11.6.1 Pretrained Models Roadmap: BERT, GPT, T5
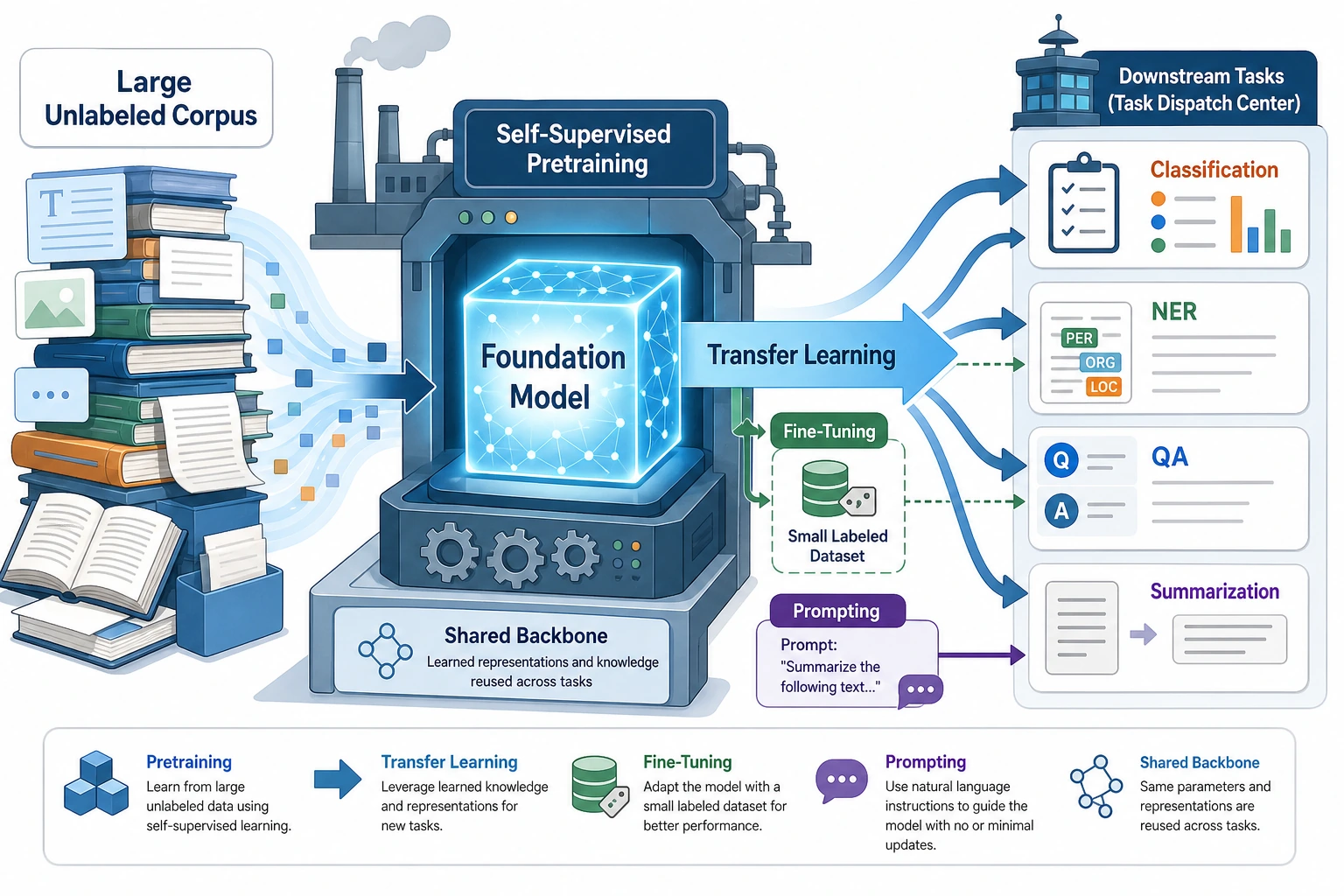
Pretrained models move NLP from one-task training to a reusable foundation: pretrain on large text, then transfer to downstream tasks.
