7.6.5 Fine-Tuning Engineering Practice
Many fine-tuning projects do not fail because “the model is not strong enough,” but because they fail earlier:
- Vague task definition
- Messy data format
- Leakage between the training and validation sets
- Metrics that only look at loss and not at outputs
So in this lesson, we will not talk about “the fanciest method.” Instead, we will focus on:
From the start of a fine-tuning project to its deployment, what should the engineering workflow actually look like?
Learning Objectives
- Understand the full engineering workflow of a fine-tuning project
- Learn how to organize raw business data into training samples
- Know how to split data, plan batch sizes, and estimate training steps
- Build the habit of checking what to look at before, during, and after training
The real starting point of a fine-tuning project is not “start training”
First, write the task as one very specific sentence
Many teams begin by saying:
- We want to fine-tune a customer service model
This is actually too broad. A task definition that is more executable would be:
“Given the user’s question and order context, generate a polite, concise reply that follows the refund policy.”
You can see that this already implies a lot of key information:
- What the input is
- What the output is
- What the style is
- What the business boundaries are
If this step is vague, all the data and metrics that follow will drift too.
Run a baseline first, then talk about fine-tuning
Before training, you should try to produce a baseline using methods like:
- Plain Prompt
- Prompt + structured output
- RAG
- Tool calling
The reason is simple:
- If you can solve the problem without fine-tuning, do not increase system complexity for no reason
- If the baseline is already strong, the gain from fine-tuning may be small
- If the baseline is weak, it becomes easier to see what fine-tuning actually improves
First decide the “basic unit” of training samples
There are three common training units:
- Instruction-answer pairs
- Multi-turn conversations
- Preference comparison samples
This section mainly discusses supervised fine-tuning (SFT) engineering practice, so the most common unit is:
messagesprompt/completion
Do not underestimate this decision. It will directly affect your later data cleaning and template format.
Terms worth understanding before touching training scripts
| Term | Beginner-friendly meaning | Why it matters here |
|---|---|---|
| SFT | Supervised Fine-Tuning: continue training with high-quality input-output examples | It is the main fine-tuning style used in this lesson |
messages | A chat-style sample made of system, user, and assistant turns | It matches how many chat models are trained and served |
prompt/completion | A simpler pair: input prompt plus target answer | Useful for single-turn tasks or older dataset formats |
| Validation set | Held-out samples not used for training | It estimates whether the model generalizes beyond the training examples |
