7.2.4 LLM Industry Landscape
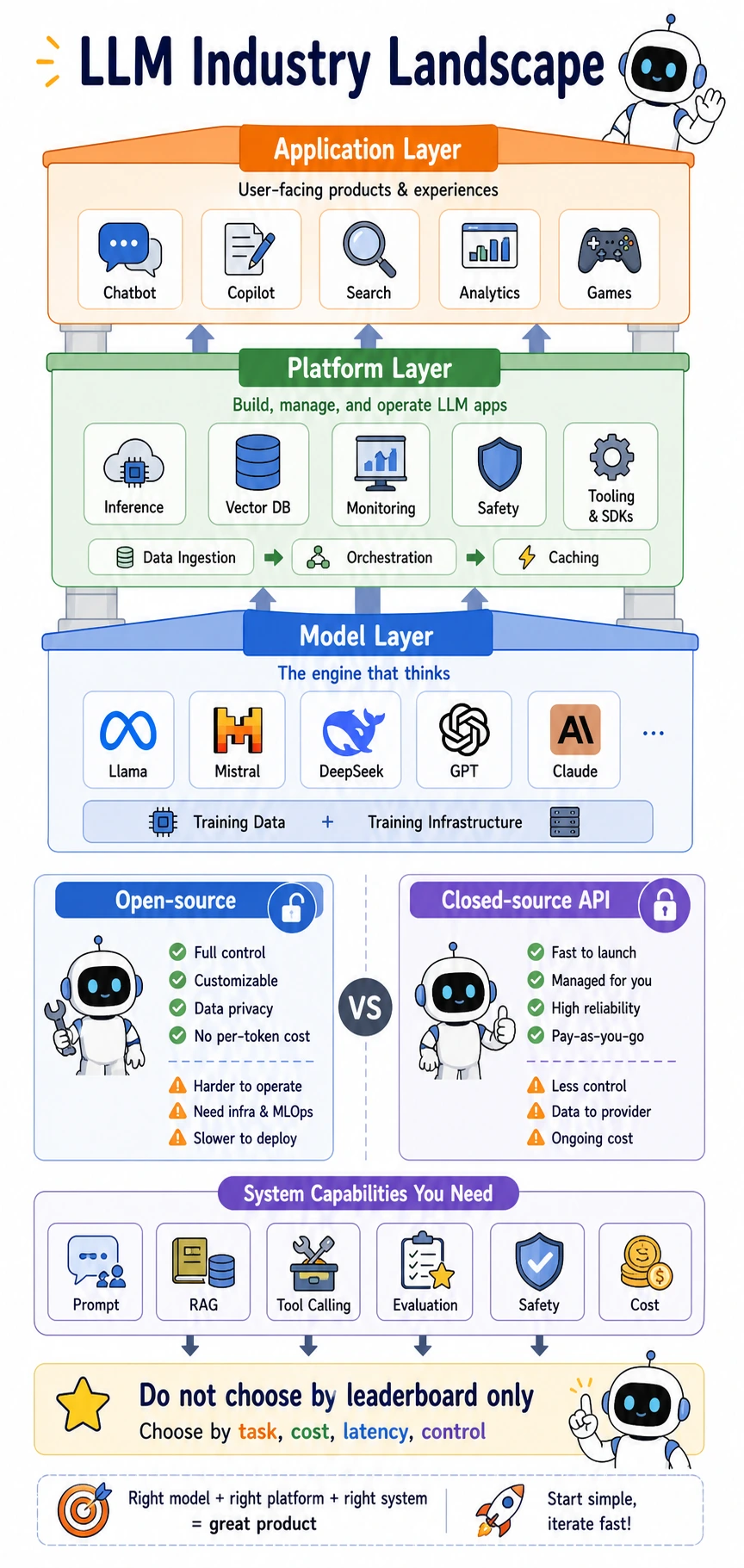
Read it as a stack: the model layer provides the engine, the platform layer makes the engine usable and observable, and the application layer turns capability into user-facing workflows. Open-source and closed-source APIs are not “good vs bad”; they are different trade-offs among control, cost, latency, privacy, and operations.
Learning Objectives
After completing this section, you will be able to:
- Understand the LLM ecosystem from an industry-chain perspective
- Distinguish what the model layer, platform layer, and application layer each do
- Understand the different strengths of open-source and closed-source approaches
- Practice model selection thinking with a small example
First, break the industry chain down
Model layer: who is building the "engine"?
The model layer is mainly responsible for training foundation models and general-purpose models. You can think of it as "the people who build the engine."
This layer usually focuses on:
- Model architecture
- Training data
- Training compute
- Model capabilities
Common forms include:
- Closed-source API models
- Open-source downloadable models
- Industry-specific models
Platform layer: who makes models easier to use?
The platform layer is like "the people who build roads and supply electricity."
