7.3.2 Transformer Architecture Review and Deep Dive
If you have studied attention mechanisms, you may already know terms like Q / K / V.
But when you really get to the large model stage, many people still get stuck:
- Why does a block use attention first and then a feed-forward network?
- Why do residual connections and LayerNorm keep showing up again and again?
- Why can the same Transformer lead GPT and BERT down different paths in the end?
The goal of this lesson is not to memorize the structure diagram again, but to break down a Transformer block so you can explain it clearly by following the data flow.
Learning Goals
- Understand what each module inside a Transformer block is responsible for
- Understand how token embedding, positional information, self-attention, and FFN are connected
- Build intuition for “how data flows” through a runnable minimal block example
- Understand why residual connections and normalization are important for deep networks
Why Did Transformer Become the Backbone of Large Models?
It solves the problem of “who should look at whom” in a sequence
Language is naturally a sequence. When a model processes a sentence, it needs to know:
- Which previous words are related to the current word
- Which positions are more important
- How to preserve long-range dependencies
The RNN idea is to read sequentially, the CNN idea is local convolution, and the Transformer idea is:
Let each position actively “look at” other positions and assign them weights.
That is the core of self-attention.
The real strength of Transformer is not just attention
Many people simplify Transformer as:
- A network with attention
But what really makes it suitable for large-scale training is a whole set of components working together:
- token embedding
- positional representation
- multi-head self-attention
- residual connections
- LayerNorm
- feed-forward network
- stackable block structure
This combination allows it to model sequence relationships, scale deep, scale large, and parallelize well.
An analogy: each block is like one round of “discussion + organization”
You can think of a Transformer block as a meeting:
- Self-attention is like “each token listening to what other tokens are saying”
- The feed-forward network is like “after absorbing the context, each token does one more round of internal processing on its own”
- Residual connection is like “keep the original message; don’t let the new processing completely overwrite it”
One block processes one round, and many blocks stacked together are like a group repeatedly discussing and organizing information.
What Is Inside a Transformer Block?
The input is first turned into vectors
What the model sees is not text itself, but token ids. These token ids are looked up in the embedding table and turned into vectors.
For example:
I->[0.2, -0.1, 0.8, ...]like->[0.7, 0.3, -0.2, ...]
This step does:
Convert discrete symbols into representations in a continuous space.
Then positional information is added
Attention itself only cares about relationships inside a set, and it does not know which position a token originally occupied.
So we must tell the model:
- the 1st token
- the 2nd token
- the 3rd token
This positional information can be injected through:
- sinusoidal positional encoding
- learnable position vectors
- relative position methods such as RoPE
Self-attention handles “cross-token communication”
In self-attention, each token generates three representations:
- Query: what I want to find
- Key: what I can offer
- Value: what you get if you attend to me
Then each token does two steps:
- Use its own
Queryand other tokens’Keyto compute similarity - Use those similarities to weight other tokens’
Value
The result is:
- a new representation that combines context
The feed-forward network handles “per-token deep processing”
When beginners learn Transformer, they often treat attention as the only core part. But in fact, FFN is also very important.
Its characteristics are:
- Each token passes through a small MLP independently
- No cross-token communication
- But it enhances nonlinear expressive power
You can understand it as:
Attention exchanges information, FFN digests information.
Why do residuals and normalization keep appearing?
Because deep networks are easy to train unstably. The role of residual connections and LayerNorm can be roughly remembered as:
- Residual: preserve old information, so new information becomes an “incremental update”
- LayerNorm: bring each layer’s output back into a more stable numeric range
Without them, deep Transformers can become hard to train very easily.
