7.2.3 Core Concepts of Large Models
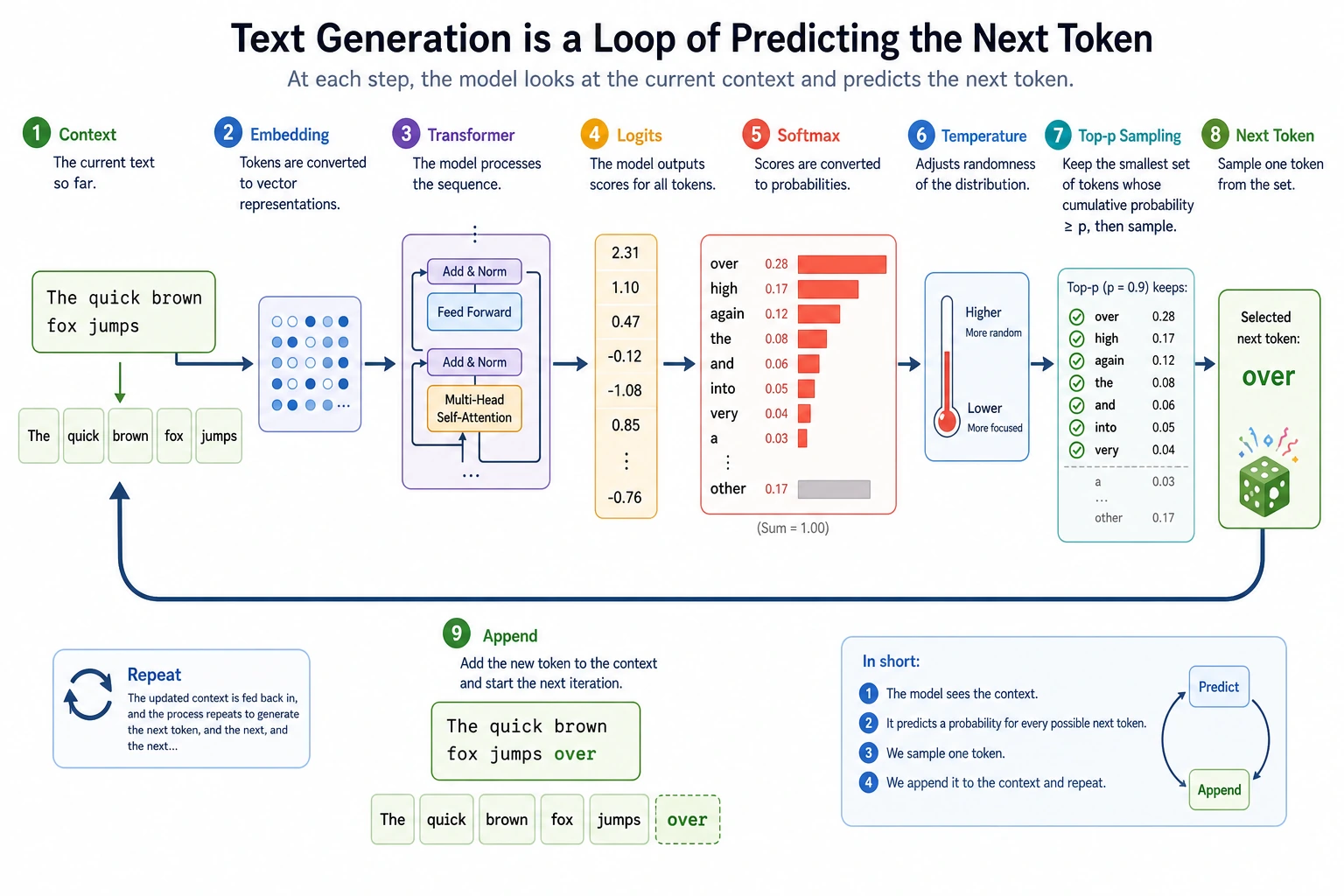
Core Loop
A large language model does not write a whole answer at once. It repeats this loop:
context -> logits -> probabilities -> choose next token -> append token -> repeat
Concept Map
| Concept | Practical meaning |
|---|---|
| token | the unit the model reads and writes |
| context window | token budget shared by system prompt, history, evidence, user question, and output |
| embedding | vector representation of tokens |
| attention | relevance-weighted information mixing across tokens |
| logits | raw scores before probabilities |
| temperature | knob that flattens or sharpens the probability distribution |
| pretraining | broad capability from large-scale text |
| instruction tuning / alignment | makes capability behave more like an assistant |
