11.2.4 Fundamentals of Language Models
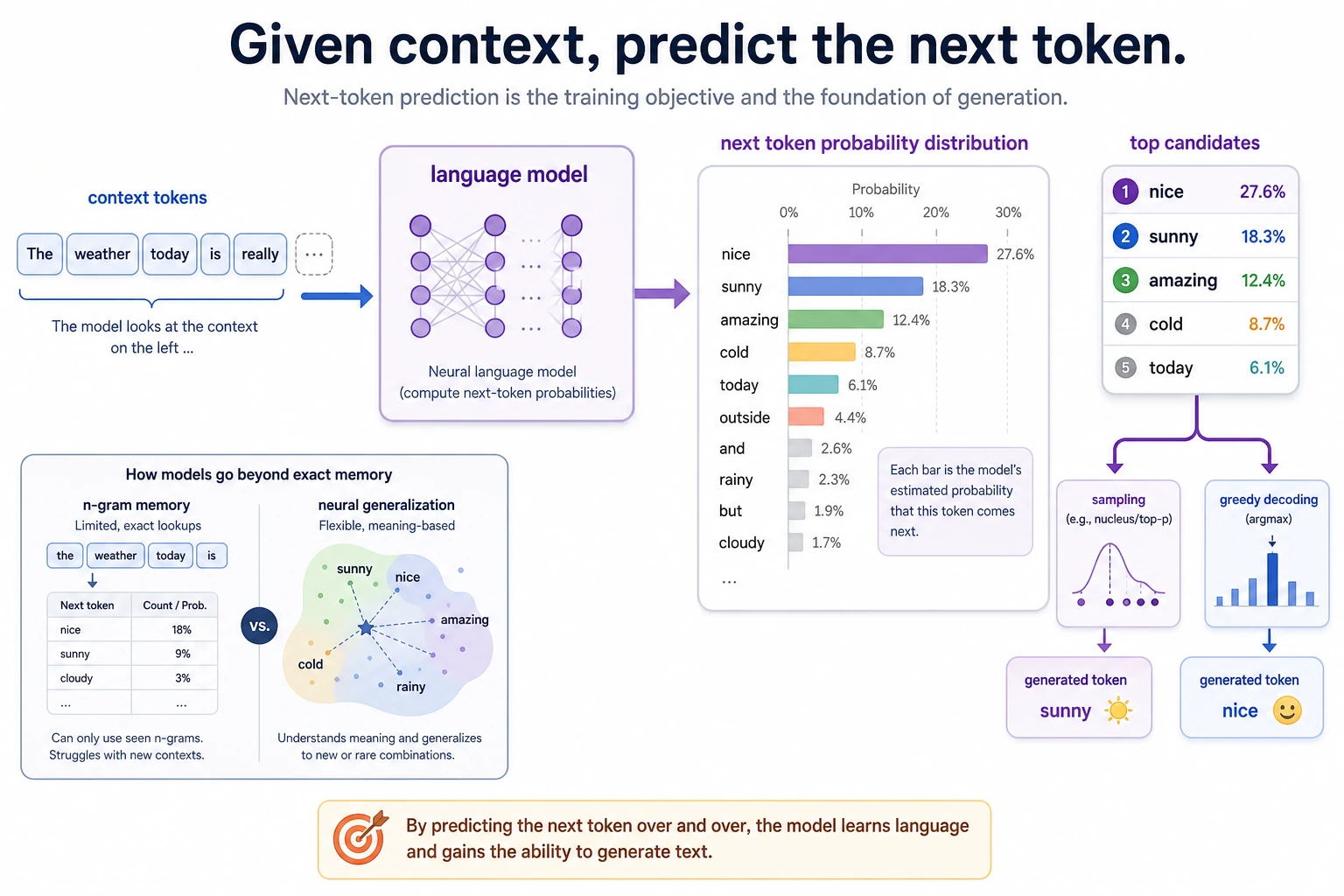
Don’t understand language models as just “word chaining.” When reading the diagram, focus on the relationship between the previous context, the candidate token probability distribution, and sampling/selection: many generation abilities in large models grow out of this training objective.
The term “language model” will appear again and again later. If you don’t first build the most basic intuition, it’s very easy to end up with only buzzwords when learning large models later.
The goal of this lesson is to make one thing clear first:
At its core, a language model predicts: given the previous text, what is most likely to come next.
It may look like a simple task on the surface, but many later capabilities grow from it.
Learning Objectives
- Understand the most basic task objective of language models
- Understand the continuity between n-gram language models and modern neural language models
- Build intuition for “predicting the next token” through a runnable example
- Understand why language models become the shared foundation of later large models
What exactly does a language model learn?
