11.3.4 Text Classification Practice
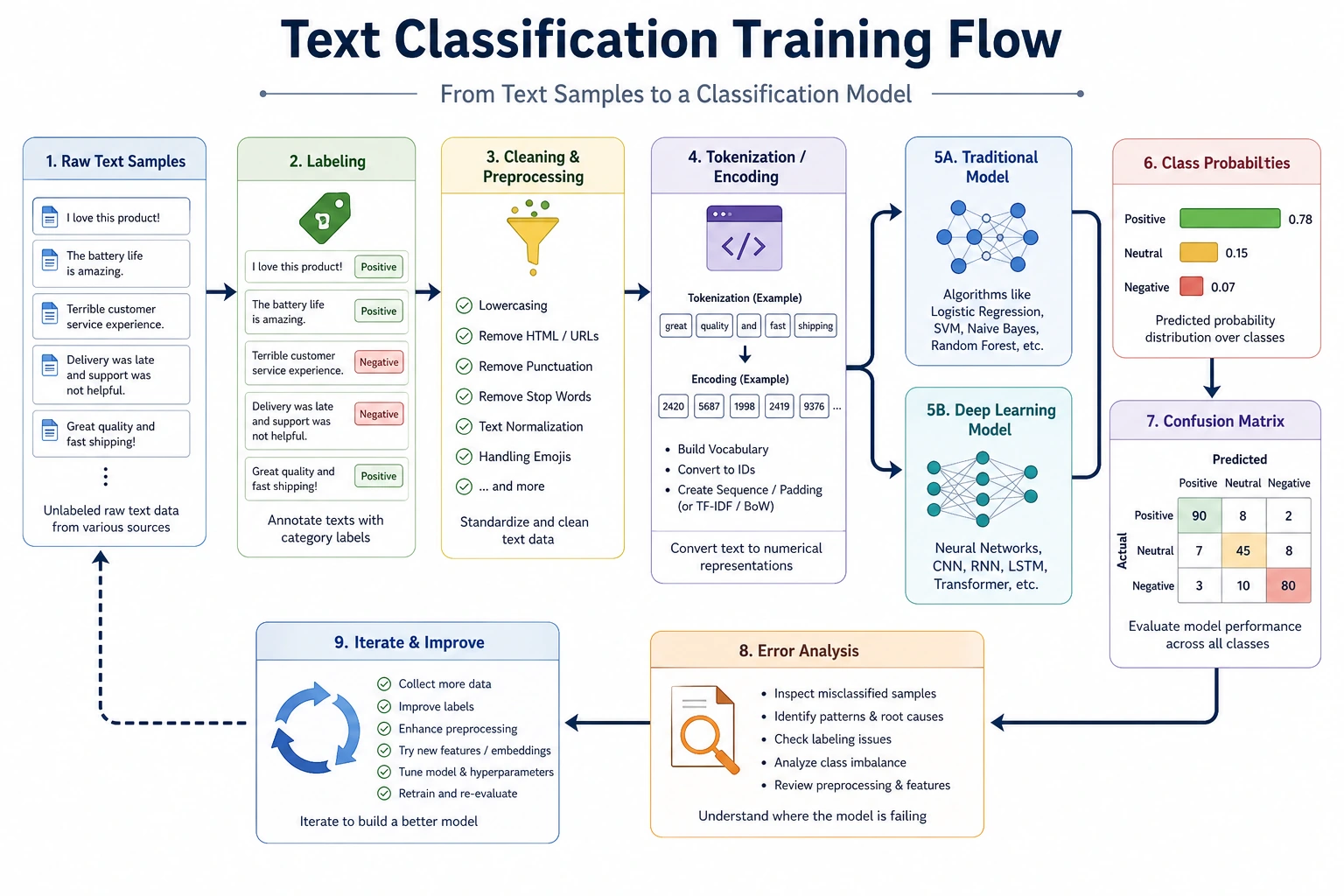
The previous two lessons covered:
- Traditional text classification
- Deep learning text classification
In this lesson, we will bring them back into a real project. In a real text classification project, the hard parts are usually not only the model, but also:
- How to define labels
- How to organize data
- How to compare baselines
- How to analyze errors
This lesson will walk through this closed loop with a small customer service intent classification task.
