11.5.1 Seq2Seq Roadmap: Input Sequence to Output Sequence
Seq2Seq handles tasks where both input and output are sequences: translation, summarization, rewriting, dialogue, and error correction.
See the Generation Bridge First
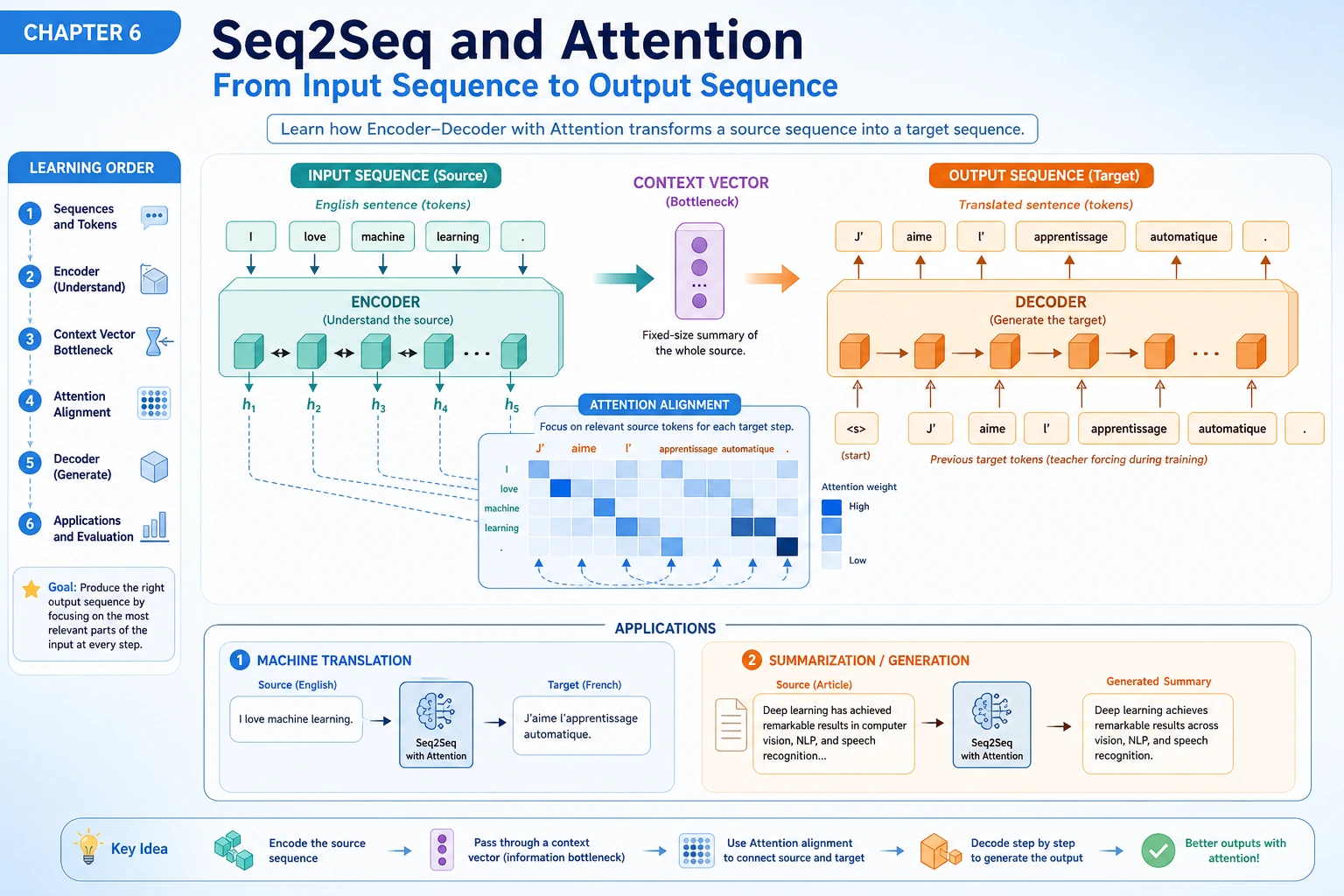
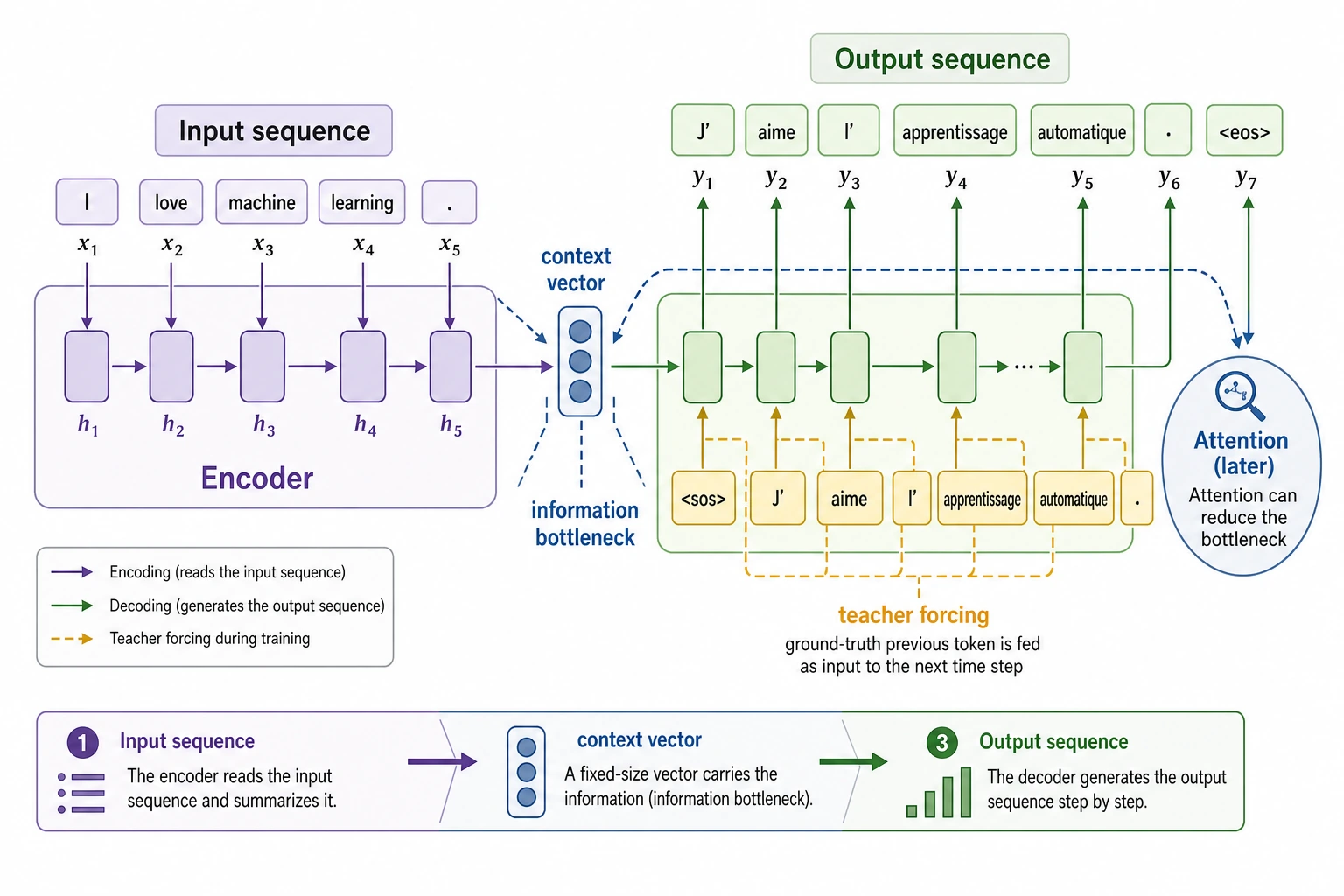
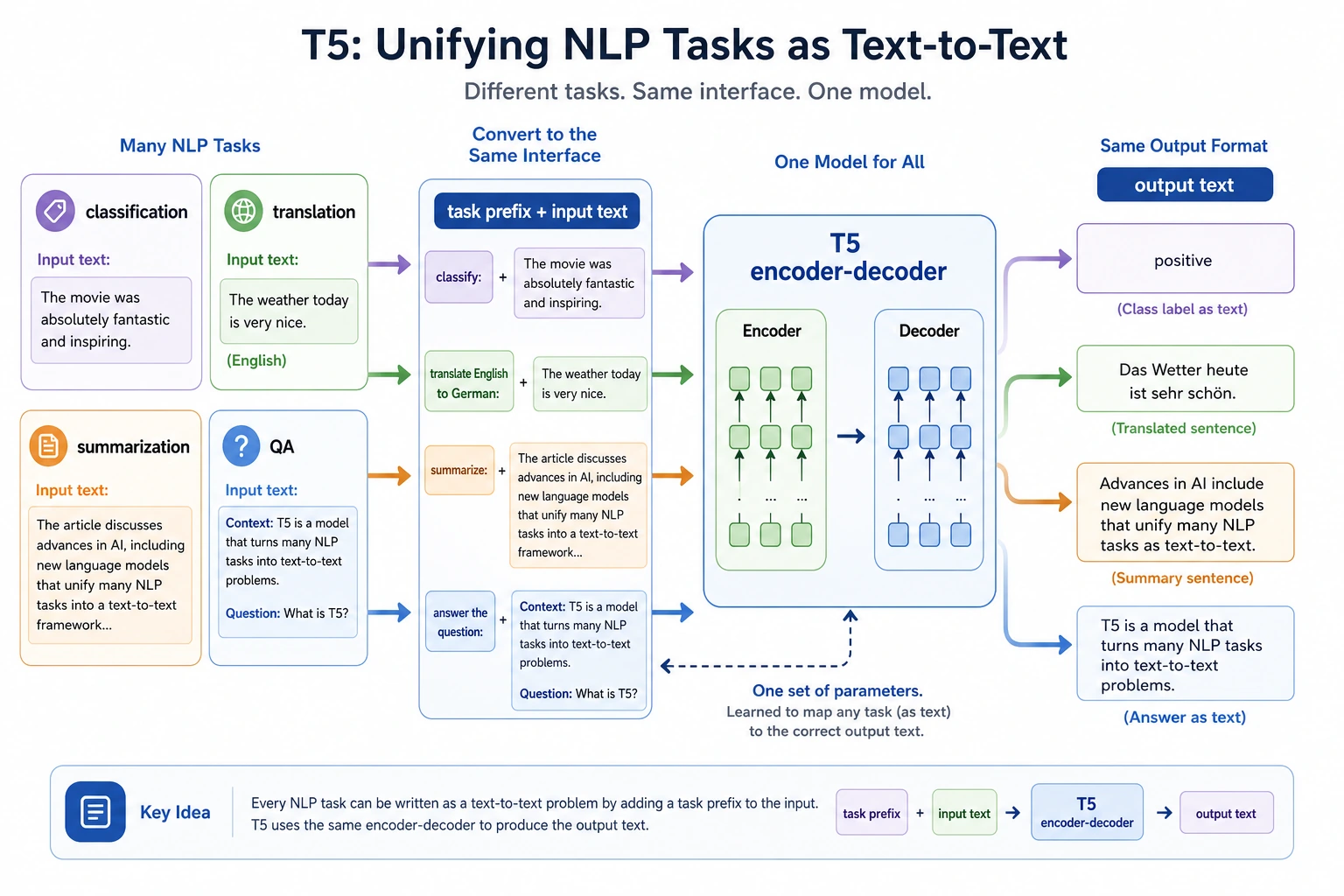
The bridge to modern LLMs is clear: generation happens step by step, and attention helps the decoder look back at useful input positions.
Run an Input-Output Pair Check
source = ["I", "love", "NLP"]
target = ["J'aime", "le", "NLP"]
for step, token in enumerate(target, start=1):
print(f"decode_step_{step}:", token)
print("source_length:", len(source))
print("target_length:", len(target))
Expected output:
decode_step_1: J'aime
decode_step_2: le
decode_step_3: NLP
source_length: 3
target_length: 3
Generation projects should record decoding strategy, failure cases, and whether important input information was lost.
Learn in This Order
| Step | Read | Practice Output |
|---|---|---|
| 1 | Encoder-Decoder | Explain why input and output can have different lengths |
| 2 | Attention | Explain dynamic alignment during generation |
| 3 | Machine translation | Connect teacher forcing, decoding, BLEU/error analysis |
| 4 | CTC and speech | See what changes when input/output are not frame-aligned |
Pass Check
You pass this chapter when you can explain encoder-decoder, attention, greedy/beam decoding, and one generation failure.