11.1.4 Text Representation Methods
Learning Objectives
By the end of this section, you will be able to:
- Understand why text must first be represented as numbers
- Master the basic ideas behind one-hot, bag of words, and TF-IDF
- Write a simple text vectorization example
- Understand the differences between traditional representations and embedding
How this section connects to the earlier text fundamentals track
If you just finished the NLP task map and preprocessing, the most natural next step is this:
- Earlier, you learned that text must first be tokenized, cleaned, and organized
- This section starts solving the next question: after organizing it, how do we turn text into numbers that models can work with?
So what really matters in this section is not the names of several vectorization methods, but this:
- Once the representation changes, the entire task pipeline that follows changes too
Why must text be converted to numbers?
Models cannot directly understand the text itself, such as “refund policy” or “I like this course.” They can only process numbers.
So in NLP there is one unavoidable step:
Convert text into vectors.
This process is called:
- text representation
- or vectorization
When learning NLP representations for the first time, what should you focus on first?
What you should focus on first is not the names one-hot / BoW / TF-IDF, but this sentence:
The model ultimately consumes numbers, and the representation method determines whether the model can actually see useful information.
Once this idea is solid, when you look at each representation method, you will naturally ask:
- What does it preserve?
- What does it lose?
one-hot: the most basic representation
Suppose the vocabulary has only 4 words:
vocab = ["i", "love", "nlp", "python"]
print(vocab)
Expected output:
['i', 'love', 'nlp', 'python']
Then each word can be represented by a vector with a single 1:
i->[1, 0, 0, 0]love->[0, 1, 0, 0]nlp->[0, 0, 1, 0]python->[0, 0, 0, 1]
Advantages of one-hot
- Simple
- Explicit
Limitations of one-hot
- The dimensionality becomes very high
- There is no semantic relationship between words
For example, love and like are not any closer in one-hot space.
What is the most important thing to remember about one-hot, beyond “simple”?
It is this:
- It can tell the model whether two tokens are the same word
- But it tells the model almost nothing about how words relate to one another
This is also why we naturally move on to:
- bag of words
- TF-IDF
- embedding
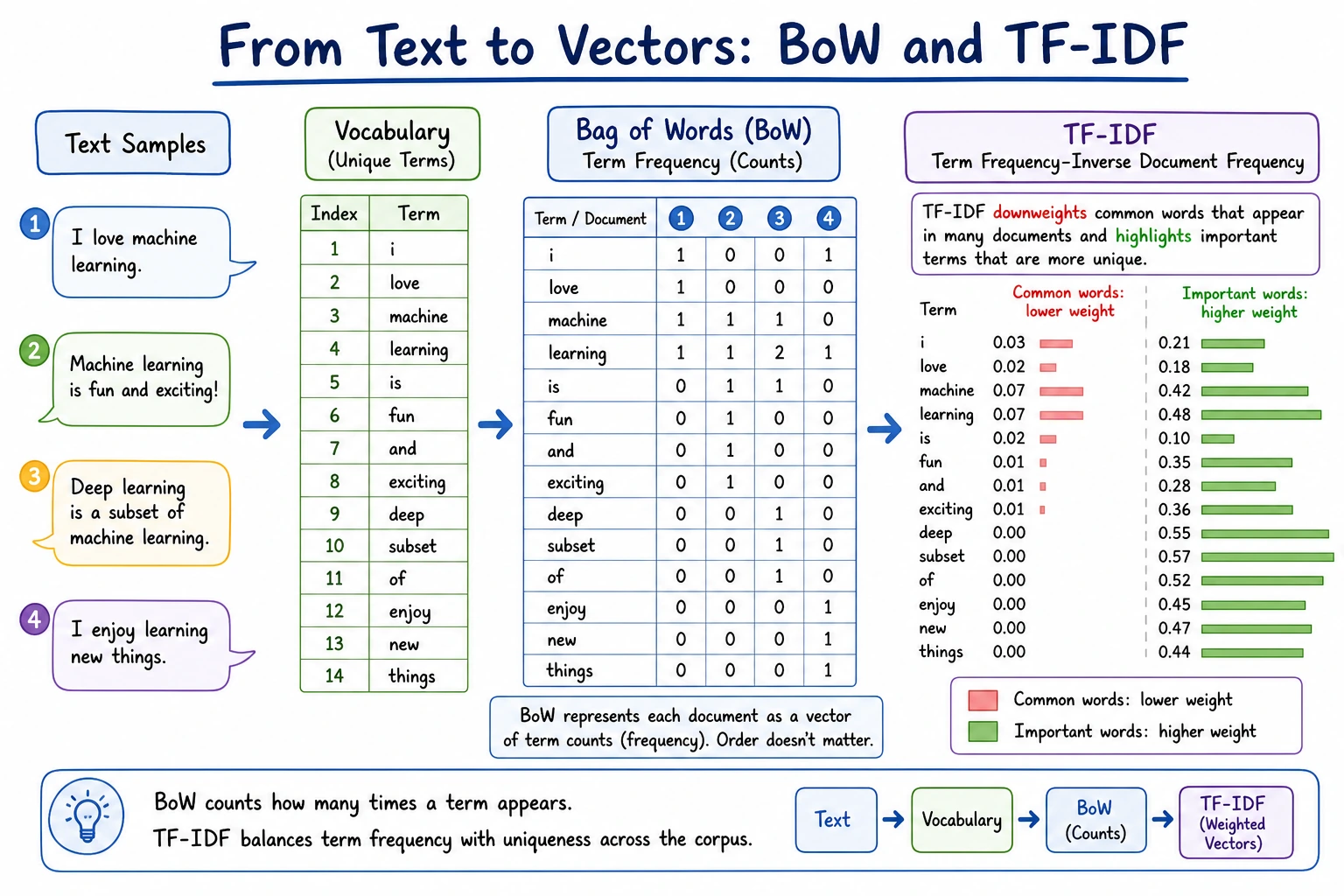
Bag of Words (BoW)
The core idea of bag of words is very straightforward:
Ignore word order and only count how many times each word appears.
Here is a minimal example.
from collections import Counter
docs = [
"i love nlp",
"i love python",
"python love me",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
vocab_index = {word: idx for idx, word in enumerate(vocab)}
def to_bow_vector(tokens):
vector = [0] * len(vocab)
counts = Counter(tokens)
for word, count in counts.items():