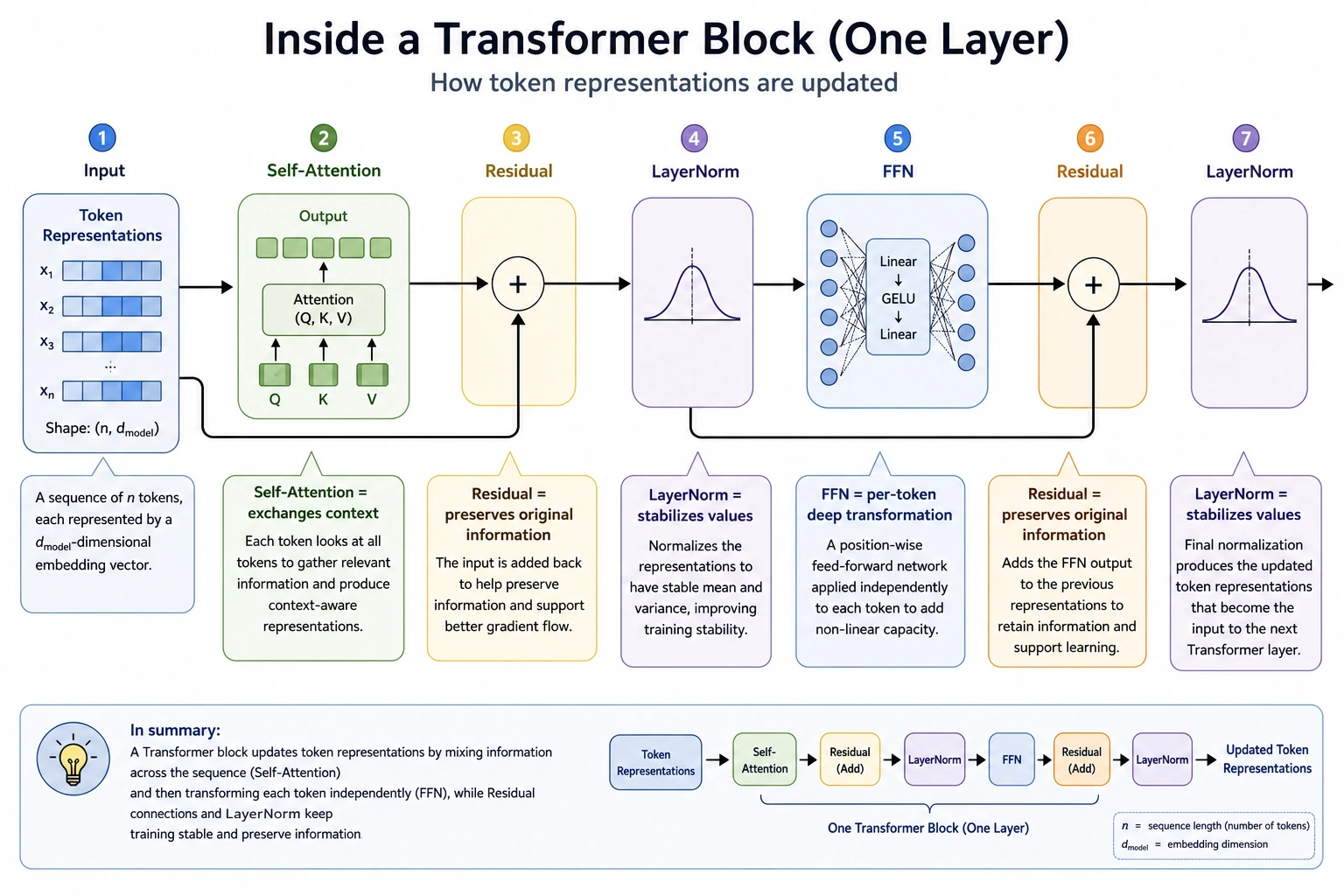
It is recommended to read this diagram according to the data flow of one block: token representations first communicate with context through Self-Attention, then LayerNorm/Residual keep the information stable, and then FFN performs token-by-token deep processing. Transformer is not just attention, but a combination of “communication, preservation, stability, and processing.”
Let’s Run a Real Minimal Transformer Block First
The code below uses pure Python to do one thing:
- Take three token vectors as input
- Compute single-head self-attention
- Apply a residual connection
- Then pass through a small feed-forward network
It is not a complete production implementation, but each step corresponds to the core structure of a real block.
