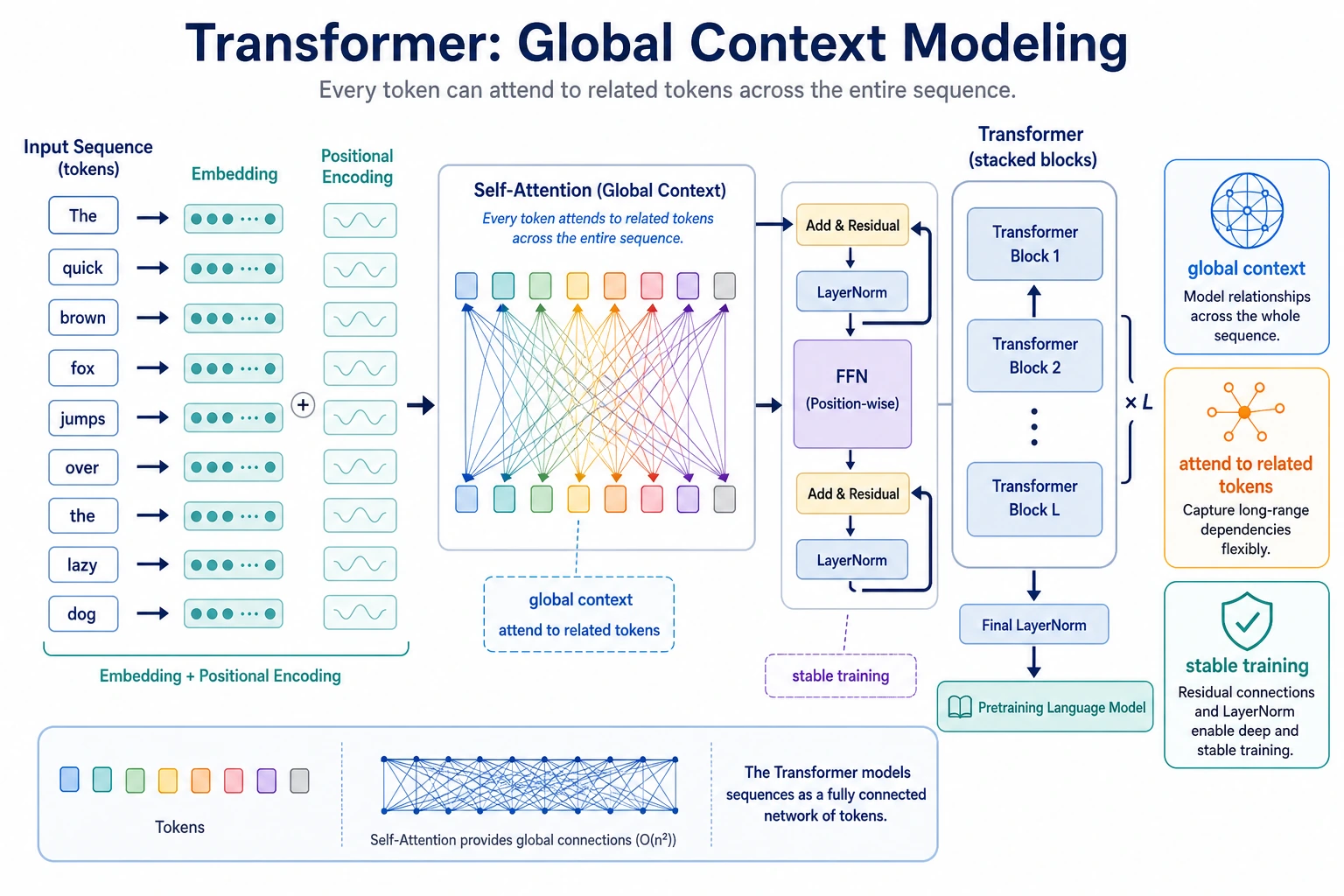
| Concept | First meaning |
|---|---|
| token | one position in the sequence |
| Q / K / V | query, key, value views of tokens |
| attention weight | how much one token looks at another |
| block | attention plus feed-forward refinement |
| mask | prevent seeing future tokens in generation |
Run One Attention Shape Check
Create transformer_first_loop.py and run it after installing torch.
import torch
attention = torch.nn.MultiheadAttention(embed_dim=8, num_heads=2, batch_first=True)
tokens = torch.randn(1, 4, 8)
output, weights = attention(tokens, tokens, tokens)
print("tokens_shape:", tuple(tokens.shape))
print("output_shape:", tuple(output.shape))
print("attention_shape:", tuple(weights.shape))
Expected output:
tokens_shape: (1, 4, 8)
output_shape: (1, 4, 8)
attention_shape: (1, 4, 4)
attention_shape is [batch, query_position, key_position]: each of 4 positions can look at 4 positions.
Learn in This Order
| Order | Read | What to focus on |
|---|---|---|
| 1 | 6.5.2 Attention Mechanism | QKV, attention weights, masking |
| 2 | 6.5.3 Transformer Architecture | block structure, residuals, feed-forward layers |
Pass Check
You pass this roadmap when you can read the attention weight shape, explain why attention gives global context, and connect masks to text generation.