7.1.4 Pretrained Language Models at a Glance
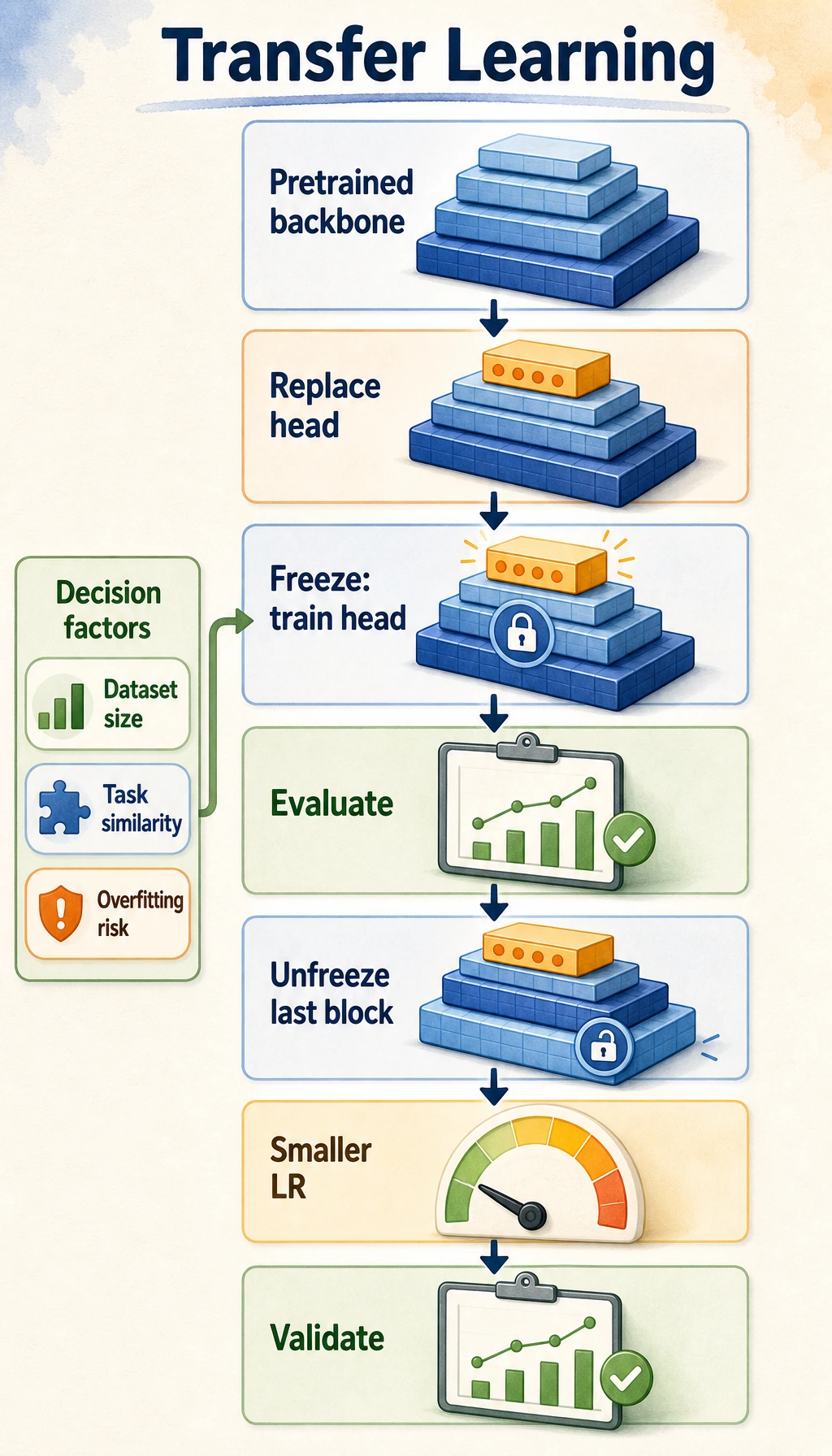
A pretrained model is not a magic model that knows your business. It is a reusable language foundation. Your job is to decide the cheapest reliable way to adapt that foundation to the task.
The Mental Model
Before pretraining became common, every NLP task often needed its own model and data pipeline. Modern NLP starts differently:
large general corpus -> pretrained foundation -> task adaptation -> product behavior
The foundation has already learned useful language patterns. Your task usually needs one of these adaptations:
- prompt the model better;
- retrieve missing knowledge with RAG;
- train a small task head;
- fine-tune with LoRA or full updates;
- evaluate and guardrail the behavior.
