9.1.6 From TD-Gammon to AlphaGo: How Reinforcement Learning Shaped Agents
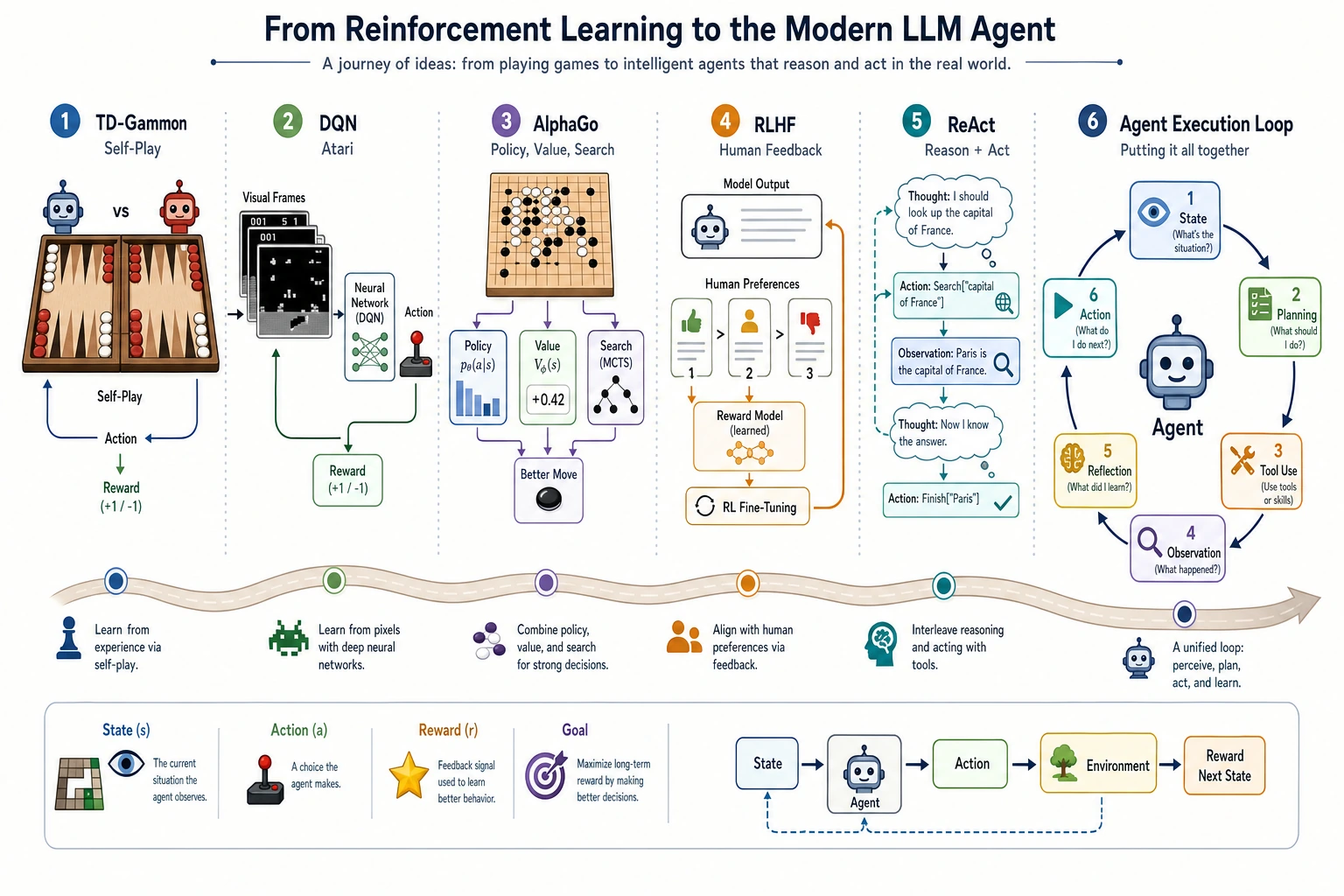
Modern LLM Agents are not the same as reinforcement learning, but the concept of an Agent is deeply connected to the history of reinforcement learning.
In this section, we will first focus on three stories:
TD-Gammon showed that machines can get stronger through self-play, DQN showed that deep networks can learn policies from pixels and rewards, and AlphaGo showed that combining learning, search, and planning can break through complex games.
Why does an Agent course need reinforcement learning history?