| Leakage | Similar or same-source samples appearing in both train and validation sets | It makes validation scores look better than the real ability |
Three things that are easy to ignore before training
Unclear goals will make the data messier and messier
If your annotators do not know:
- Whether the reply should be concise or detailed
- Whether the model should proactively explain the reason
- Whether it should refuse out-of-scope requests
then the resulting data will definitely drift in style.
Data leakage makes the validation set falsely optimistic
A very common problem is:
- Multiple tickets from the same customer
- Slightly rewritten versions of the same FAQ
- One article split into several similar fragments
If these samples appear in both training and validation, you may think the model generalizes well, but in reality it is just memorizing data from the same source.
A decreasing loss does not mean the model is usable for business
For large models, this often happens:
- Loss goes down
- But the output style is still wrong
- Or the format sometimes breaks
- Or the model gives a long explanation before answering
So you cannot look only at the training curve. You also need to check:
- Structured format accuracy
- Hit rate for key business fields
- Human review of typical samples
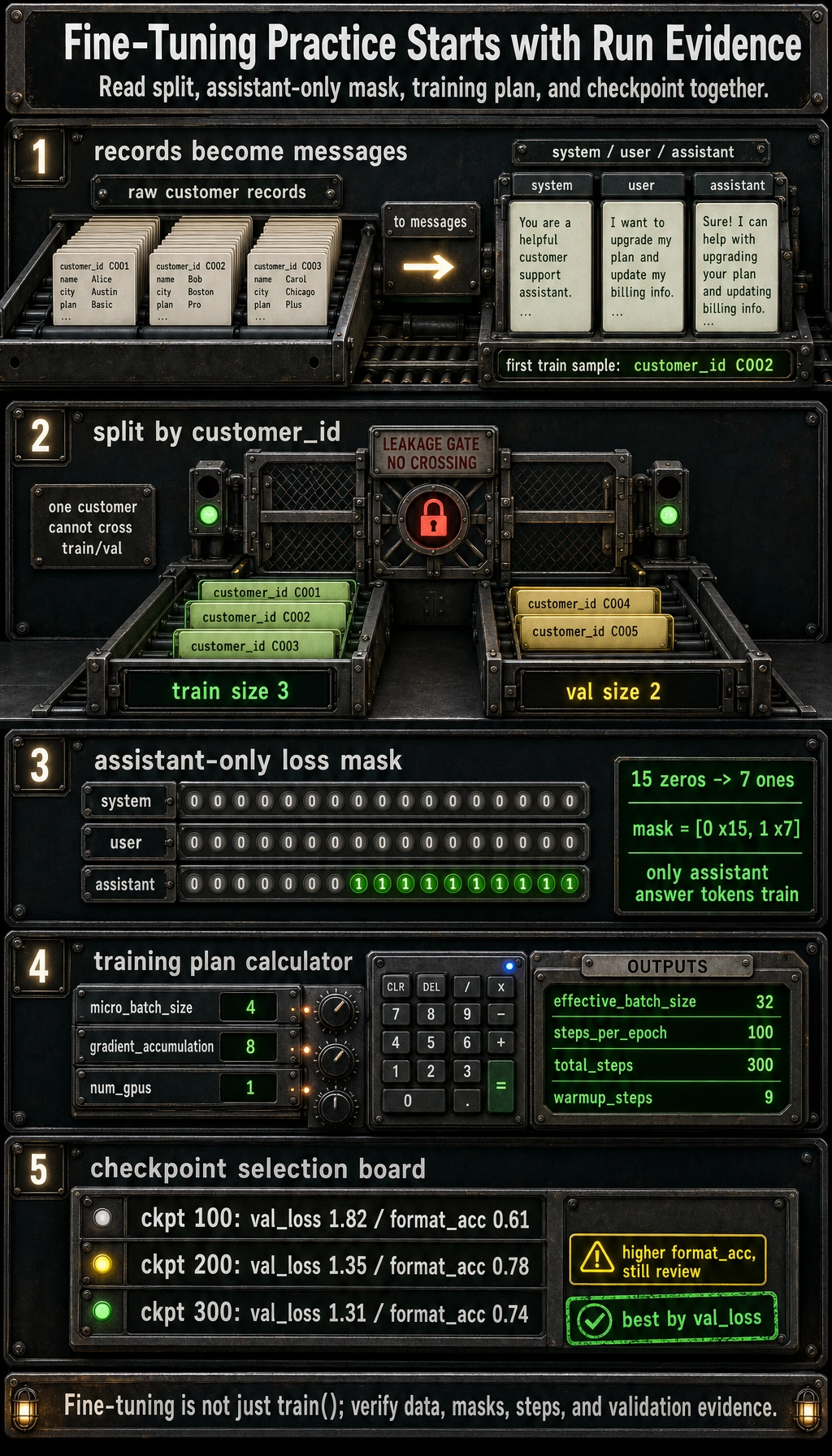
First, organize raw business data into training samples
The following example does three very practical things:
- Convert raw customer service records into
messagesformat - Split the training and validation sets by
customer_id - Avoid having the same customer appear in both sets
import json
import random
random.seed(42)
raw_samples = [
{
"customer_id": "C001",
"question": "I already paid for the order. Can I request a refund?",
"answer": "Yes, you can request a refund. Please first confirm the order status. If it has already been shipped, you will need to go through the after-sales process.",
},
{
"customer_id": "C001",
"question": "How long does a refund usually take to arrive?",
"answer": "Refunds to the original payment method usually take 3 to 7 business days, depending on the payment provider.",
},
{
"customer_id": "C002",
"question": "I forgot my password. How can I log in again?",
"answer": "Please click “Forgot Password” on the login page and follow the SMS or email instructions to reset it.",
},
{
"customer_id": "C003",
"question": "I entered the wrong shipping address. Can I still change it?",
"answer": "If the order has not yet been shipped, you can change the address on the order details page; if it has already been shipped, please contact human support.",
},
{
"customer_id": "C004",
"question": "When can I issue an invoice?",
"answer": "After the order is completed, you can request an invoice in the invoice center. The e-invoice will be sent to the email address you provided.",
},
]
def to_chat_record(row):
system_prompt = "You are an e-commerce customer service assistant. Please provide polite, accurate replies that follow platform policy."