What Pretraining Gives You
Pretraining usually gives three practical assets:
| Asset | What it means | Example use |
|---|---|---|
| reusable representations | text already maps to useful hidden states | classification, ranking, retrieval |
| reusable generation ability | the model can continue or transform text | chat, writing, code generation |
| reusable language priors | grammar, common patterns, frequent facts | fewer examples needed downstream |
It does not guarantee current knowledge, correct business policy, or safe behavior. Those still need data, retrieval, evaluation, and deployment controls.
Lab: Shared Foundation + Two Task Heads
This toy example does not train a real LLM. It shows the structure: one shared encoder, two different heads.
from math import exp
word_vectors = {
"refund": [0.9, 0.8, 0.1],
"order": [0.8, 0.7, 0.2],
"password": [0.1, 0.2, 0.9],
"reset": [0.1, 0.1, 0.95],
"great": [0.7, 0.2, 0.1],
"bad": [0.2, 0.8, 0.1],
}
def encode(text):
tokens = text.lower().split()
valid = [word_vectors[token] for token in tokens if token in word_vectors]
dim = len(valid[0])
return [sum(vec[i] for vec in valid) / len(valid) for i in range(dim)]
def dot(a, b):
return sum(x * y for x, y in zip(a, b))
def softmax(scores):
exps = [exp(score) for score in scores]
total = sum(exps)
return [value / total for value in exps]
intent_head = {
"refund_intent": [1.0, 0.9, 0.1],
"password_intent": [0.1, 0.2, 1.0],
}
sentiment_head = {
"positive": [1.0, 0.2, 0.0],
"negative": [0.1, 1.0, 0.0],
}
def classify(vector, head):
labels = list(head.keys())
scores = [dot(vector, head[label]) for label in labels]
probs = softmax(scores)
best = max(zip(labels, probs), key=lambda item: item[1])
rounded = dict(zip(labels, [round(prob, 3) for prob in probs]))
return best, rounded
for text in ["refund order", "reset password"]:
vector = encode(text)
best, probs = classify(vector, intent_head)
print("intent:", text, "->", best, probs)
for text in ["great refund", "bad refund"]:
vector = encode(text)
best, probs = classify(vector, sentiment_head)
print("sentiment:", text, "->", best, probs)
Expected output:
intent: refund order -> ('refund_intent', 0.7604230019887309) {'refund_intent': 0.76, 'password_intent': 0.24}
intent: reset password -> ('password_intent', 0.654188113761243) {'refund_intent': 0.346, 'password_intent': 0.654}
sentiment: great refund -> ('positive', 0.5793242521487495) {'positive': 0.579, 'negative': 0.421}
sentiment: bad refund -> ('negative', 0.5361866202317948) {'positive': 0.464, 'negative': 0.536}
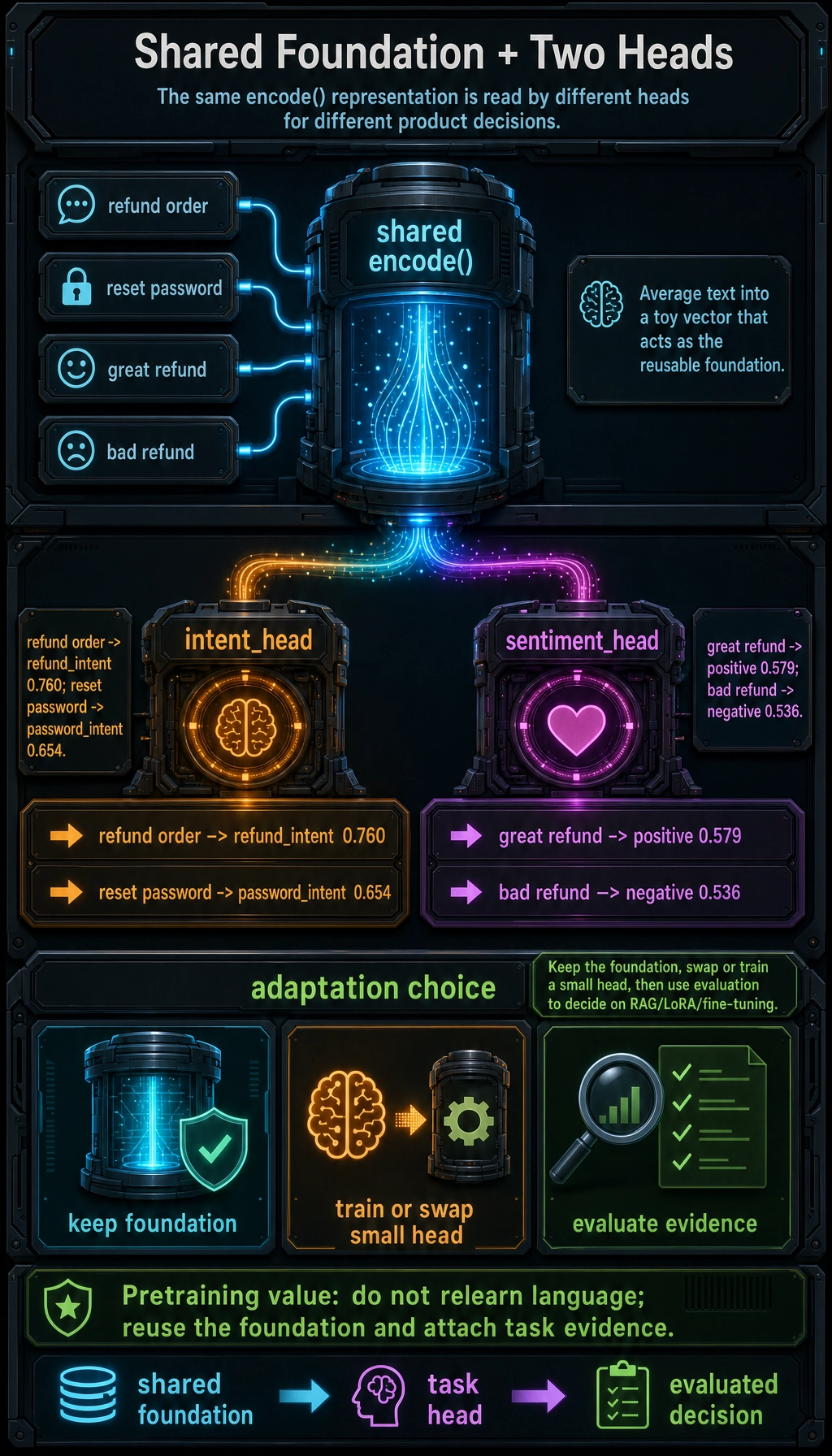