An Agent cares about:
- observing the state in an environment
- deciding the next action
- adjusting strategy based on feedback
- planning for long-term goals
This is highly similar to the basic problems in reinforcement learning.
| Reinforcement learning term | Agent system term |
|---|---|
| state | current context, task state |
| action | tool call, response, planning step |
| reward | user feedback, evaluation score, whether the task is complete |
| policy | decision strategy, rules for tool use |
| environment | external systems, knowledge base, browser, code repository |
So the history of reinforcement learning is not a side topic. It helps you understand why Agents need to care about feedback, planning, trial and error, and safety boundaries.
TD-Gammon: learning strategy from self-play
Around 1992, Gerald Tesauro’s TD-Gammon achieved a very strong level of play in backgammon using temporal-difference learning.
One especially attractive aspect was this:
The system did not merely imitate human game records, but improved its judgment through massive self-play and feedback from outcomes.
For beginners, you can think about it like this:
| Ordinary supervised learning | The TD-Gammon style |
|---|---|
| Every step has a standard answer | Often only the final win/lose result is available |
| The focus is on fitting labels | The focus is on learning a long-term strategy |
| Data is usually provided by humans | The system can generate experience through self-play |
This opened up an important idea for later reinforcement learning and game AI:
If a system can generate its own experience, it is not fully limited by manually labeled data.
DQN Atari: from pixels to actions
In 2015, DeepMind’s DQN achieved a breakthrough on Atari games. Its significance was that it combined deep learning and reinforcement learning:
- the input was game-screen pixels
- the output was the next action
- feedback came from the game score
It is like teaching a model to learn games starting from “looking at the screen.”
Game screen -> neural network -> action -> score feedback -> policy update
Its inspiration for modern Agents is:
- an Agent does not have to work only on static text
- an Agent can take continuous actions in an environment
- actions change the future state
- evaluation does not always appear immediately after each step
This is also why evaluating Agents is more difficult than evaluating ordinary question-answering systems.
AlphaGo: combining learning, search, and planning
In 2016, AlphaGo defeated Lee Sedol, and many people felt AI’s breakthrough very directly for the first time.
The key to AlphaGo was not “one neural network simply playing Go,” but a combination of multiple abilities:
| Capability | Role in AlphaGo | Inspiration for Agents |
|---|---|---|
| policy network | judges candidate next moves | generates possible actions |
| value network | estimates how good the position is | evaluates the current plan |
| Monte Carlo tree search | looks a few moves ahead to see the result | planning and search |
| self-play | generates more training experience | improves from feedback |
For Agents, this is extremely important:
Strong systems are often not the result of one model working alone, but of models, search, tools, feedback, and constraints working together.
What does this line have to do with LLM Agents?
The core of modern LLM Agents is not necessarily a reinforcement learning algorithm, but they inherit many of reinforcement learning’s problems:
| Classical RL problem | LLM Agent version |
|---|---|
| How should reward be defined? | How should task success, correct citations, and user satisfaction be measured? |
| Is exploration dangerous? | Could a tool call accidentally delete files or send the wrong request? |
| How should long-term goals be broken down? | How should multi-step tasks be planned, executed, and corrected? |
| How should the policy be evaluated? | Agent benchmarks, log replay, human review |
So when you later study ReAct, Plan-and-Execute, tool calling, and Agent evaluation, you can think of them as:
new implementations in the language-model era of the old problems of “action, feedback, and planning.”
Assigning historical milestones to course chapters
| Historical milestone | Problem it solved | Corresponding course chapter |
|---|---|---|
| TD-Gammon | Learning strategy from self-play and long-term feedback | 9.1 Agent historical background, 9.2 reasoning and planning |
| DQN / Atari | Deep networks learning actions from environmental feedback | 9.8 Agent evaluation, safety, and environment interaction |
| AlphaGo | Combining learning, search, and planning into a strong system | 9.2 planning, 9.7 multi-Agent / complex systems |
| RLHF | Adjusting model behavior using human preferences | Chapter 7 alignment, 9.8 safety evaluation |
| ReAct | Letting the model alternate between reasoning and acting | 9.2 ReAct, 9.3 tool calling |
The intuition you should have after this section
An Agent is not just “letting the model improvise.” It is more like a system that constantly balances the following:
- goals
- actions
- environment
- feedback
- planning
- safety constraints
The stories of TD-Gammon, DQN, and AlphaGo tell us: truly strong intelligent systems are usually not just good at answering questions—they can act in an environment and adjust their strategy based on feedback.