return {
"customer_id": row["customer_id"],
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": row["question"]},
{"role": "assistant", "content": row["answer"]},
],
}
def split_by_customer(records, train_ratio=0.8):
customer_ids = sorted({row["customer_id"] for row in records})
random.shuffle(customer_ids)
split_point = max(1, int(len(customer_ids) * train_ratio))
train_ids = set(customer_ids[:split_point])
train_records = [row for row in records if row["customer_id"] in train_ids]
val_records = [row for row in records if row["customer_id"] not in train_ids]
return train_records, val_records
chat_records = [to_chat_record(row) for row in raw_samples]
train_records, val_records = split_by_customer(chat_records)
print("train size =", len(train_records))
print("val size =", len(val_records))
print("first train example:")
print(json.dumps(train_records[0], ensure_ascii=False, indent=2))
Expected output:
train size = 3
val size = 2
first train example:
{
"customer_id": "C002",
"messages": [
{
"role": "system",
"content": "You are an e-commerce customer service assistant. Please provide polite, accurate replies that follow platform policy."
},
{
"role": "user",
"content": "I forgot my password. How can I log in again?"
},
{
"role": "assistant",
"content": "Please click “Forgot Password” on the login page and follow the SMS or email instructions to reset it."
}
]
}
Why does this code have engineering value?
Because it corresponds to the very first real step in fine-tuning:
- Raw data is usually not in training format
- You need to organize it into a structure the model can consume
- When splitting data, you also need to avoid leakage from the same source
Many projects do not fail because the training method is wrong, but because they already plant problems at this layer.
Why split by customer instead of randomly?
Because random splitting may put different questions from the same customer into both training and validation.
This leads to:
- A validation score that looks great
- But the real generalization ability is overestimated
So the splitting unit should usually be as close as possible to the real generalization boundary, such as:
- User
- Session
- Document
- Ticket
- Product line
Read this as an engineering assembly line, not as a magic training button. A healthy fine-tuning project starts from task definition and baselines, then prepares leak-free data, trains with monitoring, deploys with canary and rollback, and turns failure cases into the next round of data.
Training format is not just “looks like a conversation”
During SFT training, we usually only want the model to be responsible for the assistant part
This is called:
- assistant-only loss
It means:
systemuser
These contents are conditional input and should not be trained as something the model should “memorize.”
The small function below is a simplified mask example:
messages = [
{"role": "system", "content": "You are a customer service assistant"},
{"role": "user", "content": "What should I do if I forgot my password?"},
{"role": "assistant", "content": "Please click Forgot Password to reset it"},
]
def build_loss_mask(messages):
mask = []
for message in messages:
token_count = len(message["content"].split())
value = 1 if message["role"] == "assistant" else 0
mask.extend([value] * token_count)
return mask
print(build_loss_mask(messages))
Expected output:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
This is not meant to reproduce a real tokenizer, but to help you understand:
During training, not all tokens should contribute to the loss.
In a real SFT pipeline, the tokenizer turns messages into token IDs, and the trainer usually builds a label mask. Tokens from system and user tell the model what condition it is under; tokens from assistant are the target behavior to learn. This is why assistant-only loss helps the model learn how to answer, instead of wasting training signal on copying the user question.
If the formatting rules are unstable, the model will learn “dirty patterns”
For example, in the same task:
- Some samples use
messages - Some samples use
question/answer - Some assistant responses start with a long greeting
- Some samples give the answer directly
This kind of inconsistency makes it hard for the model to form stable behavior.
So format consistency is critical:
- Consistent fields
- Consistent role order
- Consistent style
- Consistent ending format
Training plans should be calculated before training starts
Many people only realize during training that:
- The batch size is too small
- The number of steps is too few
- The warmup is strange
- Checkpoints are saved too frequently or too sparsely
The script below can help you estimate the training scale in advance.
from math import ceil
def build_training_plan(
num_train_examples,
micro_batch_size,
gradient_accumulation,
epochs,
num_gpus=1,
warmup_ratio=0.03,
):
effective_batch_size = micro_batch_size * gradient_accumulation * num_gpus
steps_per_epoch = ceil(num_train_examples / effective_batch_size)
total_steps = steps_per_epoch * epochs
warmup_steps = max(1, int(total_steps * warmup_ratio))
return {
"effective_batch_size": effective_batch_size,
"steps_per_epoch": steps_per_epoch,
"total_steps": total_steps,
"warmup_steps": warmup_steps,
}
plan = build_training_plan(
num_train_examples=3200,
micro_batch_size=4,
gradient_accumulation=8,
epochs=3,
num_gpus=1,
)
print(plan)
val_history = [
{"checkpoint": 100, "val_loss": 1.82, "format_acc": 0.61},
{"checkpoint": 200, "val_loss": 1.35, "format_acc": 0.78},
{"checkpoint": 300, "val_loss": 1.31, "format_acc": 0.74},
]
best = min(val_history, key=lambda item: (item["val_loss"], -item["format_acc"]))
print("best checkpoint =", best)
Expected output:
{'effective_batch_size': 32, 'steps_per_epoch': 100, 'total_steps': 300, 'warmup_steps': 9}
best checkpoint = {'checkpoint': 300, 'val_loss': 1.31, 'format_acc': 0.74}
Why should you pay special attention to effective batch size?