Lab 1: Next-Token Prediction
import numpy as np
context = "Beijing is China's"
candidates = ["capital", "city", "university"]
logits = np.array([4.0, 2.0, 0.5])
def softmax(x):
e = np.exp(x - x.max())
return e / e.sum()
probs = softmax(logits)
best = candidates[np.argmax(probs)]
print("Context:", context)
for token, prob in zip(candidates, probs):
print(f"Candidate token={token}, probability={prob:.3f}")
print("Most likely next token:", best)
Expected output:
Context: Beijing is China's
Candidate token=capital, probability=0.858
Candidate token=city, probability=0.116
Candidate token=university, probability=0.026
Most likely next token: capital
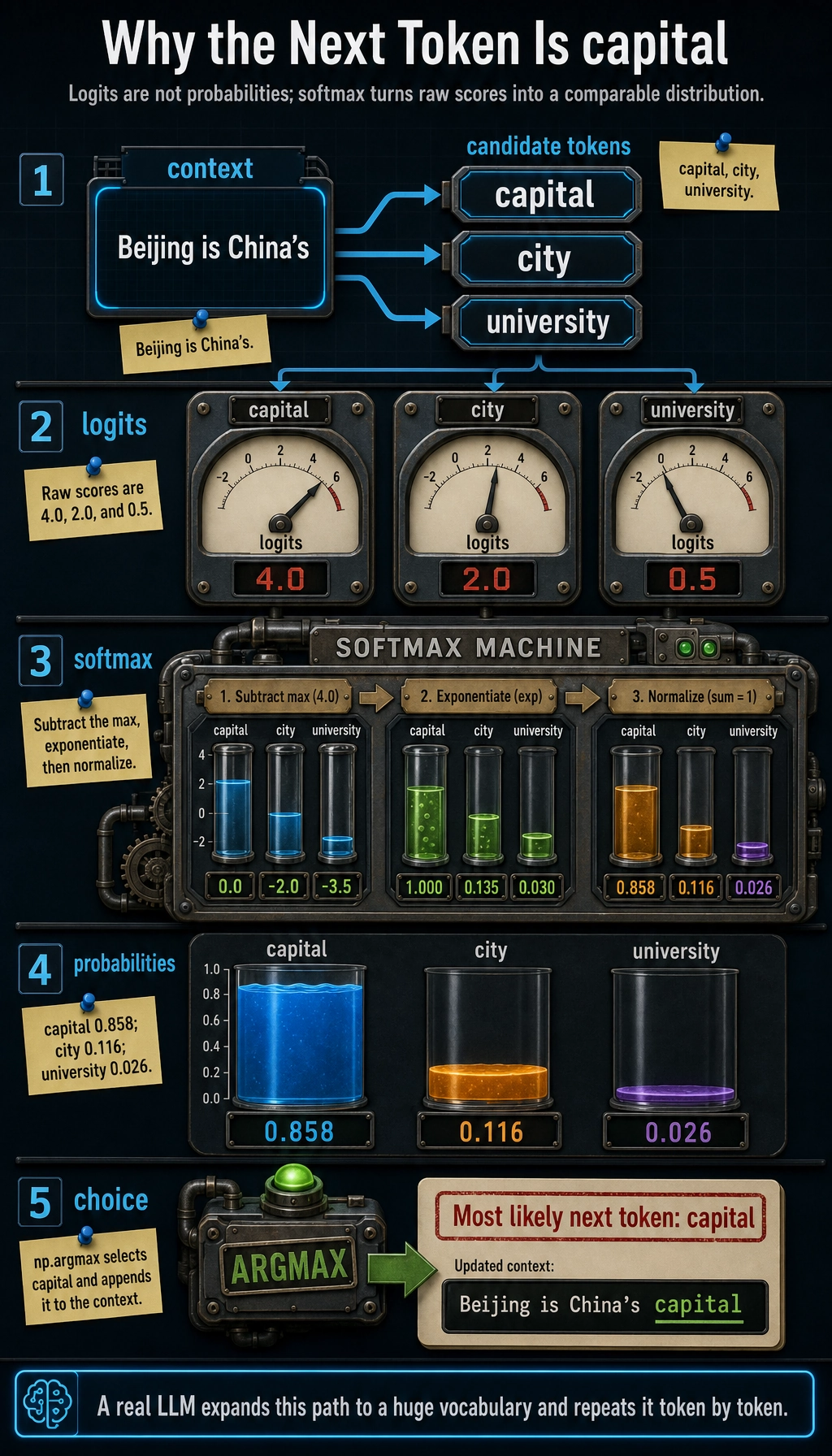
Real models do this over a very large vocabulary. The principle is the same: output scores, convert to probabilities, choose the next token.