Read it like this:
encode()is the shared foundation.intent_headandsentiment_headare task-specific adapters.- The foundation is reused; only the final decision layer changes.
- Real models do this with millions or billions of learned parameters instead of hand-written vectors.
Main Model Families
| Family | Typical mask / flow | Strong at | Examples |
|---|---|---|---|
| Encoder-only | reads input bidirectionally | classification, extraction, matching, embeddings | BERT-style models |
| Decoder-only | predicts next token causally | chat, completion, code, tool use | GPT/LLaMA/Qwen-style models |
| Encoder-decoder | reads input, then generates output | translation, summarization, structured generation | T5/BART-style models |
Use this as a first filter, not a final rule. Modern systems often combine families with retrieval, tools, and serving constraints.
Choose an Adaptation Path
| Situation | Usually try first | Why |
|---|---|---|
| model already knows the task format | prompt improvement | fastest iteration |
| answer depends on private or fresh knowledge | RAG | update knowledge without changing weights |
| you need a stable label or score | task head / classifier | cheaper and easier to evaluate |
| style or domain behavior must shift | LoRA / PEFT | changes behavior with manageable cost |
| task is deeply specialized and data is strong | full fine-tuning | maximum flexibility, highest risk/cost |
The decision is engineering, not ideology. Choose the smallest change that passes evaluation.
Common Failure Modes
- Pretraining data mismatch: the model learned broad language, not your exact policy.
- Stale knowledge: the model may not know recent facts.
- Contamination: benchmark or test data may appear in training-like corpora.
- Over-adaptation: fine-tuning can improve one behavior while damaging others.
- Evaluation gaps: a demo prompt can look good while edge cases fail.
Exercises
- Add a
topic_headto the lab with labelsaccount_topicandcommerce_topic. - Change the vector for
bad. How does sentiment confidence change? - For a support bot with private policies, would you start with prompt, RAG, task head, or fine-tuning? Explain.
- List two checks you would run before trusting a pretrained model in production.
- Explain why “bigger model” and “better task fit” are not the same thing.
Summary
Pretraining changes the workflow:
do not relearn language every time -> reuse a foundation -> adapt with evidence
Once you see that pattern, prompt engineering, RAG, fine-tuning, alignment, and agents all become different ways to steer the same reusable foundation.