Because the number of samples the model actually sees for each parameter update is not just:
- Single-GPU batch size
It is:
micro_batch_size * gradient_accumulation * number of GPUs
This directly affects:
- Gradient stability
- Learning rate choice
- Total number of training steps
Why not look only at val_loss during validation?
Because business tasks often have more important metrics, such as:
- JSON format correctness
- Classification label accuracy
- Key information recall
- Human satisfaction
So when saving the best checkpoint, you should usually consider at least:
- General training metrics
- Business metrics
Training-plan terms that are easy to misread
| Term | What it means | Why it affects the project |
|---|---|---|
| Micro batch size | Number of samples processed by one device in one small forward/backward pass | Limited by GPU memory |
| Gradient accumulation | Accumulate gradients over several micro batches before one optimizer update | Lets you simulate a larger batch when memory is limited |
| Effective batch size | micro_batch_size * gradient_accumulation * num_gpus | It affects learning-rate choice and gradient stability |
| Warmup steps | Early steps where the learning rate gradually increases | Reduces instability at the beginning of training |
| Checkpoint | A saved model state at a certain training step | Lets you compare versions, resume training, or roll back |
| Canary traffic | Sending only a small portion of real traffic to the new model first | Reduces deployment risk before a full release |
What should you actually monitor during training?
First layer: Are the curves obviously abnormal?
For example:
- Loss does not decrease at all
- It explodes right from the start
- Learning rate scheduling is abnormal
- The validation set suddenly gets worse
These are “firefighting” problems.
Second layer: Has the model output drifted?
Pick 20 to 50 fixed samples, and review the outputs for each checkpoint.
Focus on whether:
- The model becomes overly verbose
- It starts hallucinating
- The format is unstable
- It forgets its original general ability
Third layer: Is there overfitting or catastrophic forgetting?
You will often see this:
- Training set keeps improving
- Validation improvement stalls
- General capabilities that used to work become worse
This usually means:
- The data distribution is too narrow
- Too many training epochs
- Learning rate is too high
- The sample style is too uniform
Catastrophic forgetting means the model improves on the narrow fine-tuning task but loses some broad abilities it used to have. A simple way to catch it is to keep a small “general ability check set,” such as summarization, reasoning, coding, and safety examples, and run it together with the task validation set after each important checkpoint.
The final layer to check before deployment
Passing offline evaluation does not mean you can deploy directly
Before real deployment, you should at least add:
- Canary traffic
- Manual spot checks
- Rollback plan
- Version records
What you need to record online is not only request logs
You also need to pay attention to:
- Which types of problems improved
- Which types of problems got worse
- Which input types are causing the new errors
This will directly become the source of data for your next iteration.
A fine-tuning project is not “one training run,” but a continuous iteration loop
The healthiest loop usually looks like this:
- Define the task
- Prepare the data
- Run a baseline
- Train and validate
- Deploy with canary traffic
- Collect failure cases
- Start the next round
The most common misconceptions
Misconception 1: Start by tuning training parameters
Starting with parameters usually means skipping the most important parts: task definition and data organization.
Misconception 2: More data is always better
Often, what matters more is:
- Whether the data matches the task
- Whether the style is consistent
- Whether it is representative
Misconception 3: The project ends when training ends
In real engineering practice, training completion is usually only a midpoint, not the finish line.
Summary
The most important thing in this lesson is not to memorize what a certain config file looks like, but to build a stable sequence:
First define the task clearly, then organize the data correctly, then calculate the splitting and training plan, and finally decide the version based on business metrics rather than just loss.
Once this sequence is stable, you can change the model, framework, or fine-tuning method later without losing engineering judgment.
Exercises
- Rewrite one real business task you have into a more specific “input-output-style-constraints” description.
- Refer to the code in this section and organize a raw question-answer dataset into
messagesformat. - Think about this: should your data be split by user, by session, or by document? Why?
- If the validation set has a lower
val_lossbut worse JSON format correctness, which checkpoint would you choose? Why?