Context Window Is a Budget
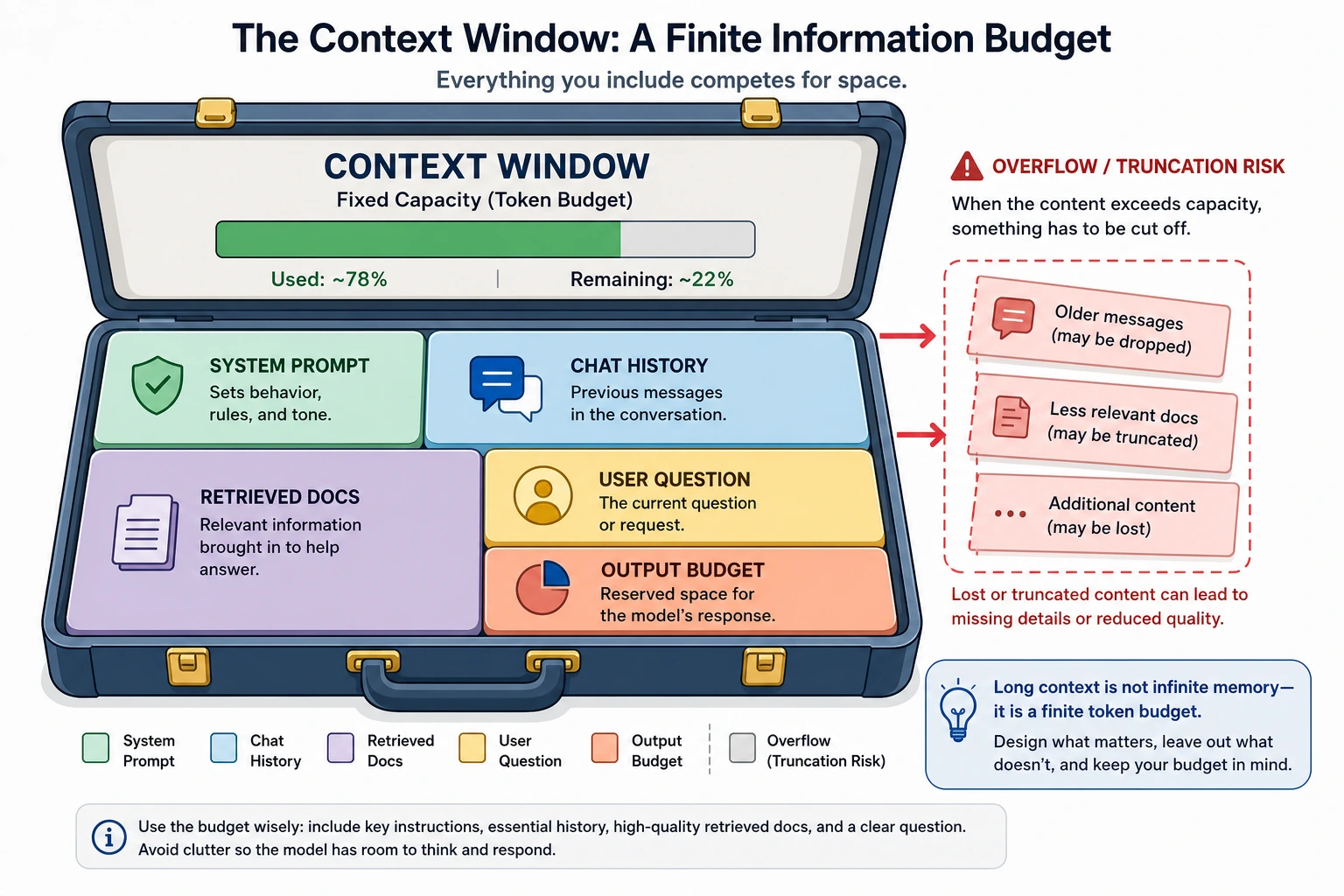
The context window is not infinite memory. It is a fixed token budget:
system prompt + chat history + retrieved evidence + user question + answer space <= context window
Practical consequences:
- Long documents must be selected, compressed, or chunked.