Learning Objectives
- Learn how to clearly define label boundaries for a text classification task
- Learn how to build a lightweight baseline that can explain its results
- Learn how to spot data or label issues from error cases
- Build a complete project skeleton through a runnable example
First, Define the Project Problem Clearly
Scenario
We will build a minimal customer service ticket intent classifier, with the target classes:
refundinvoicepassword
Why is this a good practice task?
Because it has all the essentials at once:
- Clear input: one user sentence
- Clear output: an intent class
- Easy-to-analyze errors: when it misclassifies, you can usually trace it back to words and label boundaries
The first key point is not the model, but the label boundaries
For example:
- “How long does it take for a refund to arrive?” is
refund - “When can an invoice be issued?” is
invoice - “What should I do if I forget my password?” is
password
This must be clear first.
Start with an Explainable Baseline
Here we will not use external dependencies. Instead, we will directly write a minimal keyword-counting baseline so you can see the full loop first.
from collections import Counter, defaultdict
import re
train_data = [
("How long does it take for a refund to arrive?", "refund"),
("How do I apply for a refund?", "refund"),
("When can an invoice be issued?", "invoice"),
("Where will the e-invoice be sent?", "invoice"),
("What should I do if I forget my password?", "password"),
("Where is the password reset entry?", "password"),
]
test_data = [
("How do I handle a refund?", "refund"),
("When will the e-invoice be issued?", "invoice"),
("How long does it take to reset a password?", "password"),
("Can I get a refund invoice?", "invoice"),
]
stop_words = {
"a",
"an",
"be",
"can",
"do",
"does",
"for",
"how",
"i",
"if",
"is",
"it",
"long",
"my",
"should",
"take",
"the",
"to",
"what",
"when",