vector[vocab_index[word]] = count
return vector
print("Vocabulary:", vocab)
for doc, tokens in zip(docs, tokenized_docs):
print(doc, "->", to_bow_vector(tokens))
Expected output:
Vocabulary: ['i', 'love', 'me', 'nlp', 'python']
i love nlp -> [1, 1, 0, 1, 0]
i love python -> [1, 1, 0, 0, 1]
python love me -> [0, 1, 1, 0, 1]
Each position in the vector corresponds to one vocabulary item. The number tells you how many times that word appears in the document.
What is the intuition behind this representation?
It turns a sentence into:
- a fixed-length numeric vector
That way, downstream classifiers can process it.
What is its limitation?
It ignores order. For example:
- “dog bites man”
- “man bites dog”
These may look very similar in bag-of-words representation, but their meanings are completely different.
Why is bag of words still important, even though it is “rough”?
Because it helps you build an important first intuition:
- Text can first be converted into a fixed-length vector
- Then it can be handed to traditional models for classification, retrieval, and clustering
So the teaching value of bag of words is very high. It gives you the first real minimal entry point for seeing how text goes into a model.
TF-IDF: give higher weight to more discriminative words
Bag of words only counts occurrences, but many high-frequency words do not provide much discriminative power.
For example in English:
- the
- is
- and
So the idea behind TF-IDF is:
- Words that appear frequently in the current document are more important
- But if a word is very common across all documents, its importance should be discounted
A simple pure Python TF-IDF example
import math
from collections import Counter
docs = [
"python is great for data analysis",
"python is great for machine learning",
"basketball is a great sport",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
def compute_idf(tokenized_docs, vocab):
n_docs = len(tokenized_docs)
idf = {}
for word in vocab:
df = sum(1 for doc in tokenized_docs if word in doc)
idf[word] = math.log((n_docs + 1) / (df + 1)) + 1
return idf
idf = compute_idf(tokenized_docs, vocab)
def to_tfidf(tokens, vocab, idf):
counts = Counter(tokens)
total = len(tokens)
vector = []
for word in vocab:
tf = counts[word] / total
vector.append(round(tf * idf[word], 4))
return vector
print("Vocabulary:", vocab)
for doc, tokens in zip(docs, tokenized_docs):
print(doc)
print(to_tfidf(tokens, vocab, idf))
Expected output:
Vocabulary: ['a', 'analysis', 'basketball', 'data', 'for', 'great', 'is', 'learning', 'machine', 'python', 'sport']
python is great for data analysis
[0.0, 0.2822, 0.0, 0.2822, 0.2146, 0.1667, 0.1667, 0.0, 0.0, 0.2146, 0.0]
python is great for machine learning
[0.0, 0.0, 0.0, 0.0, 0.2146, 0.1667, 0.1667, 0.2822, 0.2822, 0.2146, 0.0]
basketball is a great sport
[0.3386, 0.0, 0.3386, 0.0, 0.0, 0.2, 0.2, 0.0, 0.0, 0.0, 0.3386]
Common words such as is and great still appear, but words that distinguish a document, such as basketball or analysis, receive stronger weights in their own documents.