What they usually do includes:
- Model hosting
- Inference services
- Vector databases
- Monitoring and evaluation
- Fine-tuning platforms
- Agent / workflow development frameworks
Without the platform layer, many teams would struggle to put models into production reliably, even if they already had the model.
Beginner glossary: words that appear often in the platform layer
| Term | What it means | Why it matters |
|---|---|---|
| API | A standard interface for calling a model or service | Lets your application request model results without managing the model internals |
| Inference | Running the model to produce an output | This is what happens every time a user asks a question |
| Vector database | A database optimized for storing and searching embeddings | It is often used as the retrieval layer in RAG systems |
| Monitoring | Observing latency, errors, cost, and output quality over time | Production systems need this to detect problems early |
| Evaluation | Measuring whether outputs meet task requirements | It prevents teams from judging models only by feeling |
Application layer: the layer closest to users
The application layer sells results, not models
The application layer is more like "the people who run a restaurant."
Users usually do not care which attention mechanism you use. They care about:
- Whether it can help me complete the task
- Whether the answer is reliable
- Whether it is fast enough
- Whether the cost is acceptable
Typical applications include:
- AI search
- AI customer service
- AI coding assistants
- AI office tools
- AI teaching assistants
The same model can become many different products
The same foundation model may turn into completely different products in different teams:
- Legal assistant
- Sales assistant
- Education assistant
- Code review tool
This shows that industry competition is not only about "whose model is bigger." It also happens in:
- Workflow design
- Data accumulation
- Product experience
- Industry know-how
How should you choose between open-source and closed-source approaches?
Closed-source models are more like "plug-and-play mature engines"
Their advantages are usually:
- Strong out-of-the-box performance
- Less model maintenance work
- Faster time to launch
Their trade-offs are usually:
- Cost is charged per API call
- Less controllable
- Private deployment is more limited
Open-source models are more like "engines you can modify yourself"
Their advantages are usually:
- Can be self-hosted
- Can be fine-tuned
- More control over data and inference pipeline
Their trade-offs are usually:
- Deployment and maintenance are more complex
- Performance is not always naturally the strongest
- Requires more engineering capability
One-sentence memory aid:
Closed-source is easier to use, open-source is more controllable.
What many teams really compete on is "system capability"
The model is only one component in the system
In real-world LLM products, it is usually not "the model acting alone," but the collaboration of an entire system:
- Prompt
- RAG
- Tool calling
- Evaluation framework
- Safety strategy
- Cost control
In other words:
User experience = model capability × system design × data quality
Why can the same model feel very different in different products?
Because what really determines the experience often also includes:
- How good the knowledge base is
- How accurate the tools are
- Whether there is a fallback when things fail
- How well latency is controlled
This is also why "being able to call an API" is not the same as "being able to build an AI product."