- RAG must reserve space for both evidence and the final answer.
- Chat history should be summarized or trimmed when it stops helping.
- Bigger context helps only if the right information is placed inside it.
Lab 2: Temperature Changes Sampling
import numpy as np
tokens = ["Beijing", "Shanghai", "Guangzhou"]
logits = np.array([3.0, 1.5, 0.5])
def softmax_with_temperature(logits, temperature=1.0):
scaled = logits / temperature
exp_values = np.exp(scaled - scaled.max())
return exp_values / exp_values.sum()
for temp in [0.5, 1.0, 2.0]:
probs = softmax_with_temperature(logits, temperature=temp)
print(f"temperature={temp}")
for token, prob in zip(tokens, probs):
print(f" {token}: {prob:.4f}")
Expected output:
temperature=0.5
Beijing: 0.9465
Shanghai: 0.0471
Guangzhou: 0.0064
temperature=1.0
Beijing: 0.7662
Shanghai: 0.1710
Guangzhou: 0.0629
temperature=2.0
Beijing: 0.5685
Shanghai: 0.2686
Guangzhou: 0.1629
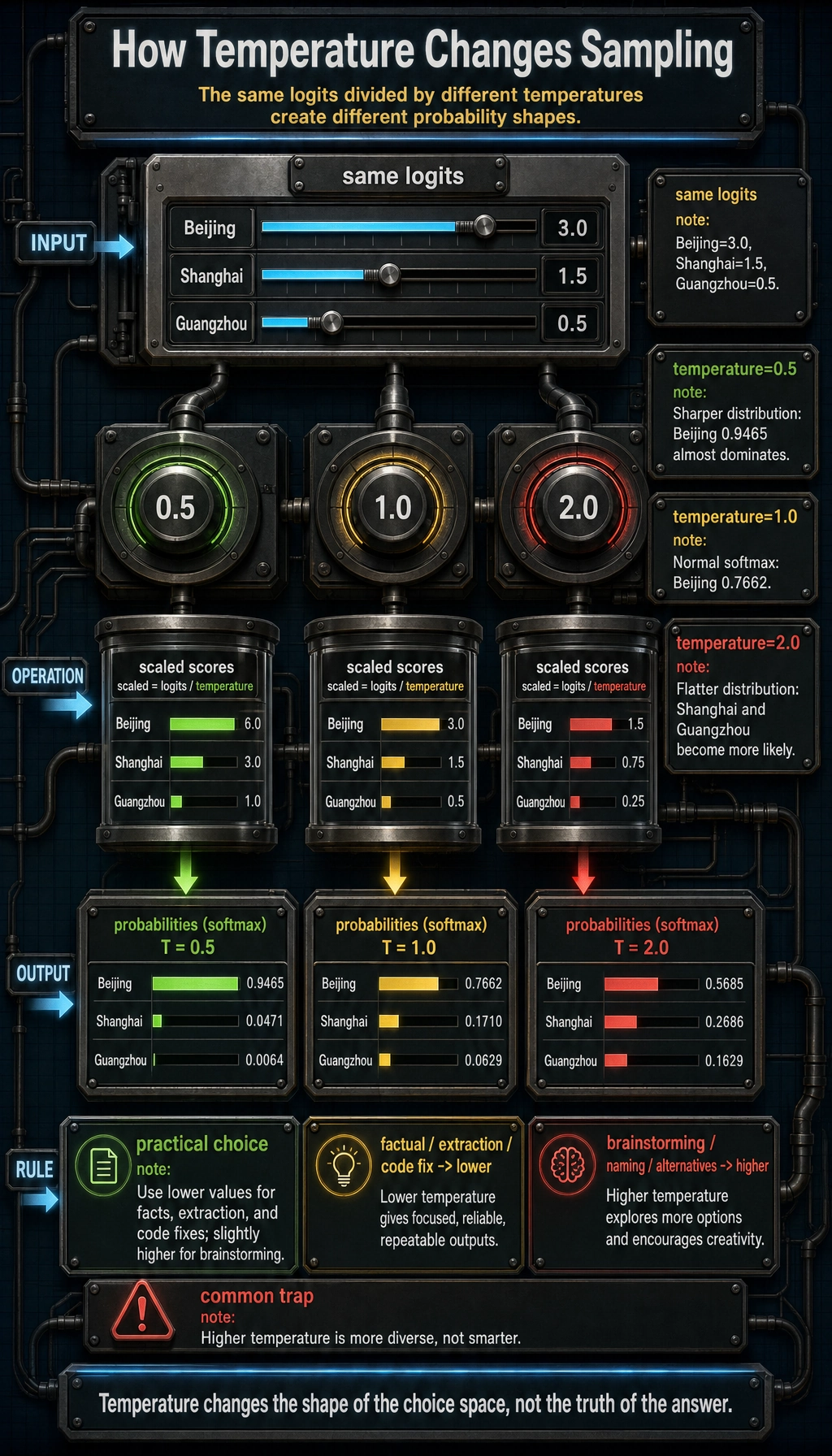
Interpretation:
- lower temperature makes the top choice dominate;
- higher temperature makes lower-ranked tokens more likely;
- higher temperature does not mean smarter, only more diverse.
For factual support, extraction, and code fixes, start lower. For brainstorming, naming, and drafting alternatives, a higher temperature can help.