from math import exp, sqrt
tokens = [
[1.0, 0.0, 1.0],
[0.0, 1.0, 1.0],
[1.0, 1.0, 0.0],
]
W_q = [
[1.0, 0.0],
[0.5, 1.0],
[0.0, 1.0],
]
W_k = [
[1.0, 0.5],
[0.0, 1.0],
[1.0, 0.0],
]
W_v = [
[1.0, 0.0, 0.5],
[0.0, 1.0, 0.5],
]
W1 = [
[1.0, -0.5],
[0.5, 1.0],
[1.0, 0.5],
]
W2 = [
[0.5, 1.0, 0.0],
[1.0, 0.0, 0.5],
]
def matmul_vec(vec, matrix):
return [
sum(vec[i] * matrix[i][j] for i in range(len(vec)))
for j in range(len(matrix[0]))
]
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
def softmax(values):
m = max(values)
exps = [exp(v - m) for v in values]
total = sum(exps)
return [x / total for x in exps]
def add(a, b):
return [x + y for x, y in zip(a, b)]
def relu(vec):
return [max(0.0, x) for x in vec]
Q = [matmul_vec(token, W_q) for token in tokens]
K = [matmul_vec(token, W_k) for token in tokens]
V_in = [[1.0, 0.0], [0.0, 1.0], [1.0, 1.0]]
V = [matmul_vec(v, W_v) for v in V_in]
scale = sqrt(len(Q[0]))
scores = []
for i, q in enumerate(Q):
row = []
for j, k in enumerate(K):
row.append(dot(q, k) / scale if j <= i else -10**9)
scores.append(row)
weights = [softmax(row) for row in scores]
contexts = []
for row in weights:
context = [0.0, 0.0, 0.0]
for w, v in zip(row, V):
context = [c + w * x for c, x in zip(context, v)]
contexts.append(context)
after_attention = [add(token, context) for token, context in zip(tokens, contexts)]
ffn_hidden = [relu(matmul_vec(vec, W1)) for vec in after_attention]
ffn_output = [matmul_vec(vec, W2) for vec in ffn_hidden]
block_output = [add(x, y) for x, y in zip(after_attention, ffn_output)]
print("attention weights:")
for row in weights:
print([round(x, 3) for x in row])
print("\nblock output:")
for row in block_output:
print([round(x, 3) for x in row])
Expected output:
attention weights:
[1.0, 0.0, 0.0]
[0.413, 0.587, 0.0]
[0.456, 0.225, 0.32]
block output:
[3.75, 3.5, 1.5]
[3.897, 4.294, 2.566]
[4.366, 4.752, 1.153]
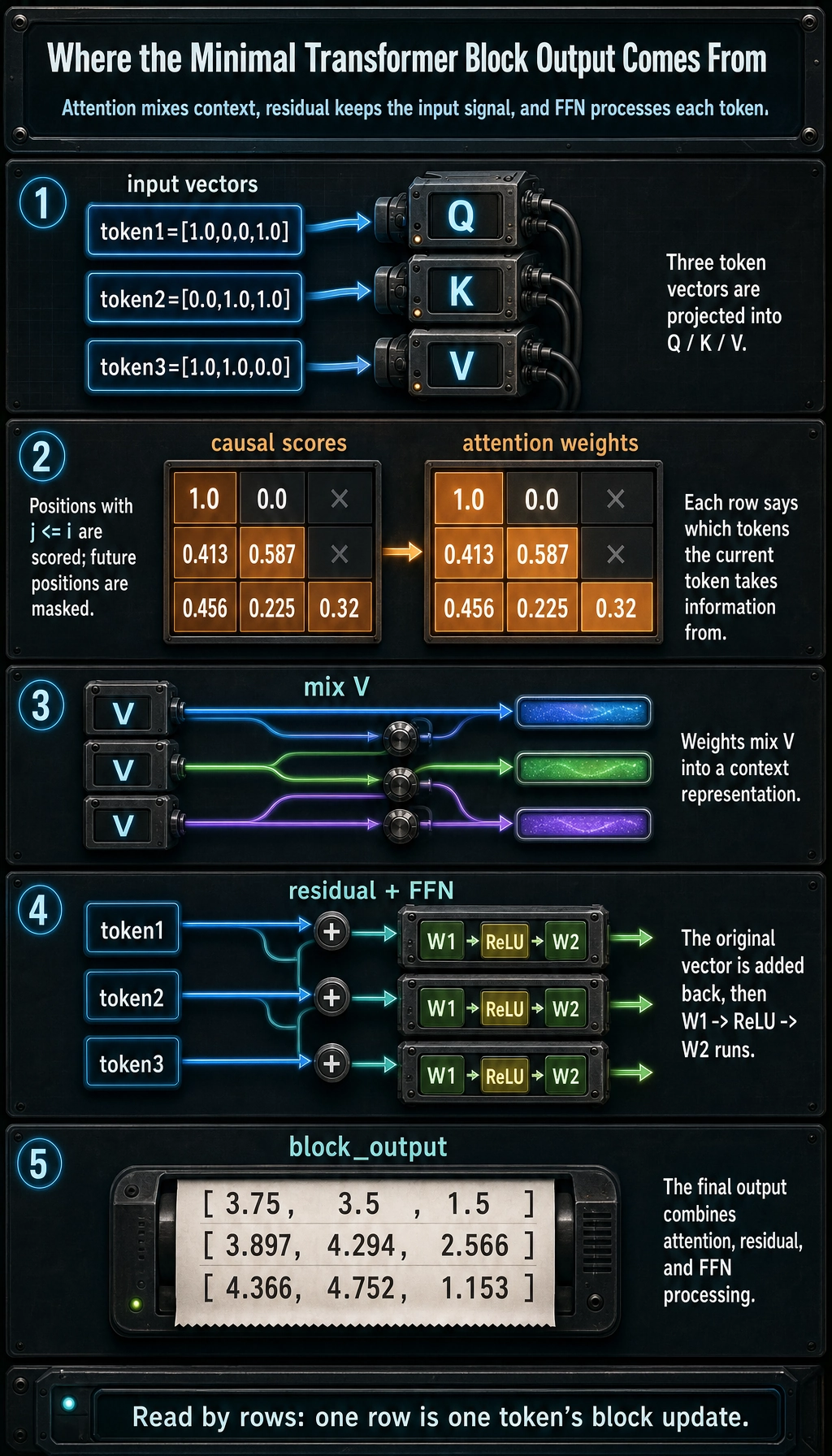
When reading this code, focus on four places first
There are only four key parts:
- Generation of
Q / K / V - Computation of
scores - Weighted sum after
softmax - Residual connection + FFN
If you understand these four parts, your understanding of the Transformer block has already moved beyond “just memorizing the diagram.”