A practical framework for model selection
Do not ask first, "Which one is the strongest?" Ask first, "What do I need?"
Common selection dimensions include:
| Dimension | Question to ask |
|---|---|
| Quality | Is the task performance good enough? |
| Cost | Is each call expensive? |
| Latency | Can users accept the response speed? |
| Controllability | Can it be privately deployed, fine-tuned, and audited? |
| Multimodal | Do you need image understanding or audio? |
| Tool capability | Do you need function calling / agent support? |
A small scoring script
This example is not about choosing a real latest model. It is for practicing how to score based on requirements.
models = {
"cloud_api_model": {
"quality": 9,
"cost": 4,
"latency": 8,
"control": 4
},
"open_source_8b": {
"quality": 6,
"cost": 9,
"latency": 7,
"control": 9
},
"open_source_70b": {
"quality": 8,
"cost": 5,
"latency": 5,
"control": 9
}
}
weights = {
"quality": 0.4,
"cost": 0.2,
"latency": 0.2,
"control": 0.2
}
def score_model(info, weights):
return sum(info[k] * weights[k] for k in weights)
scores = []
for name, info in models.items():
scores.append((score_model(info, weights), name))
for score, name in sorted(scores, reverse=True):
print(name, "->", round(score, 2))
Expected output:
open_source_8b -> 7.4
open_source_70b -> 7.0
cloud_api_model -> 6.8
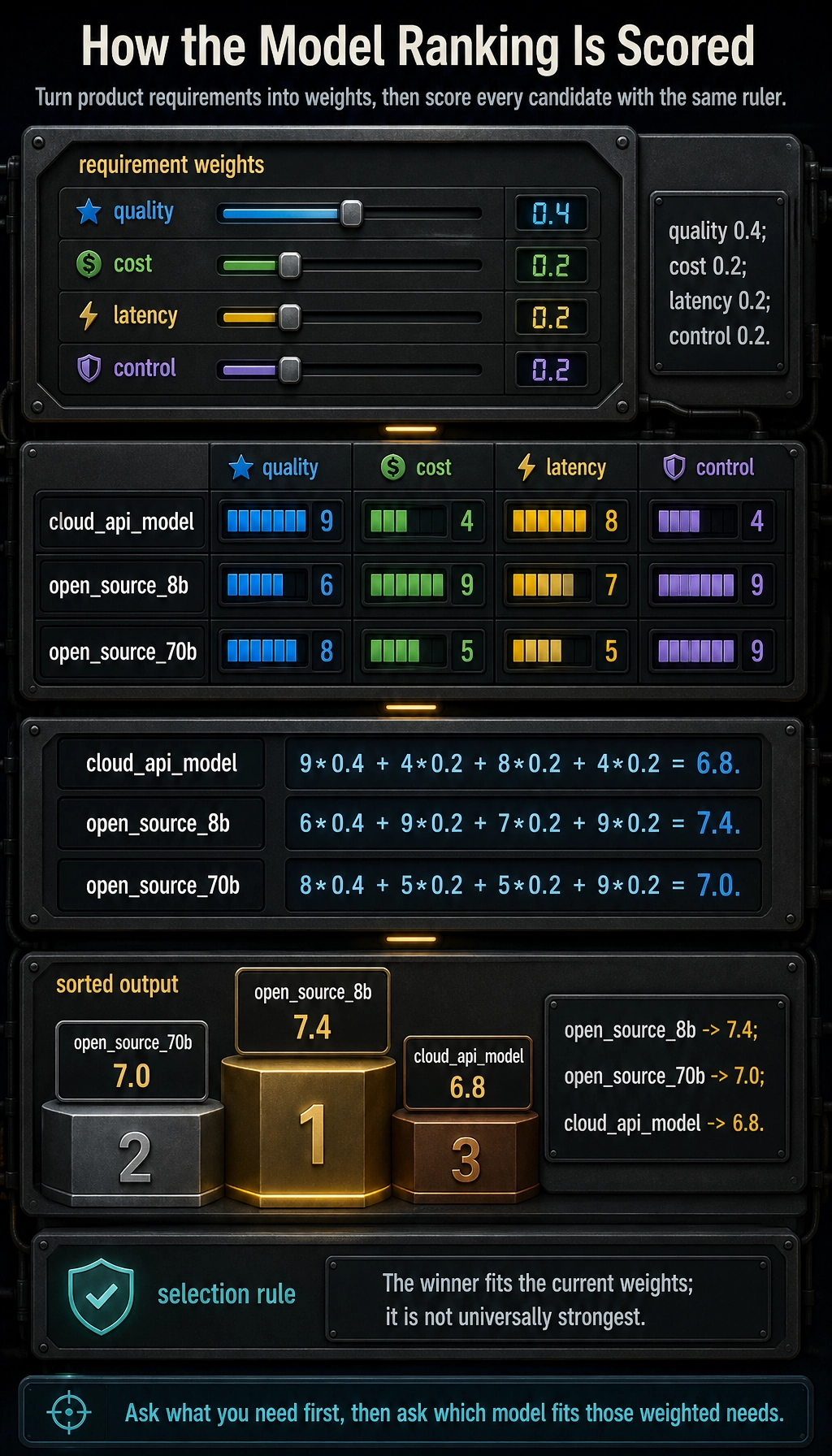
You can change weights to simulate different preferences in different companies.
Why does the "industry landscape" matter to engineers too?
Because you make technical choices every day
You will keep running into questions like:
- Use an API or self-host it?
- Start with RAG or start with fine-tuning?
- Use a general-purpose model or a vertical model?
- Use a single model or multi-model routing?
At their core, these questions are all related to industry structure.
Because technology choices affect your career path
Different roles tend to emphasize different skills:
- Foundation models: more focused on training and algorithms
- Platform engineering: more focused on inference, deployment, and optimization
- Application engineering: more focused on product, workflows, and evaluation
Understanding the industry landscape can help you more clearly see which kind of role you want to move toward.
Common beginner mistakes
Only looking at leaderboards
Leaderboards are useful, but they are not everything. In real projects, cost, latency, and stability are equally important.
Thinking open-source is always cheaper
A model being open-source does not mean training, deployment, and maintenance are all cheap.
Thinking there is always a "best model"
Many times there is no "absolute best," only "the most suitable for the current scenario."
Summary
The most important idea in this section is:
The LLM industry is not just a competition of model parameters. It is a competition of the combination of models, platforms, data, products, and engineering capability.
For application builders, understanding the industry landscape is not about following trends. It is about making more stable technical and product decisions.
Exercises
- Change the weights in the scoring script to simulate the model-selection preferences of a "startup team" and a "financial enterprise."
- Think about this: if your project requires private deployment, how would the priority between open-source and closed-source approaches change?
- Explain in your own words: why is the real competitive advantage often not just the model itself?