11.2.1 Representation Roadmap: Meaning as Vectors
Representation learning asks how text can become numbers that carry meaning, not just identity.
See the Representation Path First
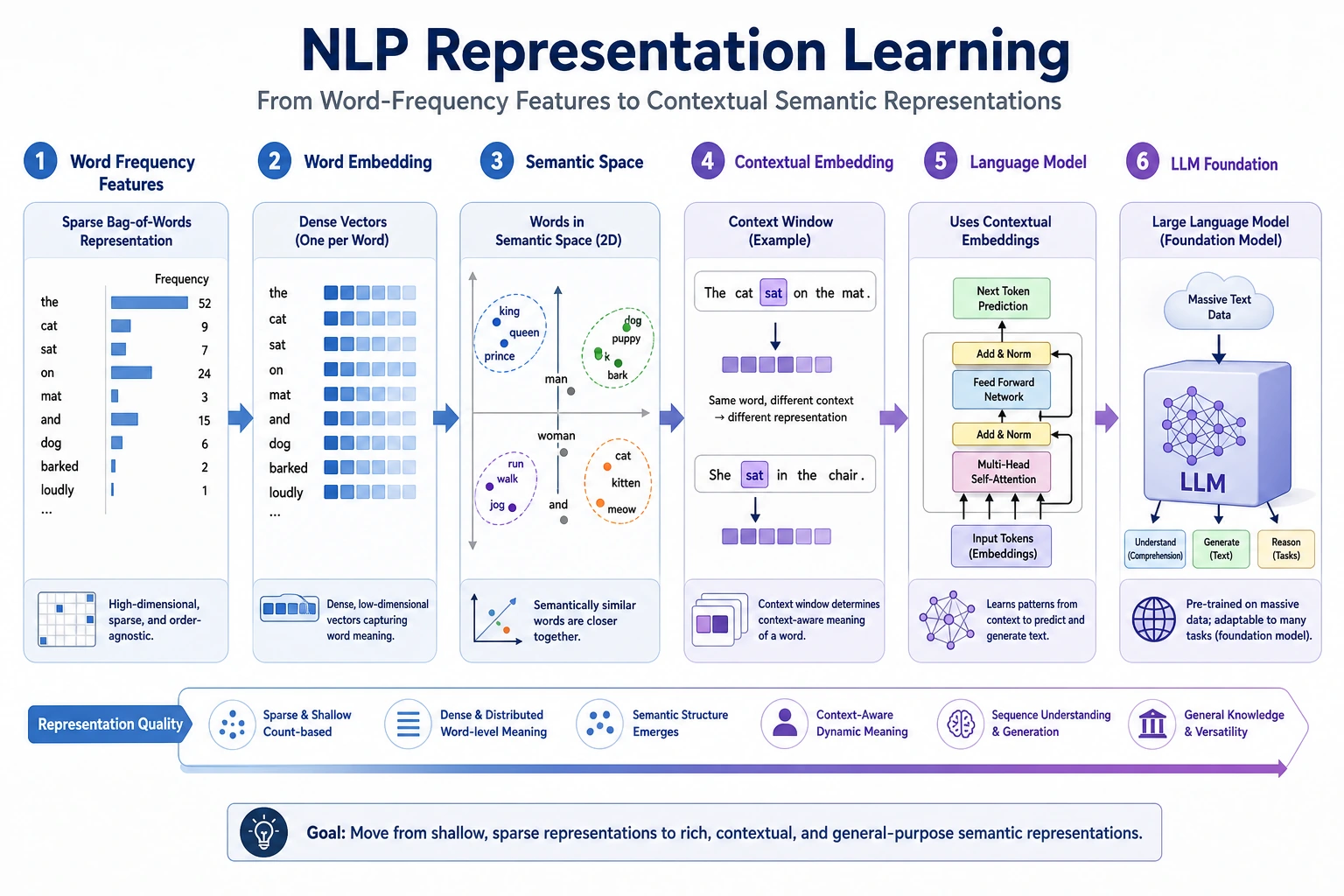
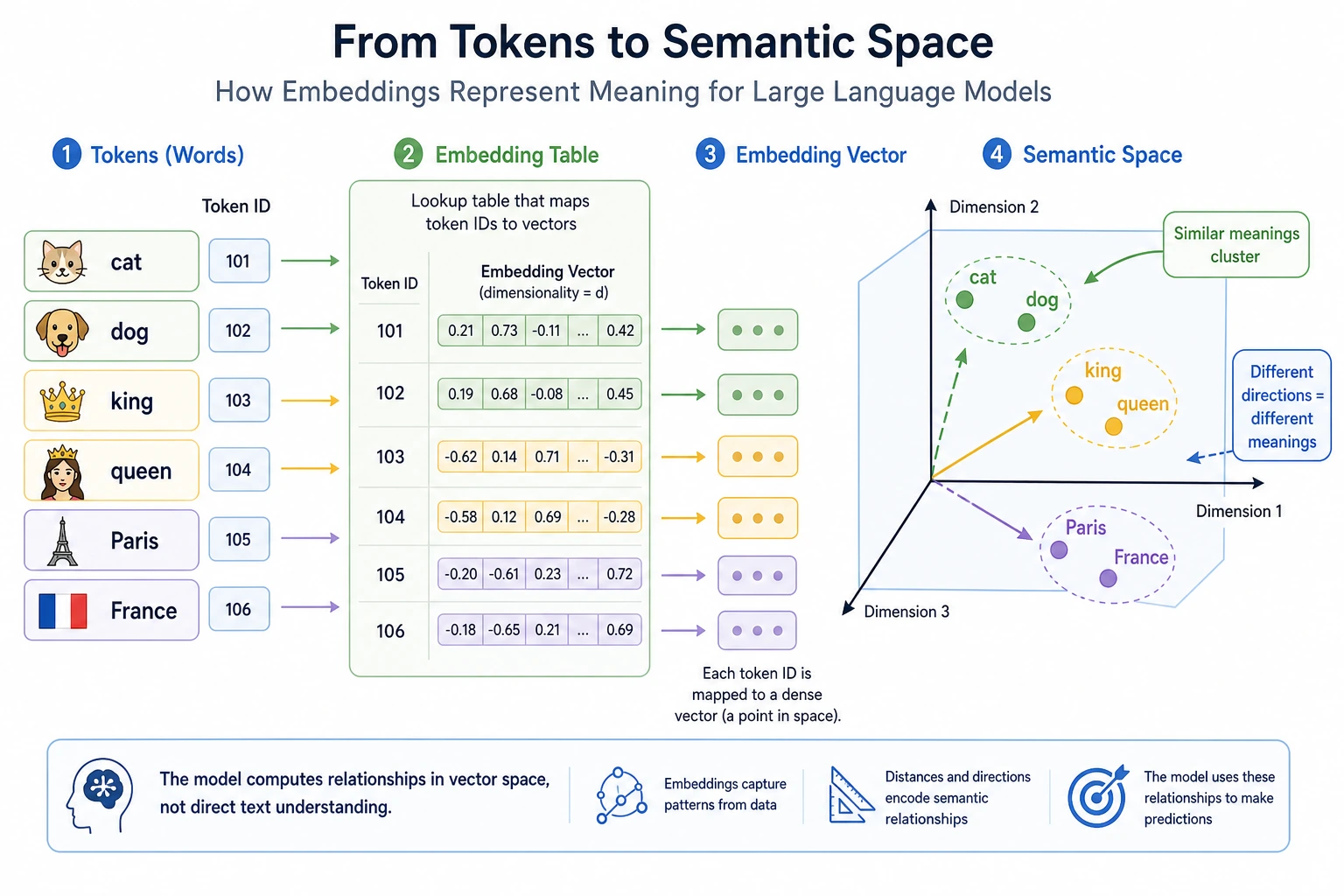
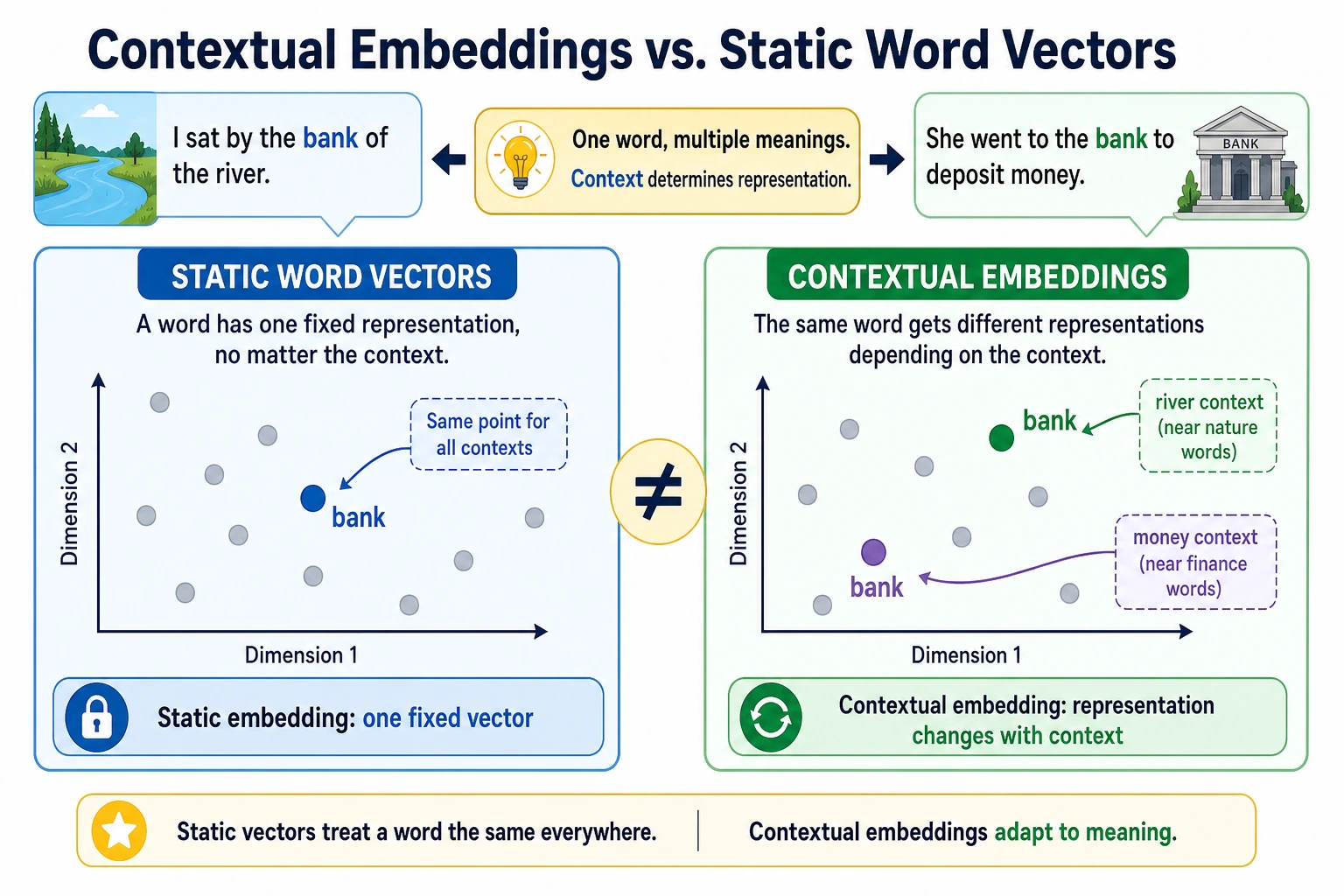
The path moves from sparse word identity, to word vectors, to contextual vectors, to language models that learn broader language patterns.
Run a Similarity Check
vectors = {
"cat": [1.0, 0.8],
"dog": [0.9, 0.7],
"car": [0.1, 0.2],
}
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
print("cat_dog:", round(dot(vectors["cat"], vectors["dog"]), 2))
print("cat_car:", round(dot(vectors["cat"], vectors["car"]), 2))
Expected output:
cat_dog: 1.46
cat_car: 0.26
This is a toy score, but it shows the core idea: close meanings should be easier for a model to compare.
Learn in This Order
| Step | Read | Practice Output |
|---|---|---|
| 1 | Word embeddings | Explain semantic closeness as vector closeness |
| 2 | Contextual representations | Explain why the same word can mean different things |
| 3 | Language models | Connect representation learning to next-token or masked prediction |
Pass Check
You pass this chapter when you can compare sparse features, word embeddings, and contextual embeddings, and explain why representation quality affects classification, retrieval, and RAG.