11 NLP Specialization: Text Tasks After LLMs
This specialization comes after the LLM/RAG/Agent main line. Chapter 7 already gives you the minimum NLP crash course; Chapter 11 is where you return when a real product needs cleaner labels, better extraction, stronger evaluation, or a text pipeline that an LLM alone cannot make reliable.
The guiding question is: how does raw text become something a model can classify, extract, search, or generate from? LLMs hide many NLP steps, but Prompt, RAG, Agent memory, retrieval, evaluation, and information extraction still depend on NLP thinking.
If you are following the fastest beginner route, finish Chapters 1-9 first, then come back here for a text-focused portfolio project.
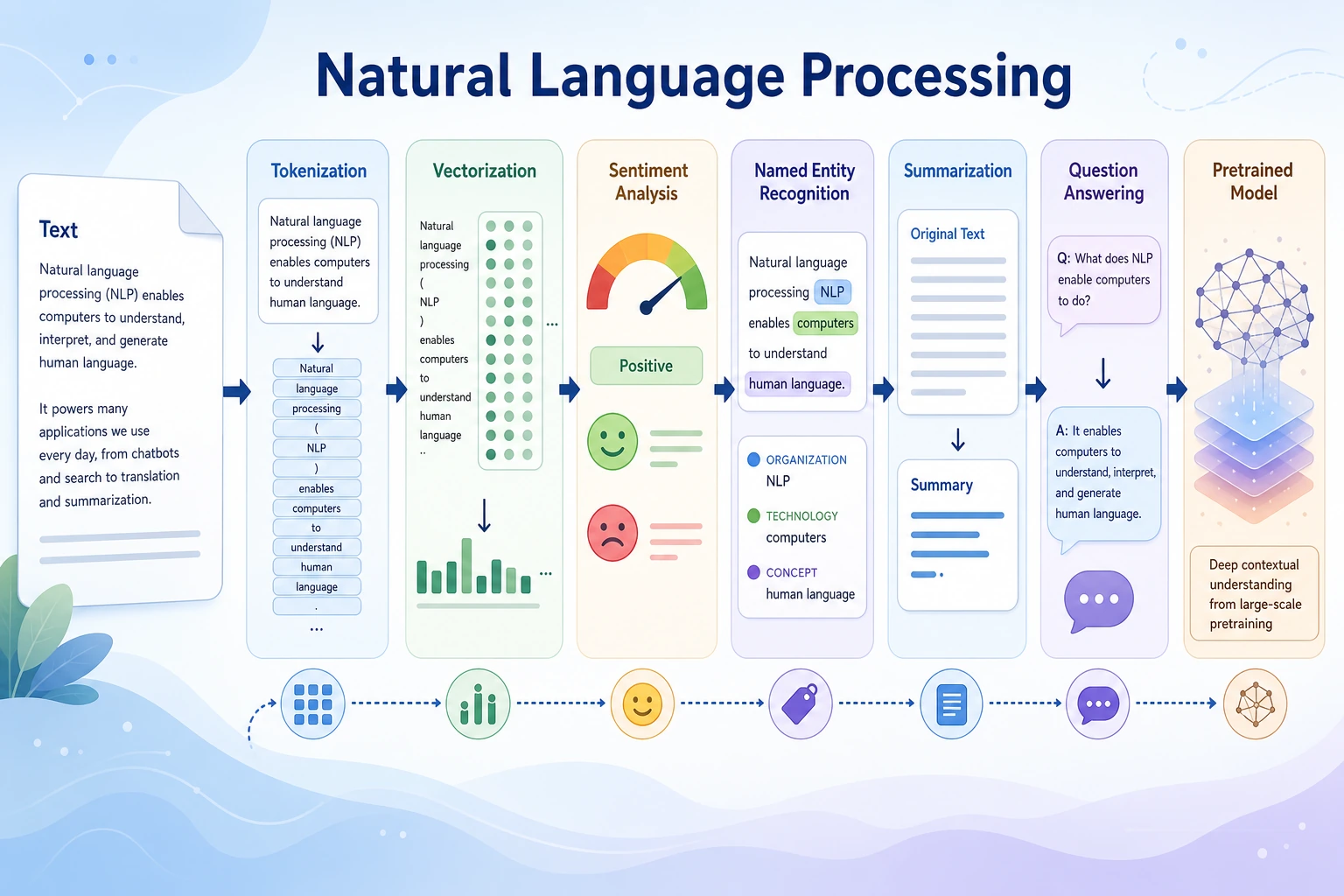
See the Text-To-Task Pipeline
Section titled “See the Text-To-Task Pipeline”
Use this as the chapter map.
| Step | What happens | Practical check |
|---|---|---|
| Raw text | user reviews, logs, documents, chat, contracts | What is the source and language? |
| Cleaning | normalize casing, punctuation, special characters | Did cleaning remove important meaning? |
| Tokenization | split text into words, subwords, or tokens | Are domain terms split correctly? |
| Representation | BoW, TF-IDF, embedding, contextual vector | Which representation fits the task and data size? |
| Task output | label, entity, summary, answer, retrieval result | Is the output schema clear? |
| Evaluation | metric, error sample, factual check | Can failures be reviewed? |
Learning Order And Task List
Section titled “Learning Order And Task List”First understand the text workflow, then study model families.