"where",
"will",
}
def tokenize(text):
words = re.findall(r"[a-z]+", text.lower())
return [word for word in words if word not in stop_words]
class KeywordClassifier:
def __init__(self):
self.class_word_counts = defaultdict(Counter)
self.class_counts = Counter()
def fit(self, data):
for text, label in data:
self.class_counts[label] += 1
self.class_word_counts[label].update(tokenize(text))
def predict_one(self, text):
tokens = tokenize(text)
scores = {}
for label, word_counts in self.class_word_counts.items():
score = 0
for token in tokens:
score += word_counts[token]
scores[label] = score
return max(scores, key=scores.get), scores
def evaluate(self, data):
correct = 0
details = []
for text, gold in data:
pred, scores = self.predict_one(text)
correct += int(pred == gold)
details.append({"text": text, "gold": gold, "pred": pred, "scores": scores})
return correct / len(data), details
clf = KeywordClassifier()
clf.fit(train_data)
acc, details = clf.evaluate(test_data)
print("accuracy:", round(acc, 4))
for item in details:
print(item)
Expected output:
accuracy: 0.75
{'text': 'How do I handle a refund?', 'gold': 'refund', 'pred': 'refund', 'scores': {'refund': 2, 'invoice': 0, 'password': 0}}
{'text': 'When will the e-invoice be issued?', 'gold': 'invoice', 'pred': 'invoice', 'scores': {'refund': 0, 'invoice': 4, 'password': 0}}
{'text': 'How long does it take to reset a password?', 'gold': 'password', 'pred': 'password', 'scores': {'refund': 0, 'invoice': 0, 'password': 3}}
{'text': 'Can I get a refund invoice?', 'gold': 'invoice', 'pred': 'refund', 'scores': {'refund': 2, 'invoice': 2, 'password': 0}}
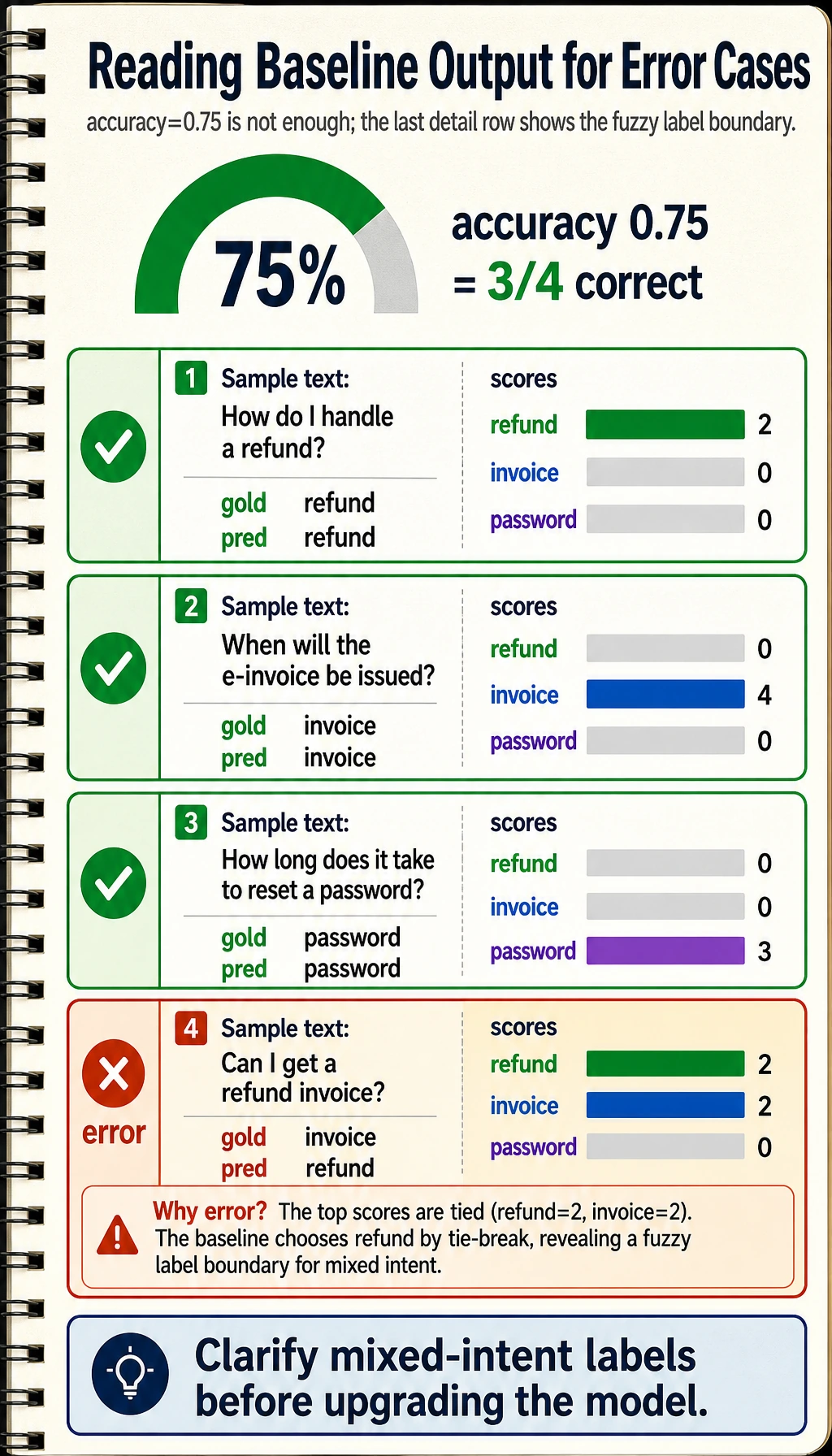
The last sample is intentionally ambiguous. The baseline sees both refund and invoice, ties on score, and chooses the first matching class. That gives you a useful error case to inspect instead of pretending the baseline is perfect.