The most important intuition behind TF-IDF
It lowers the weight of words that are common everywhere, and boosts the weight of words that are especially representative in the current text.
When learning TF-IDF for the first time, what is the most important question to ask?
The most important question is:
- Which words are just common noise?
- Which words are more discriminative for the current text?
Once you think this way, it becomes much easier to understand that TF-IDF is not just “more complicated counting,” but rather:
- discriminative weighting
After vectorization, text can be compared by similarity
The most common method is:
- cosine similarity
You can think of it simply as:
How similar the directions of two vectors are.
import math
from collections import Counter
docs = [
"i love python",
"i love coding",
"weather is sunny",
]
tokenized_docs = [doc.split() for doc in docs]
vocab = sorted(set(token for doc in tokenized_docs for token in doc))
vocab_index = {word: idx for idx, word in enumerate(vocab)}
def to_bow(tokens):
vector = [0] * len(vocab)
counts = Counter(tokens)
for word, count in counts.items():
vector[vocab_index[word]] = count
return vector
def cosine_similarity(a, b):
dot = sum(x * y for x, y in zip(a, b))
norm_a = math.sqrt(sum(x * x for x in a))
norm_b = math.sqrt(sum(y * y for y in b))
if norm_a == 0 or norm_b == 0:
return 0.0
return dot / (norm_a * norm_b)
vec1 = to_bow(tokenized_docs[0])
vec2 = to_bow(tokenized_docs[1])
vec3 = to_bow(tokenized_docs[2])
print("Sentence 1 vs Sentence 2:", round(cosine_similarity(vec1, vec2), 4))
print("Sentence 1 vs Sentence 3:", round(cosine_similarity(vec1, vec3), 4))
Expected output:
Sentence 1 vs Sentence 2: 0.6667
Sentence 1 vs Sentence 3: 0.0
The first two sentences share i and love, so their vectors point in a more similar direction. The weather sentence shares no vocabulary with the first sentence, so its similarity is 0.0.
This example will usually show:
i love pythonandi love codingare closer- both are farther from
weather is sunny
What is the difference between traditional representations and embedding?
Traditional representations
For example:
- one-hot
- BoW
- TF-IDF
Advantages:
- Simple
- Interpretable
Limitations:
- Limited semantic expressiveness
- Not sensitive to context
Why do we have to bring embedding in at the end of this section?
Because this is exactly where the main track of Chapter 11 Natural Language Processing truly starts to rise:
- Traditional representations are more like “counting occurrences”
- Embedding begins to move into the “semantic space”
So this section is actually building a bridge for the later chapter on representation learning:
- First, let you clearly see the value of traditional representations
- Then, naturally help you realize why they are not enough
Embedding
The core goal of embedding is:
- Make semantically similar words closer together in vector space
That is why later we will continue learning:
- word embeddings
- contextual representations
Common misconceptions
Misconception 1: one-hot is too simple, so there is no need to learn it
It is very important, because it helps you understand the idea that “text must first be converted into numbers.”
Misconception 2: TF-IDF is definitely outdated
In many traditional text classification and retrieval baselines, it is still very valuable.
Misconception 3: once you have vectors, you understand semantics
Vectorization is only the beginning. After that, you still need to look at:
- the quality of semantic representation
- context modeling
Summary
The most important thing in this section on text representation is to build a very basic but crucial judgment:
Machines cannot read text directly, so NLP must first convert text into numerical representations; the differences between representation methods determine how much information the model can use later.
This is also why the path from one-hot, BoW, and TF-IDF all the way to embedding and language models is actually a very natural evolution.
What you should take away from this section
- Representation methods are not small tricks, but the entry layer of NLP
- one-hot / BoW / TF-IDF evolve from “identity” to “statistical discriminative power”
- embedding will become the turning point that truly leads into semantic representation and the pretraining track later on
Exercises
- Add 2 more sentences to
docsyourself, and observe the BoW and TF-IDF vectors again. - Why does the bag-of-words model ignore word order?
- Explain in your own words: why does TF-IDF lower the weight of overly common words?
- Think about it: if a task depends heavily on word order, what problems would you encounter using only BoW or TF-IDF?