| Step | Read | Do | Evidence to keep |
|---|---|---|---|
| 11.1 | Text basics and preprocessing | clean, tokenize, normalize, inspect examples | cleaning script and before/after samples |
| 11.2 | Embeddings and language models | compare BoW, TF-IDF, embeddings, contextual meaning | representation notes |
| 11.3 | Text classification | build a small label task | label guide, metrics, errors |
| 11.4 | Sequence labeling | understand NER and token-level fields | entity examples and boundary cases |
| 11.5 | Seq2Seq and attention | understand generation and translation history | summary or translation notes |
| 11.6 | Pretrained models | compare BERT, GPT, T5, Transformers usage | model choice note |
| 11.7 | Stage project | run 11.7.6 Hands-on: Build a Reproducible NLP Mini Pipeline | data files, metrics, extraction outputs, failure report |
First Runnable Loop: Labels, Rules, And Evaluation
Section titled “First Runnable Loop: Labels, Rules, And Evaluation”This zero-dependency script is intentionally simple. It teaches the core NLP project habit: define labels, predict on fixed samples, and save errors.
Create ch11_text_eval.py and run it with Python 3.10 or later.
samples = [ {"text": "RAG failed to retrieve the correct document", "expected": "retrieval"}, {"text": "The JSON output is missing a required field", "expected": "format"}, {"text": "The answer sounds fluent but cites no source", "expected": "citation"},]
rules = { "retrieval": ["retrieve", "document", "chunk"], "format": ["json", "field", "schema"], "citation": ["cite", "source", "evidence"],}
def predict_label(text: str) -> str: text = text.lower() scores = { label: sum(keyword in text for keyword in keywords) for label, keywords in rules.items() } return max(scores, key=scores.get)
correct = 0for row in samples: pred = predict_label(row["text"]) ok = pred == row["expected"] correct += int(ok) print(f"pred={pred:<9} expected={row['expected']:<9} ok={ok} text={row['text']}")
print(f"accuracy={correct}/{len(samples)}")Expected output:
pred=retrieval expected=retrieval ok=True text=RAG failed to retrieve the correct documentpred=format expected=format ok=True text=The JSON output is missing a required fieldpred=citation expected=citation ok=True text=The answer sounds fluent but cites no sourceaccuracy=3/3Operation tip: add a confusing sample such as “the document source field is missing.” If the rule system fails, write down whether the problem is label overlap, keyword coverage, or unclear task definition. The same thinking applies when you later use BERT, GPT, or an LLM.
How to read this output
Section titled “How to read this output”- Each line compares
predwithexpected, so you can inspect errors one sample at a time. ok=Truemeans the current rule worked for that sample; it does not prove the task is solved.accuracy=3/3is only a baseline on three examples. Add boundary cases before trusting it.- The most valuable artifact is the failure note: why a confusing text was classified into the wrong label.
Depth Ladder
Section titled “Depth Ladder”| Level | What you can prove |
|---|---|
| Minimum pass | You can run label and rule evaluation on fixed text samples and explain why one confusing sample fails. |
| Project-ready | You can define labels or fields, choose representation and output, keep metrics, and save boundary and failure cases. |
| Deeper check | You can decide whether rules, classical NLP, embeddings, fine-tuning, RAG, or an LLM is the simplest reliable option. |
Choose The NLP Task By Output
Section titled “Choose The NLP Task By Output”
Do not choose a model before you know the output.
| Desired output | Task | What to evaluate |
|---|---|---|
| one category per text | classification | accuracy, F1, confusion matrix |
| entities or fields | extraction / sequence labeling | precision, recall, field validity |
| new text based on source | summarization / generation | factual consistency, coverage, citations |
| answer from documents | QA / retrieval | hit rate, answer quality, source support |
| model behavior comparison | pretrained model experiment | quality, cost, latency, data requirement |
Evidence to Keep
Section titled “Evidence to Keep”Keep this page’s proof of learning as a small evidence card:
- Task Output
- label, entity fields, summary, answer, retrieval result, or semantic graph
- Artifacts
- raw text, processed text, predictions, metrics, and failure cases
- Metric
- accuracy/F1, precision/recall, retrieval hit rate, faithfulness, or schema validity
- Failure Check
- unclear labels, over-cleaning, boundary errors, hallucination, or unsupported answer
- Expected Output
- reproducible text pipeline folder with metrics and examples
Common Failures
Section titled “Common Failures”- Jumping to LLMs before defining labels or fields.
- Cleaning text so aggressively that meaning is lost.
- Mixing classification, extraction, retrieval, and generation outputs.
- Evaluating generated summaries only by fluency, not factual consistency.
- Reporting metrics without error samples or boundary cases.
Pass Check
Section titled “Pass Check”Before leaving this elective, you should be able to:
- explain cleaning, tokenization, representation, task output, and evaluation;
- run the text evaluation script and add at least one confusing sample;
- write label definitions, field schema, boundary cases, and failure examples;
- choose classification, extraction, summarization, QA, retrieval, or pretrained-model comparison by output type;
- run the reproducible NLP mini pipeline and keep metrics plus failure cases.
For a printable checklist, use 11.0 Learning Checklist. For the guided project, start with 11.7.6 Hands-on: Build a Reproducible NLP Mini Pipeline.
Check reasoning and explanation
- A passing answer starts from the text unit and output type: token, span, sentence label, sequence, embedding, or generated text.
- The evidence should include a small dataset example, model or pipeline choice, metric, and at least one inspected error case.
- A good self-check distinguishes preprocessing issues from model issues, such as tokenization mistakes, label ambiguity, data imbalance, or hallucinated generation.