The most basic form
In one sentence:
- Given the previous text, predict the next token
For example:
- “I love” -> the next word might be
AI,you,Python
Why does this task look simple but powerful?
Because to do it well, the model must gradually learn:
- lexical collocations
- grammatical structure
- common semantic relationships
- some world knowledge
In other words, although “predict the next token” is a simple objective, it pushes the model to learn many language patterns underneath.
An analogy
A language model is like playing a word chain game, but not just any continuation—it has to continue in a way that is:
- like human language
- like the current context
- like a reasonable extension
Start with the n-gram intuition
What is an n-gram language model?
You can first understand it as:
- only looking at a very short history
- using statistical frequency to predict what comes next
For example, bigram:
- only looks at the previous 1 word
trigram:
- only looks at the previous 2 words
What are the advantages of this method?
- intuitive
- interpretable
- easy to get started with
Its limitations are also obvious
- cannot see long-distance dependencies
- very sparse
- weak generalization
But it is very suitable for helping beginners build the first layer of intuition about language models.
Run a simple bigram example first
from collections import defaultdict, Counter
corpus = [
"I love AI",
"I love Python",
"You love NLP",
]
stats = defaultdict(Counter)
for sent in corpus:
toks = sent.split()
for a, b in zip(toks[:-1], toks[1:]):
stats[a][b] += 1
print(dict(stats))
Expected output:
{'I': Counter({'love': 2}), 'love': Counter({'AI': 1, 'Python': 1, 'NLP': 1}), 'You': Counter({'love': 1})}
Read this as a tiny next-token table: after I, the next token was love twice; after love, three different next tokens appeared once each.
What is the most important value of this code?
It peels back the lowest-level logic of a language model:
- after seeing a word
- how many times each possible next word appeared in the training corpus
Why is this already like a “language model”?
Because it is already doing:
- conditional probability estimation
For example, after seeing:
love
the following words:
AIPythonNLP
can each have different probabilities.
How do we move from statistical models to neural language models?
The core task has not changed
Although model architectures become more and more complex later, one important fact remains:
- the objective function is often still “predict the next token”
What changes is the representation and generalization
Neural language models no longer just look up a frequency table, but instead:
- represent tokens as vectors
- model context with neural networks
This allows them to:
- see longer histories
- learn more abstract patterns
- generalize better to unseen combinations
A simplified example of a “prediction distribution”
import math
scores = {
"AI": 2.0,
"Python": 1.5,
"NLP": 0.8,
}
def softmax(score_dict):
exps = {k: math.exp(v) for k, v in score_dict.items()}
total = sum(exps.values())
return {k: round(v / total, 4) for k, v in exps.items()}
print(softmax(scores))
Expected output:
{'AI': 0.5242, 'Python': 0.3179, 'NLP': 0.1579}
The model does not have to choose immediately. It first produces a probability distribution, then a decoding rule can choose, sample, or rank candidate next tokens.
This is not a complete neural network, but it already expresses one key idea:
- the model does not output just one word
- it outputs a “probability distribution over the next word”
Why do language models become the common foundation of large models?
Because this objective is general enough
Whether you later do:
- conversation
- writing
- code generation
- summarization
many capabilities can grow out of “language continuation ability.”
Because it is well suited to large-scale self-supervised learning
You do not need human annotation for “what the next word is,” because the text itself naturally contains the label.
This means:
- massive text data
- self-supervised training
can be combined naturally.
This is also why the later path leads to GPT
Because autoregressive language modeling is:
- simple
- unified
- scalable
This path later became one of the important main lines of large language models.
The most common pitfalls
Misconception 1: a language model is only “good at continuing the next word”
This statement is superficially true, but it underestimates how much the model can be pushed to learn by this task.
Misconception 2: n-gram is useless, so there is no need to learn it
n-gram is very useful, because it lets you see for the first time what a language model is actually doing.
Misconception 3: if it can generate, then it understands language
Strong generation ability does not mean full understanding. That is also why later we still need to look at reasoning, alignment, and tool use.
Summary
The most important thing in this lesson is to form a stable judgment:
The most basic task of a language model is to predict the next token given the previous context; and this seemingly simple objective is exactly what forms the foundation for many capabilities of later large models.
Once this main thread is clear, you will naturally find it much easier to understand GPT, pretraining, and generative models later.
Exercises
- Add a few more sentences to the corpus and see how
statschanges. - Why can we say bigram is simple, yet it already captures the core of a language model?
- Explain in your own words: why is a language model naturally suited to large-scale self-supervised training?
- Think about it: why can the ability to “continue the next word” eventually grow into conversation and writing abilities?