See the Paradigm Map First
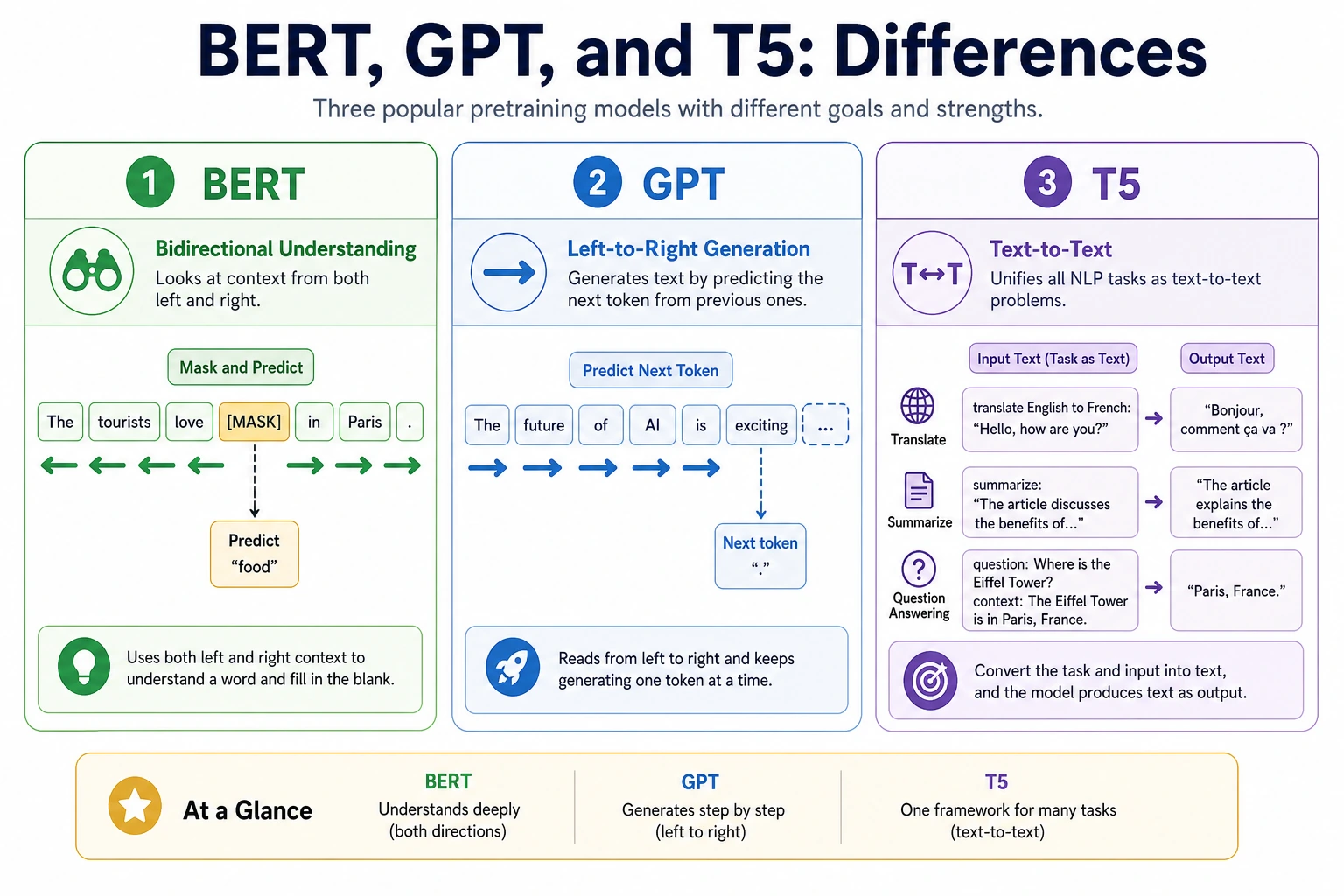
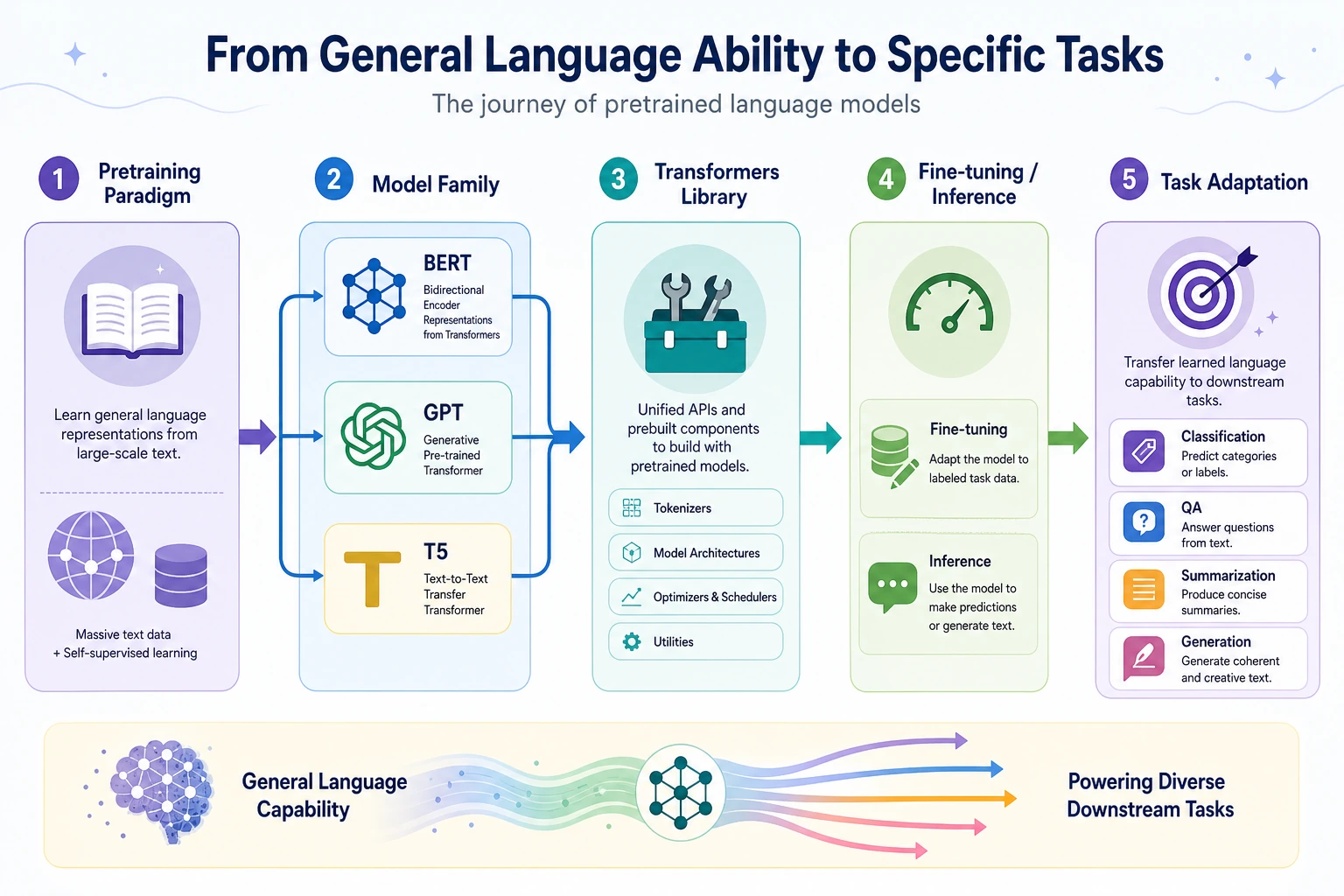
BERT emphasizes understanding, GPT emphasizes generation, and T5 rewrites many tasks into text-to-text form.
Run a Model Family Choice Check
task = {
"needs_generation": True,
"needs_sentence_label": False,
"needs_text_to_text": True,
}
if task["needs_text_to_text"]:
family = "T5-style text-to-text"
elif task["needs_generation"]:
family = "GPT-style autoregressive"
else:
family = "BERT-style understanding"
print("family:", family)
print("reason:", "match model objective to task output")
Expected output:
family: T5-style text-to-text
reason: match model objective to task output
Do not choose by model name alone. Match tokenizer, objective, output format, cost, and deployment constraints.
Learn in This Order
| Step | Read | Practice Output |
|---|---|---|
| 1 | Pretraining paradigm | Explain pretrain → transfer → fine-tune/infer |
| 2 | BERT | Understand mask prediction and bidirectional representations |
| 3 | GPT | Understand next-token generation and context window |
| 4 | T5 | Rewrite tasks into text-to-text form |
| 5 | Transformers practice | Connect tokenizer, model, pipeline, input, output |
Pass Check
You pass this chapter when you can explain why different objectives create different strengths, and run or design one small pretrained-model comparison experiment.