11.4.3 HMM, CRF, and the Historical Thread of Sequence Labeling
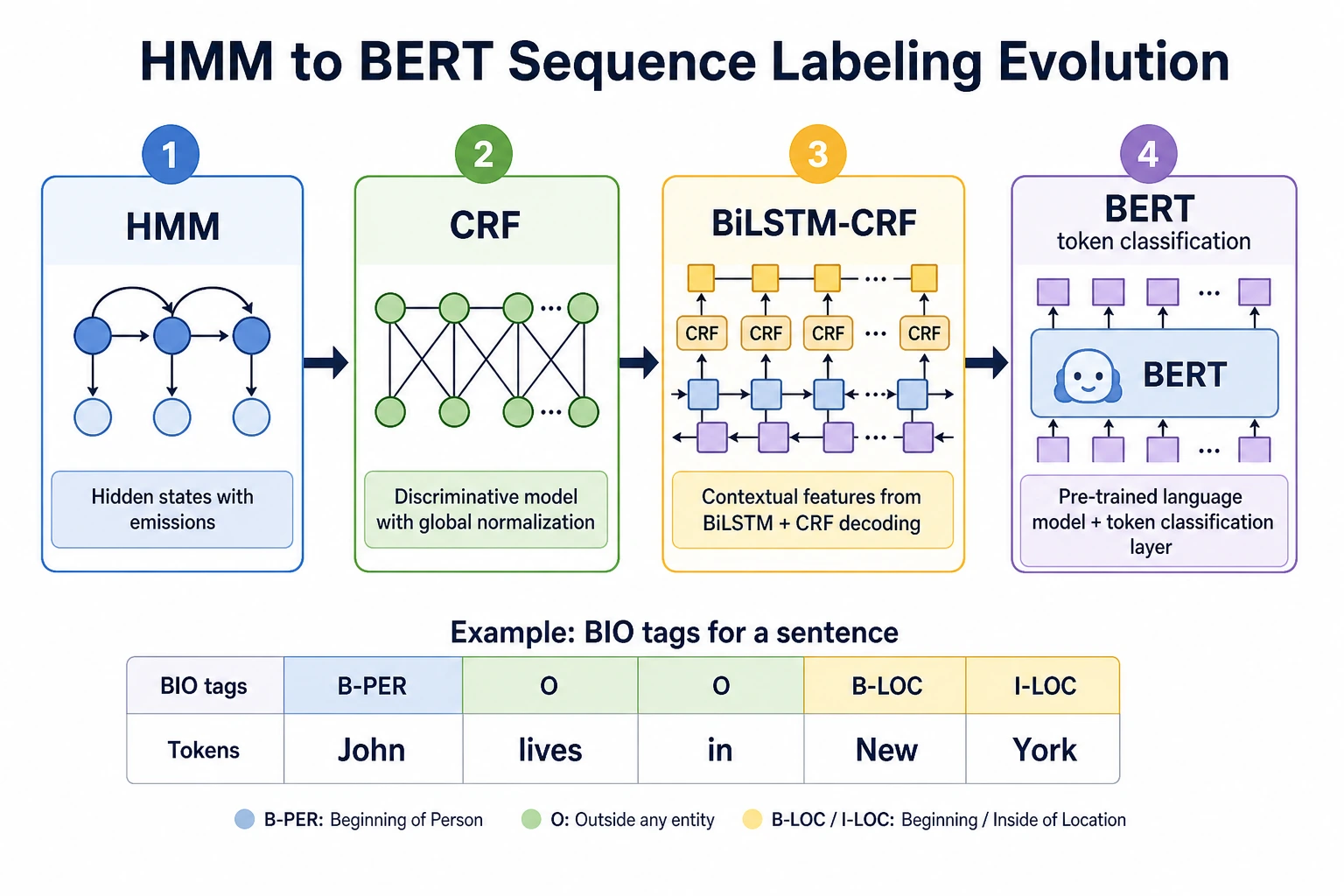
If you only look at modern BERT token classification, it is easy to think that sequence labeling is just “classifying each token.”
But in the history of NLP, this line of development started much earlier:
HMM first turned part-of-speech tagging into a statistical sequence problem, CRF strengthened the constraints between labels, BiLSTM-CRF added contextual representations, and BERT made contextual representations even stronger.
Where is the real difficulty in sequence labeling?
