10.5.1 Advanced Vision Roadmap: OCR, Face, Video, 3D
Advanced vision is not a list of model names. It is a set of application directions built on the same visual foundation: more complex inputs, outputs, constraints, and risks.
See the Direction Map First
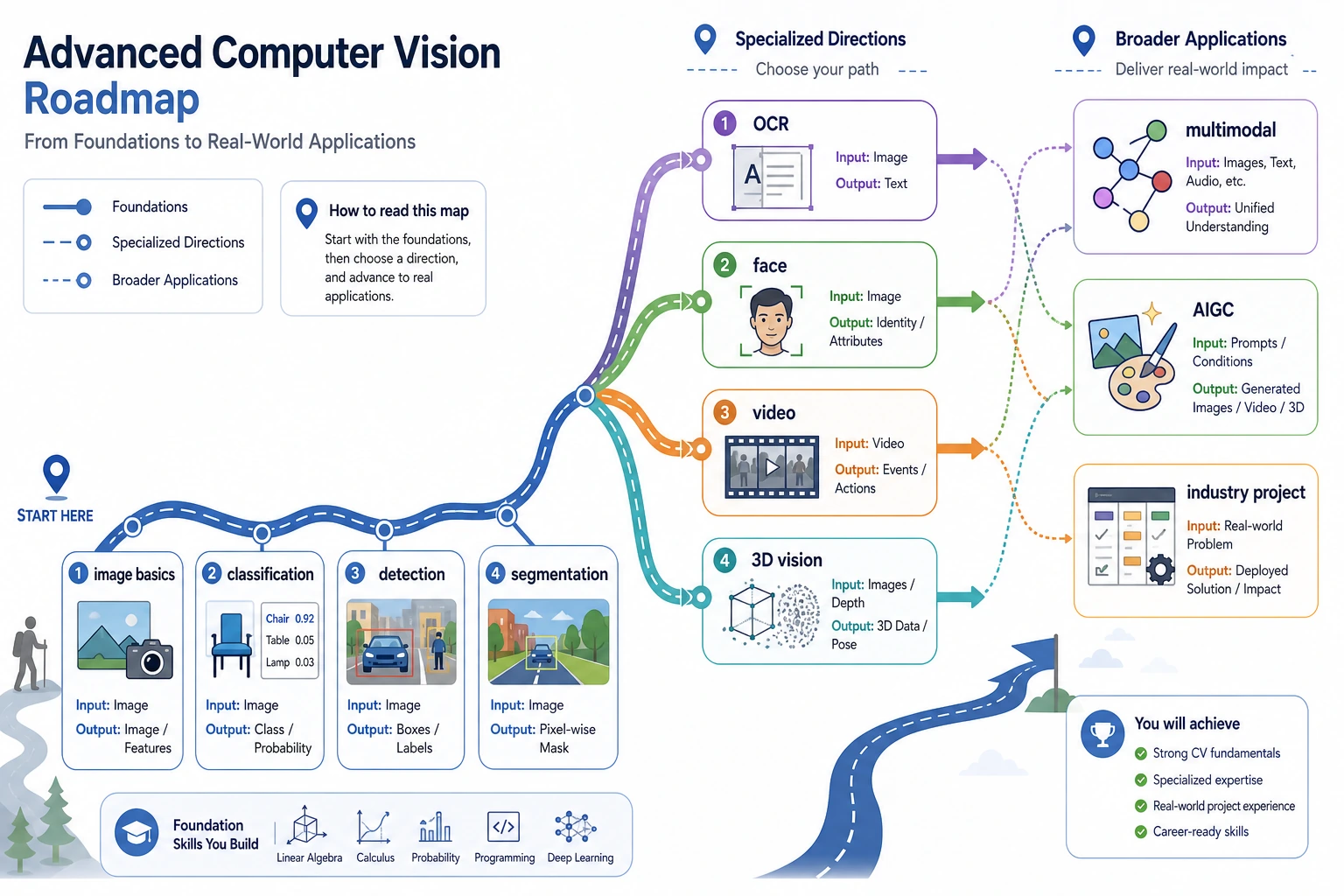

![]()
OCR fits documents, face recognition fits identity-sensitive scenarios, video fits time and motion, and 3D vision fits spatial structure.
Run a Direction Choice Check
Pick one direction instead of trying all four shallowly.
requirement = {
"input": "screenshot",
"needs_text": True,
"needs_identity": False,
"needs_time": False,
"needs_depth": False,
}
if requirement["needs_text"]:
direction = "OCR"
elif requirement["needs_identity"]:
direction = "Face"
elif requirement["needs_time"]:
direction = "Video"
elif requirement["needs_depth"]:
direction = "3D"
else:
direction = "Classification or detection"
print("direction:", direction)
print("first_output:", "text with layout")
Expected output:
direction: OCR
first_output: text with layout
For face, surveillance, medical, or identity projects, write privacy and usage boundaries before showing results.
Learn in This Order
| Step | Direction | Practice Output |
|---|---|---|
| 1 | OCR | Extract text, layout, fields, confidence, failure samples |
| 2 | Face | Detect faces, explain threshold, privacy, and bias risks |
| 3 | Video | Track events across frames and record temporal failures |
| 4 | 3D vision | Explain depth, point cloud, geometry, and sensor assumptions |
Pass Check
You pass this chapter when you choose one direction, define input/output, run a minimum project, and document failure cases plus usage boundaries.