Why do we add a causal mask here?
You will see this line:
row.append(dot(q, k) / scale if j <= i else -10**9)
It means:
- The current token can only see itself and previous tokens
- It cannot peek into the future
This is exactly the key constraint during training for decoder-only models like GPT.
If you remove j <= i,
it becomes more like bidirectional attention in an encoder.
Why does attention still need an FFN afterward?
Because attention is only for “aggregating context.” It tells the current token:
- Who should I pay attention to?
But it is not good at sufficiently nonlinear transformation. The FFN’s job is:
- Process the context-fused representation once more
So they have different responsibilities, and both are necessary.
Putting the Block Back Into the Whole Architecture
Stacking multiple layers means abstraction layer by layer
The first layer of attention may mostly see:
- lexical relationships
- nearby patterns
Higher layers may gradually form:
- syntactic relationships
- semantic roles
- long-range dependencies
- task-related features
That is why Transformer is not just “one layer of attention,” but many block layers stacked together.
The main difference between Encoder and Decoder lies in mask and interaction style
If you only look at the block, they are essentially very similar. The main differences are:
- encoder: usually bidirectional self-attention
- decoder: usually causal mask
- encoder-decoder: the decoder also has an extra cross-attention layer
So many architectural differences can eventually be traced back to:
- who can see whom
Why did GPT keep only the decoder?
Because the most important structural constraint for generation tasks is:
- predict the future based only on the past
decoder-only fits this goal better, and the structure is more direct. This is one of the reasons why the GPT series could keep scaling up.
Engineering Details That Are Easy to Overlook
Attention is not free
Each token has to compare with all other tokens, and as the sequence gets longer, the cost rises quickly.
That is why later on people introduced:
- efficient attention
- KV cache
- GQA / MQA
- FlashAttention
and other improvements.
The block structure looks repetitive, but training is not easy
When the number of layers and hidden size increases, you will quickly run into:
- memory pressure
- gradient stability
- trade-offs between throughput and latency
So the reason Transformer became the backbone of large models is not only because the structure is elegant, but also because many engineering details gradually matured.
Once you understand the block, many later chapters become much easier
Later when you learn:
- architectural variants
- efficient attention
- pretraining methods
- fine-tuning
they are all essentially modifications or applications built around this block.
Common Misunderstandings
Misunderstanding 1: Transformer = attention
Not complete. Transformer is a block design, not an isolated formula.
Misunderstanding 2: FFN is just a supporting role
Wrong. It handles very important nonlinear feature transformation.
Misunderstanding 3: Knowing QKV means you understand Transformer
True understanding also includes:
- why residuals matter
- why masks determine behavior
- why stacking multiple layers can form abstractions
Summary
The most important thing in this lesson is not to memorize the diagram again, but to connect the data flow of a Transformer block:
Token vectors first communicate with context through attention, then undergo deep processing in the feed-forward network, and rely on residual connections and normalization to maintain training stability across stacked layers.
Once this chain is clear in your mind, many seemingly “very complex” large-model structures are actually just variations built around this block.
Exercises
- Change
j <= iin the example to always allow attention, and observe how the attention weights change. - Try removing the residual connection and see whether the relationship between
block_outputand the original input is still stable. - Explain in your own words: why do we say attention exchanges information while FFN digests information?
- Think about this: if you stack this block 48 layers deep, what engineering problem would worry you the most?