Sequence labeling does not assign one label to the whole sentence. Instead, it assigns a label to each position.
For example, named entity recognition:
Jobs founded Apple
B-PER O B-ORG
The difficulty is that the label at each position is not completely independent.
For example:
I-PERusually cannot appear at the beginning of a sentence out of nowhereB-ORGmay be followed byI-ORG- Chinese word segmentation, part-of-speech tagging, and NER all depend on context
So this historical line has always been trying to solve the same problem:
How can we look at the current token, the surrounding context, and still make the whole label sequence reasonable?
HMM: the classic starting point of early statistical sequence modeling
You can think of HMM as a model that “generates observed words from hidden states.”
In part-of-speech tagging:
- Hidden states: part-of-speech tags, such as noun, verb, adjective
- Observations: the actual words that appear
It asks two questions:
| Question | Name in HMM |
|---|---|
| Which part of speech is more likely to follow another part of speech? | Transition probability |
| Is a certain word more likely to be generated by a certain part of speech? | Emission probability |
The most classic decoding method is Viterbi: instead of choosing the highest-probability tag at each position separately, it finds the most likely tag path for the whole sentence.
CRF: scoring the “entire label path” more directly
HMM is classic, but it has relatively strong generative assumptions. CRF is more like answering directly:
Given this sentence, which entire sequence of labels is the most reasonable?
This is very important for NER because there are constraints between labels.
For example:
B-PER -> I-PER reasonable
O -> I-PER usually unreasonable
The value of CRF is that it does not only ask whether “this token looks like an entity,” but also whether “the whole label chain is valid and smooth.”
BiLSTM-CRF: contextual representations + label constraints
Later, when deep learning entered NLP, BiLSTM was responsible for reading context, and CRF was responsible for choosing the overall label path.
You can understand it as a division of labor:
| Module | Responsibility |
|---|---|
| Embedding | Turn words into vectors |
| BiLSTM | Look at both left and right context at the same time |
| CRF | Choose the most reasonable label sequence |
This is why many early NER systems used BiLSTM-CRF.
After BERT, is HMM/CRF still worth learning?
Yes. The reason is not that you must manually implement HMM in a project, but that:
- HMM helps you understand “sequence states” and “path decoding”
- CRF helps you understand “constraints between labels”
- BiLSTM-CRF helps you understand “contextual representations + structured output”
- BERT token classification helps you understand that “stronger representations can replace part of feature engineering”
In modern projects, BERT can often produce very strong token representations directly. But when the data is small, label rules are strict, or boundaries are easy to get wrong, the CRF idea is still valuable.
Mapping historical milestones to course chapters
| Historical milestone | Problem it solved | Corresponding course chapter |
|---|---|---|
| HMM part-of-speech tagging | Model label sequences with hidden states and transition probabilities | 4.5 This section, 4.2 Sequence labeling tasks |
| Viterbi decoding | Find the most likely label path for the whole sentence | 4.5 This section, 4.3 BiLSTM + CRF |
| CRF | Model the entire label path directly given the input | 4.3 BiLSTM + CRF |
| BiLSTM-CRF | Combine contextual representations with label constraints | 4.3 BiLSTM + CRF, 4.4 NER practice |
| BERT token classification | Use pretrained contextual representations for token-level tasks | 6.3 BERT, Chapter 7 LLM foundations |
A minimal intuitive example
The following is not a complete HMM. It is only meant to help you understand the feeling of “transition constraints”:
labels = ["B-PER", "I-PER", "O"]
allowed = {
"B-PER": ["I-PER", "O"],
"I-PER": ["I-PER", "O"],
"O": ["B-PER", "O"],
}
path = ["O", "I-PER"]
if path[1] not in allowed[path[0]]:
print("This label path is unreasonable")
else:
print("This label path is acceptable")
Expected output:
This label path is unreasonable
I-PER should continue an existing person entity. Starting it directly after O breaks the label grammar, which is exactly the kind of constraint HMM/CRF-style thinking makes visible.
What this code wants to show is: sequence labeling is not something where each token is judged independently; labels also have their own “grammar.”
The intuition you should have after finishing this section
The history of sequence labeling did not start with BERT. It roughly went through:
HMM / Viterbi -> CRF -> BiLSTM-CRF -> BERT token classification
Each generation was answering the same question:
How can we make each position’s label fit the context while also making the entire label sequence reasonable?