Lab 3: Attention as Relevance-Weighted Mixing
import numpy as np
X = np.array([
[1.0, 0.0],
[0.0, 1.0],
[1.0, 1.0],
])
Q = X
K = X
V = X
scores = Q @ K.T
scaled_scores = scores / np.sqrt(K.shape[1])
def softmax(row):
e = np.exp(row - row.max())
return e / e.sum()
attention_weights = np.apply_along_axis(softmax, 1, scaled_scores)
output = attention_weights @ V
print("Attention scores:\n", np.round(scaled_scores, 3))
print("Attention weights:\n", np.round(attention_weights, 3))
print("Output representations:\n", np.round(output, 3))
Expected output:
Attention scores:
[[0.707 0. 0.707]
[0. 0.707 0.707]
[0.707 0.707 1.414]]
Attention weights:
[[0.401 0.198 0.401]
[0.198 0.401 0.401]
[0.248 0.248 0.503]]
Output representations:
[[0.802 0.599]
[0.599 0.802]
[0.752 0.752]]
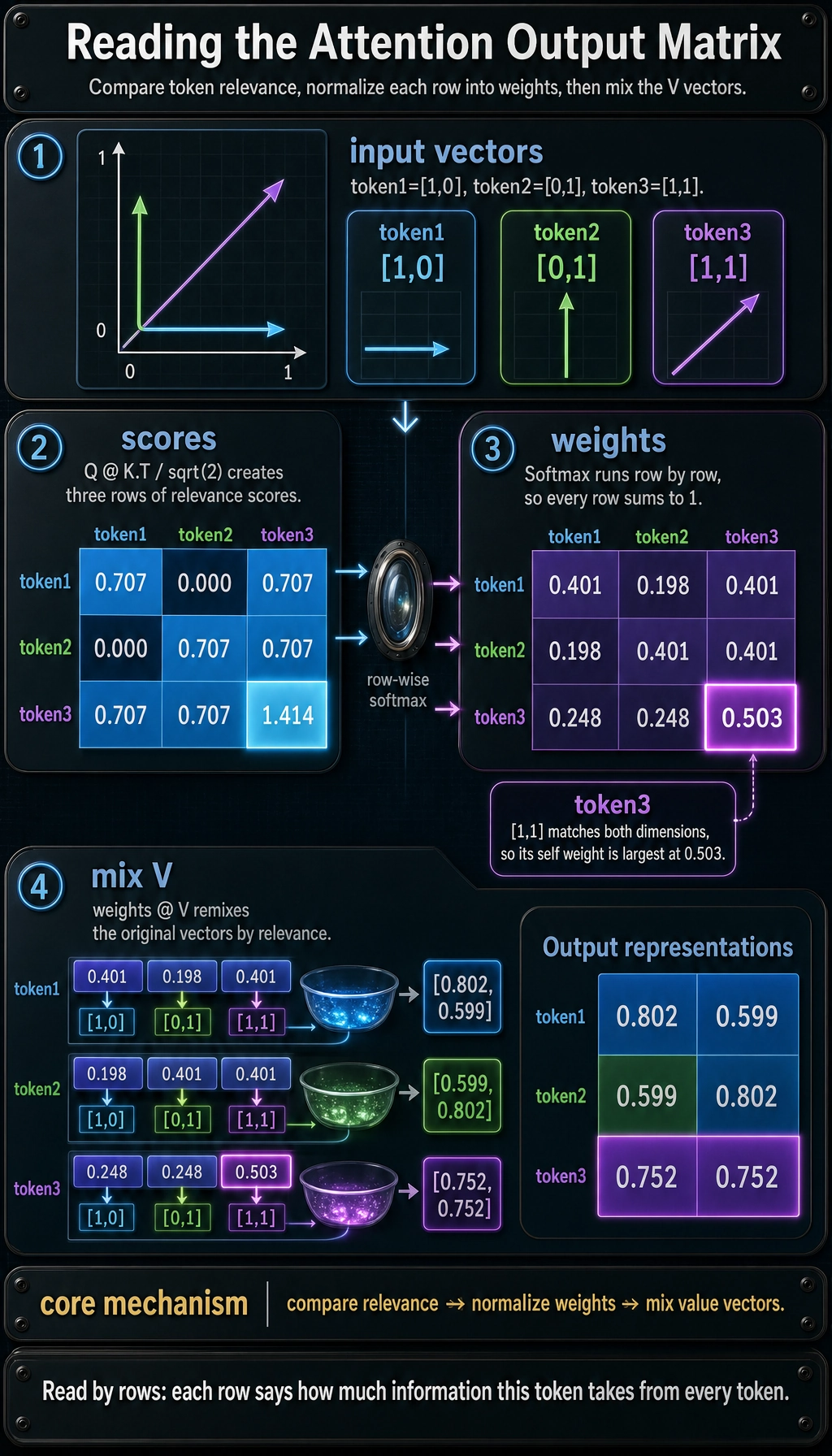
You do not need to memorize the formula yet. Keep the mechanism:
compare relevance -> normalize weights -> mix value vectors
Capability Layers
| Layer | What it contributes | Does it change model weights? |
|---|---|---|
| pretraining | broad language and world-pattern capability | yes |
| instruction tuning | better response style and task following | yes |
| preference learning / RLHF | more helpful and safer behavior | yes |
| prompt | task instructions and examples at runtime | no |
| RAG | external evidence at runtime | no |
| tool calling / Agent | actions beyond text generation | no or partly |
| fine-tuning / LoRA | repeated domain behavior adaptation | yes |
Misconceptions to Avoid
- A token is not always one word or one character.
- A larger context window is not the same as better memory.
- Temperature controls diversity, not truth.
- Attention weights are useful intuition, but not a complete explanation of reasoning.
- Pretraining gives capability; product reliability still needs data, evaluation, and controls.
Exercises
- Change the first logit in Lab 1 from
4.0to2.2. How does the winner’s confidence change? - In Lab 2, try
temperature=0.1andtemperature=5.0. - In Lab 3, change the third token vector from
[1.0, 1.0]to[2.0, 0.0]. What happens? - Design a 1,000-token RAG budget: system prompt, evidence, user question, answer space.
- Explain why a model can be capable but still need RAG or alignment.
Summary
The core concepts are connected:
tokens fill the context -> Transformer mixes token information -> logits score next tokens -> sampling chooses one -> adaptation makes behavior useful
Once this loop is clear, RAG, agents, fine-tuning, and evaluation become engineering choices around the same model core.