Why is this example valuable?
Because it includes the 4 core pieces of a classification project:
- Training set
- Test set
- A runnable baseline
- Detailed outputs
Why do we intentionally start with a “very simple” baseline?
Because it makes it easier for you to:
- Understand why predictions are made
- Find data issues
- Know exactly what a stronger model improves on
In a Text Classification Project, the Most Valuable Part Is Not the Final Score, but Error Analysis
Start by looking at the overall accuracy
Accuracy tells you:
- Whether the current system is roughly working
But the real insight comes from per-sample details
You need to check:
- Which types of samples are most likely to be misclassified
- Whether the mistake comes from similar wording, overlapping labels, or insufficient training data
A simple error analysis function
details = [
{"text": "How do I handle a refund?", "gold": "refund", "pred": "refund", "scores": {"refund": 2, "invoice": 0, "password": 0}},
{"text": "When will the e-invoice be issued?", "gold": "invoice", "pred": "invoice", "scores": {"refund": 0, "invoice": 4, "password": 0}},
{"text": "How long does it take to reset a password?", "gold": "password", "pred": "password", "scores": {"refund": 0, "invoice": 0, "password": 3}},
{"text": "Can I get a refund invoice?", "gold": "invoice", "pred": "refund", "scores": {"refund": 2, "invoice": 2, "password": 0}},
]
def error_cases(details):
return [item for item in details if item["gold"] != item["pred"]]
errors = error_cases(details)
print("errors:", errors)
Expected output:
errors: [{'text': 'Can I get a refund invoice?', 'gold': 'invoice', 'pred': 'refund', 'scores': {'refund': 2, 'invoice': 2, 'password': 0}}]
This tells you the next practical action: clarify whether “refund invoice” belongs to billing, refunds, or a separate mixed-intent label before upgrading the model.
If there are many errors, you should first ask:
- Are the class boundaries too vague?
- Is the training data imbalanced?
- Is the keyword baseline simply not strong enough?
When Should You Upgrade from Traditional Methods to Deep Methods?
When the main errors come from changes in semantic expression
For example:
- The sentence does not contain keywords that commonly appear in training
- But the meaning is actually the same class
When you find that bag-of-words features are no longer enough
For example:
- Sentences are longer
- Negation and context matter more
- Class boundaries are more subtle
But keep the baseline before upgrading
The baseline is very important because it helps you answer:
- What exactly did the deep model improve?
How Should a Project Loop Be Presented?
Task definition
First, make it clear:
- What is the input?
- What is the output?
- How are the labels defined?
Baseline
Explain:
- What minimal method was used
- Why it was chosen
Evaluation and error analysis
At minimum, show:
- Accuracy
- Several typical success cases
- Several typical failure cases
Next optimization directions
For example:
- Expand the data
- Introduce TF-IDF + a linear model
- Then upgrade to embeddings / deep models
Common Mistakes
Mistake 1: Using the most complex model from the start
This can easily make you lose your judgment of the task itself.
Mistake 2: Only looking at the overall accuracy
Without checking detailed errors, it is hard to improve in a meaningful way.
Mistake 3: Vague label definitions
Once labels are vague, even a stronger model will learn unstable patterns.
Summary
The most important thing in this lesson is to build a project habit:
In a text classification project, the first thing to get right is the label boundaries, the explainable baseline, and error analysis—not jumping straight to the most complex model.
Once this habit is established, you will be much more stable when working on more complex NLP projects later.
Exercises
- Add a new category to the example, such as
shipping, and expand the training samples. - Use the error details to see which predictions are most easily confused, and guess why.
- In what situations would you decide to upgrade from this keyword baseline to a deep model?
- If the label definitions themselves are vague, would you change the model first or the data first? Why?